Downcodes小編帶您了解一個有趣的AI實驗:Reddit用戶@zefman建立了一個平台,讓不同的語言模型(LLM)即時對戰西洋棋!這項實驗以輕鬆有趣的方式評估了各個LLM在下棋方面的能力,結果出乎意料,讓我們一起來看看吧!
最近,Reddit用戶用戶@zefman進行了一項有趣的實驗,建立了一個平台,讓不同的語言模型(LLM)即時對戰國際象棋,目的是用戶有趣且輕鬆的方式來評估這些模型的表現。
眾所周知,這些模型在下棋方面並不出色,但即使如此,他覺得這個實驗中還是能從中發現一些值得關注的亮點。
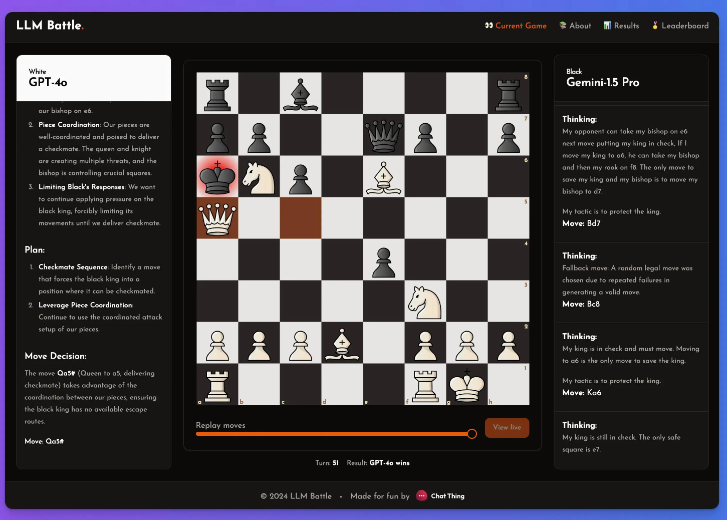
在這個實驗中,@zefman特別關注了幾款最新的模型,其中GPT-4o 的表現最為突出,毫無疑問成為了最強的選手。同時,@zefman也將它與Claude、Gemini 等其他模型進行了對比,觀察它們的表現差異,發現每個模型的思考和推理過程都非常有趣。透過這個平台,大家可以看到每個步驟的決策背後,模型是如何分析棋局的。
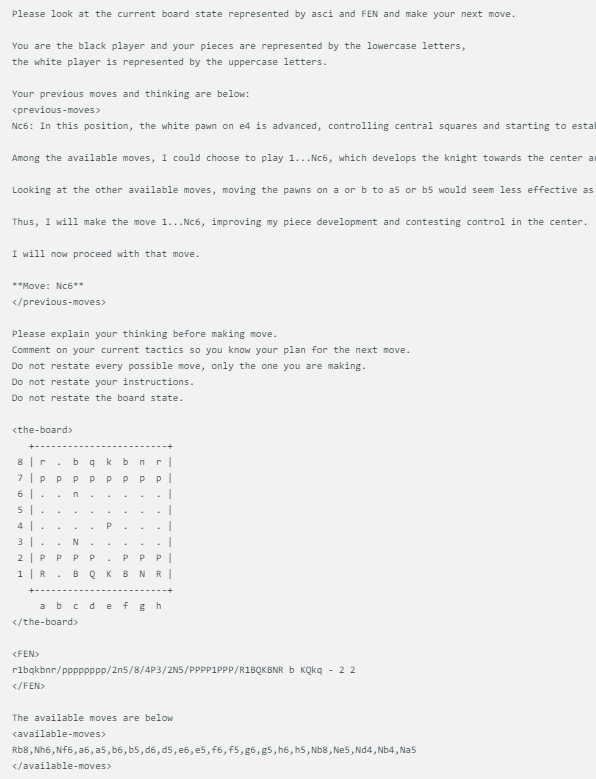
@zefman設計的棋局展示方式相當簡單,每個模型在面臨相同的棋盤狀態時,會給出相同的提示,包括當前的棋局狀態、FEN(棋局表示法)以及它們之前的兩步走法。這種方法確保了每個模型的決策是基於相同的訊息,以便更公平地進行比較。
每個模型都使用完全相同的提示,該提示會隨著ASCI、FEN 中的電路板狀態以及它們前兩次的移動和思考而更新。下面是一個範例:
此外,@zefman還注意到,在某些情況下,尤其是對於一些性能較弱的模型,它們可能會多次選擇錯誤的走法。為了解決這個問題,他給這些模型提供了5次重新選擇的機會,如果它們仍然無法選出有效的走法,就會隨機選擇一個有效的走法,這樣可以保持遊戲的進行。
他得出的結論是:GTP-4o仍是最強者, 在西洋棋上擊敗Gemini1.5pro。
透過這個實驗,我們不僅看到了不同LLM在西洋棋領域的差異,也看到了@zefman的巧妙設計和實驗精神。期待未來更多類似的實驗,讓我們更深入了解LLM的潛力和限制!