Meta AI最新的專案Llama3引發廣泛關注,Downcodes小編將帶您深入了解其核心技術和未來發展方向。 Meta AI研究員Thomas Scialom近日接受採訪,分享了Llama3的研發細節,並對大型語言模型訓練中存在的問題提出了獨到的見解。他特別強調了合成資料在Llama3訓練中的重要作用,以及如何有效利用人類回饋來提升模型表現。本文將詳細解讀Llama3的訓練方法、應用領域以及未來的發展規劃,為讀者呈現一個全面而深入的視角。
Meta AI的研究員Thomas Scialom最近在一次訪談中分享了一些關於他們最新專案Llama3的見解。他直言不諱地指出,網路上大量的文字品質參差不齊,他認為在這些數據上進行訓練是一種資源浪費。因此,Llama3的訓練過程中並沒有依賴任何人類所寫的答案,而是完全基於Llama2產生的合成資料。
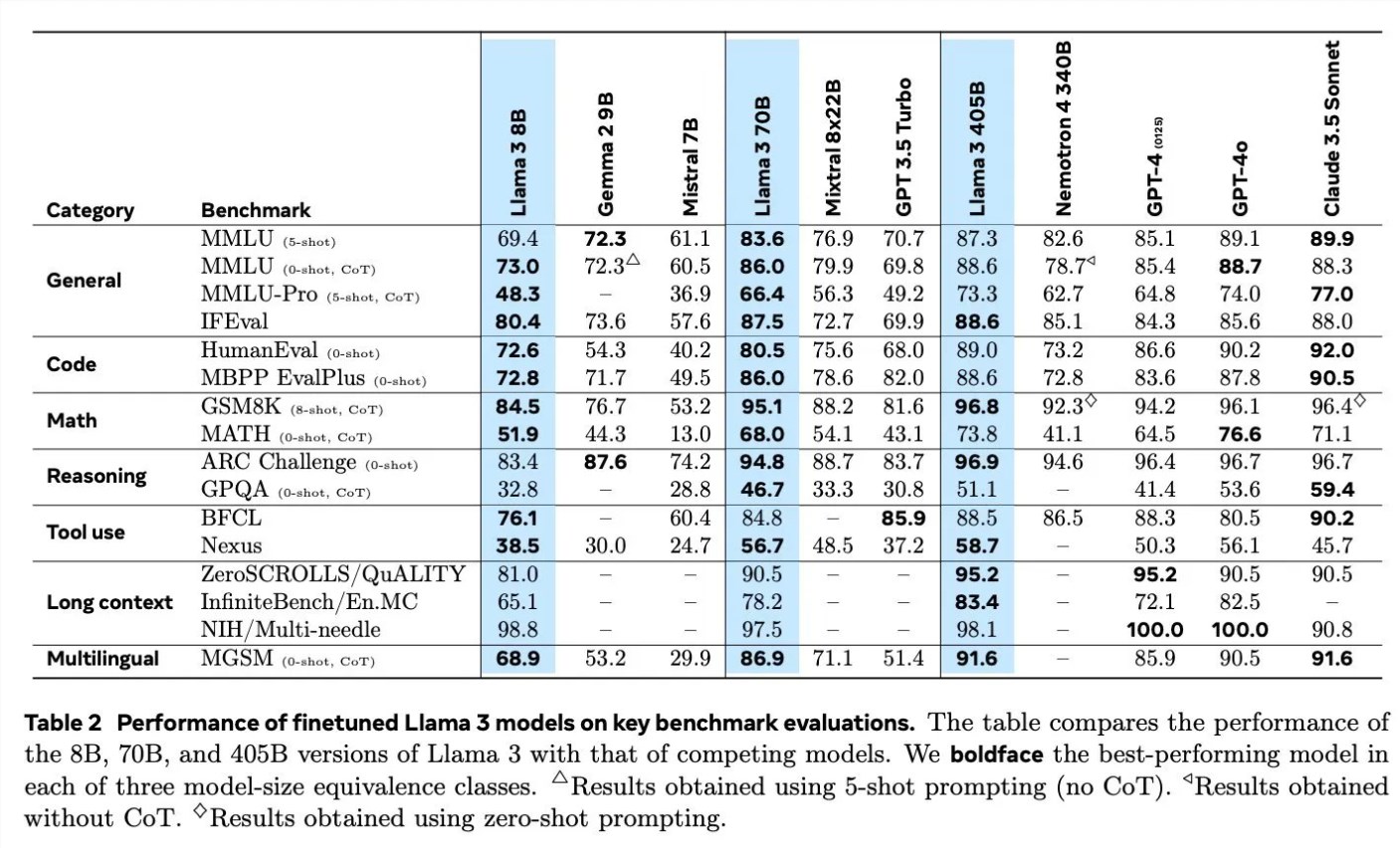
在討論Llama3的訓練細節時,Scialom詳細介紹了合成資料在不同領域的應用。例如,在程式碼生成方面,他們採用了三種不同的方法來產生合成數據,包括程式碼執行的回饋、程式語言的翻譯以及文件的反向翻譯。在數學推理方面,他們借鑒了「讓我們逐步驗證」的研究方法來進行資料生成。此外,Llama3也透過90%的多語言代幣繼續預訓練,以收集高品質的人類註釋,這在多語言處理上顯得尤為重要。
長文本處理也是Llama3的重點,他們依賴合成資料來處理長文本的問答、長文件摘要和程式碼庫推理。工具使用方面,Llama3在Brave搜尋、Wolfram Alpha和Python解釋器上進行了訓練,以實現單次、巢狀、並行和多輪函數呼叫。
Scialom也提到了強化學習與人類回饋(RLHF)在Llama3訓練中的重要性。他們廣泛利用人類偏好資料來訓練模型,並強調了人類在做出選擇(例如在兩首詩中選擇更喜歡的一首)方面的能力,而不是從零開始創作。
Meta已經在6月開始了Llama4的訓練,Scialom透露,Llama4的一個主要焦點將是圍繞智能體。此外,他還提到了多模態版本的Llama,這個版本將擁有更多的參數,並計劃在不久的將來發布。
Scialom的訪談揭示了Meta AI在人工智慧領域的最新進展和未來的發展方向,特別是在如何利用合成資料和人類回饋來提升模型效能方面。
透過Scialom的訪談,我們了解到Llama3在資料運用與模型訓練上的創新之處,以及Meta AI在大型語言模型領域的持續探索。 Llama3的成功經驗為未來人工智慧模式的研發提供了寶貴的參考,也預示著人工智慧技術將朝著更精準、更有效率的方向發展。 Downcodes小編期待Llama4及多模態Llama的發布,並持續關注Meta AI在人工智慧領域的突破性進展。