微軟近日發布的零樣本文字轉語音(TTS)模型VALLE-2,在語音合成領域取得了突破性進展,其合成語音品質達到了與人類同等水平,引發了廣泛關注。 Downcodes小編將對VALLE-2的技術重點、倫理考量及未來展望進行深入分析。
近日,微軟發布的零樣本文字轉語音(TTS)模型VALLE-2在科技界引起廣泛關注。這項突破性成果首次實現了與人類同等程度的語音合成,被認為是TTS領域的里程碑式進展。
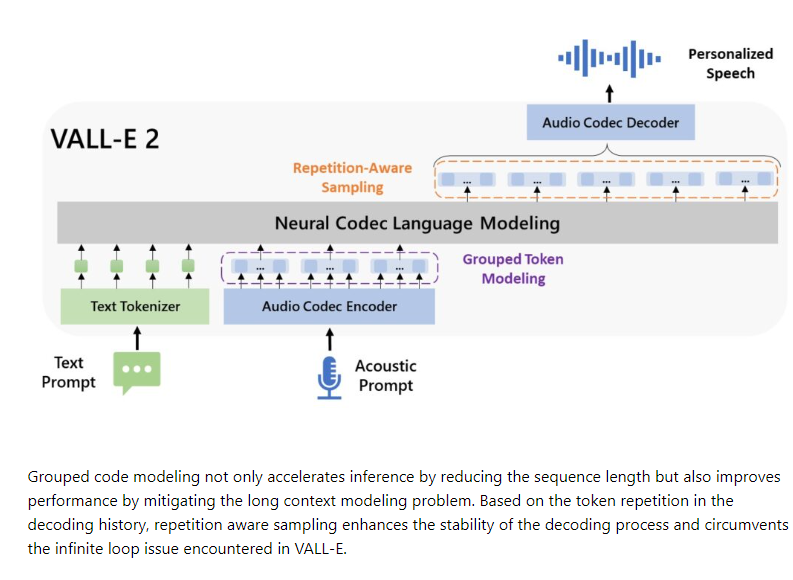
技術亮點與創新:
零樣本學習:VALLE-2只需一段簡短的陌生語音樣本,就能模仿相同的聲音說出任意文字內容,展現了驚人的即時模仿能力。
重複感知取樣:改進了隨機取樣方法,有效緩解了無限循環問題,提高了解碼穩定性。
分組程式碼建模:透過將編解碼器程式碼分組,減少了序列長度,加速了推理過程,同時提高了效能。
簡化的訓練資料需求:VALLE-2只需要簡單的語音-轉錄文字資料進行訓練,大大簡化了資料收集和處理流程。
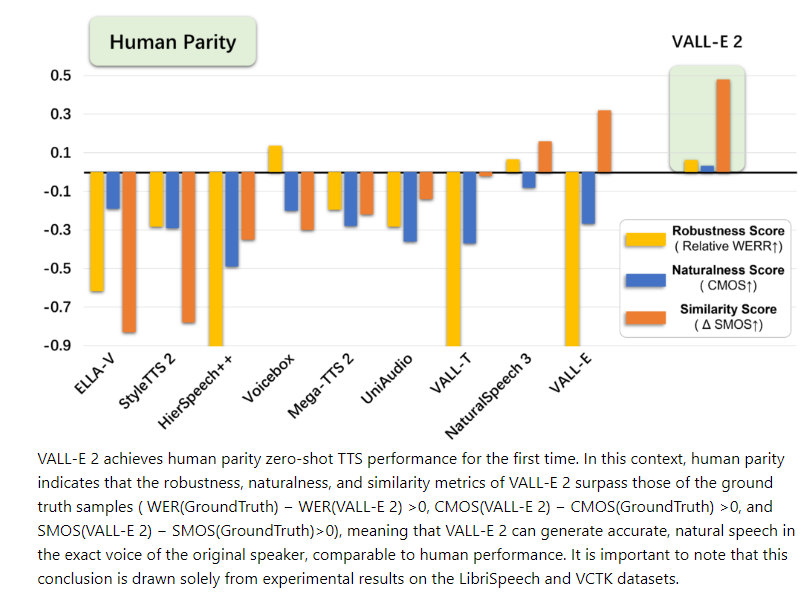
效能評估:在主觀評分(SMOS和CMOS)和客觀指標(SIM、WER和DNSMOS)上,VALLE-2不僅超越了前代模型VALLE,在某些方面甚至優於人類真實語音。
倫理考量與市場反應:
潛在風險:VALLE-2強大的語音模仿能力引發了對Deepfake技術濫用的擔憂。
微軟對此持謹慎態度,目前僅將VALLE-2定位為純研究項目,暫無產品化計畫。其在專案頁面和論文中進行了道德聲明,強調了合成語音檢測和授權機制的必要性。
部分用戶對微軟不發布可試用產品表示失望。業內人士推測微軟可能是在規避潛在風險和負面輿論。隨著技術成熟和市場競爭加劇,VALLE-2或類似技術的商業化應用可能只是時間問題。
技術局限與改進空間:
Demo限制:目前公開的演示樣本有限,難以全面評估模型性能。
口音適應:模型在處理非英美口音時的效果有待提升。
計算效率:儘管有所改進,但在推理速度方面仍有優化空間。
VALLE-2的出現標誌著零樣本TTS技術邁入了新紀元。它不僅展示了AI在語音合成領域的巨大潛力,也引發了關於技術倫理和責任使用的深入思考。隨著科技的進一步發展和完善,我們可以期待看到更多創新應用,同時也需要業界、監管機構和公眾共同努力,確保這項強大技術的負責任使用。未來,VALLE-2及類似技術很可能在語音助理、內容創作、教育訓練等領域帶來革命性變革,同時也將推動語音辨識和合成偵測技術的進步,以因應潛在的濫用風險。
專案地址:https://www.microsoft.com/en-us/research/project/vall-ex/vall-e-2/
總而言之,VALLE-2的出現是人工智慧領域的一大進步,但同時也提醒我們需謹慎對待這項技術,在享受其便利的同時,也要關注其潛在風險,共同探索其負責任的應用方式。期待未來VALLE-2及其相關技術能為人類帶來更多福祉。