Meta公司重磅發售!開源其最新大語言模型Llama 3.1 405B,參數量高達1280億,在多項任務中表現可與GPT-4媲美。歷經一年精心籌備,從專案規劃到最終審核,Llama 3系列模型終於與大眾會面。此次開源不僅包含模型本身,還包括其最佳化的預訓練資料處理、訓練後資料品質保證以及高效的量化技術,以降低運算需求,方便開發者使用。 Downcodes小編將為您詳細解讀Llama 3.1 405B的各項改進與亮點。
昨晚,Meta公司宣布開源其最新大語言模型Llama3.1 405B。這項重磅消息標誌著經過一年的精心籌備,從專案規劃到最終審核,Llama3系列模型終於與公眾見面。
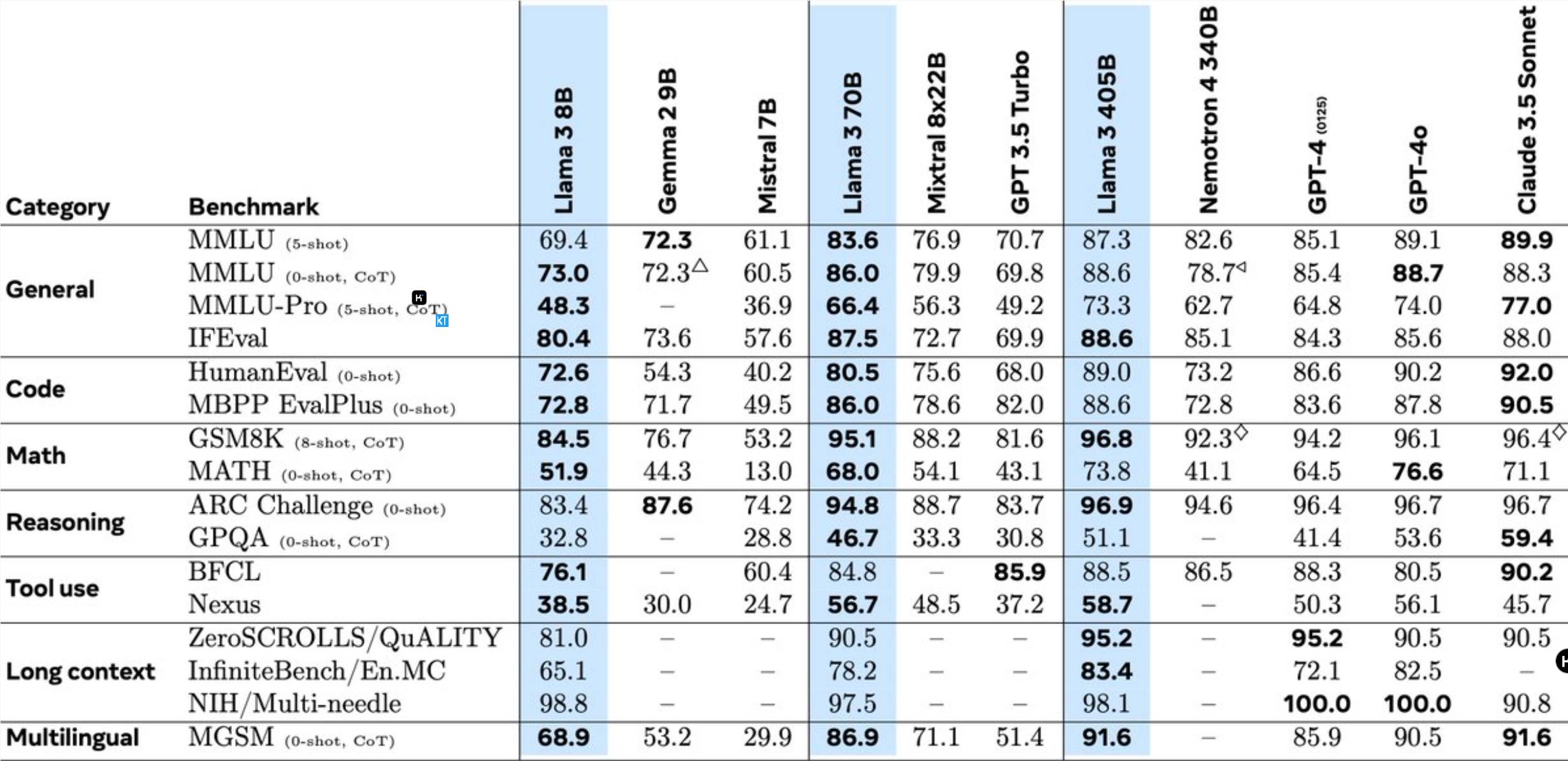
Llama3.1405B是具有1280億參數的多語言工具使用模型。此模型在8K上下文長度預訓練後,進一步透過128K上下文長度持續訓練而成。根據Meta的說法,這個模型在多項任務中的表現可與業界領先的GPT-4相媲美。
相較於先前的Llama模型,Meta在多個方面進行了最佳化:
405B模型的預訓練是一項巨大挑戰,涉及15.6兆個標記和3.8x10^25次浮點運算。為此,Meta優化了整個訓練架構,並呼叫了超過16,000塊H100GPU。
為支援405B模型的大規模生產推理,Meta將其從16位元(BF16)量化至8位(FP8),顯著降低了計算需求,使單一伺服器節點也能運行該模型。
此外,Meta利用405B模型提升了70B和8B模型的訓練後品質。在訓練後階段,團隊透過多輪對齊過程完善了聊天模型,包括監督式微調(SFT)、拒絕取樣和直接偏好最佳化。值得注意的是,大部分的SFT樣本都是使用合成資料產生。
Llama3還整合了圖像、視頻和語音功能,採用組合方法使模型能夠識別圖像和視頻,並支援語音互動。不過,這些功能仍在開發中,尚未正式發表。
Meta也更新了授權協議,讓開發者使用Llama模型的輸出來改進其他模型。
Meta的研究人員表示:能與業內頂尖人才一起在AI前沿工作,並公開透明地發布研究成果,是無比令人振奮的。我們期待看到開源模型帶來的創新,以及未來Llama系列模型的潛力!
這項開源舉措無疑將為AI領域帶來新的機會和挑戰,並推動大語言模型技術的進一步發展。
Llama 3.1 405B的開源,將極大推動大語言模型技術的進步,為AI領域帶來更多可能性。期待開發者們基於此模型創造出更多令人驚豔的應用程式!