崑崙萬維近日宣布其研發的兩款獎勵模型Skywork-Reward-Gemma-2-27B和Skywork-Reward-Llama-3.1-8B在RewardBench上取得優異成績,其中27B模型更是榮登榜首。這標誌著崑崙萬維在人工智慧領域,特別是獎勵模型研發方面取得了重大突破,為大語言模型訓練提供了新的技術支援。獎勵模型在強化學習中至關重要,它能夠引導模型學習,產生更符合人類偏好的內容。崑崙萬維的模型在資料選擇和模型訓練上具有獨特的優勢,這使得其在對話、安全性等方面表現出色,尤其是在處理困難樣本時展現出強大的能力。
崑崙萬維科技股份有限公司近日宣布,公司研發的兩款全新獎勵模型Skywork-Reward-Gemma-2-27B和Skywork-Reward-Llama-3.1-8B在國際權威的獎勵模型評估基準RewardBench上表現卓越,其中Skywork-Reward-Gemma-2-27B模型更是榮獲榜首,並得到了RewardBench官方的高度認可。
獎勵模型在強化學習中佔據核心地位,對智能體在不同狀態下的表現進行評估,並提供獎勵訊號指導智能體的學習過程,使其能夠在特定環境下做出最優選擇。在大語言模型的訓練中,獎勵模型的作用特別關鍵,有助於模型更準確地理解和產生符合人類偏好的內容。
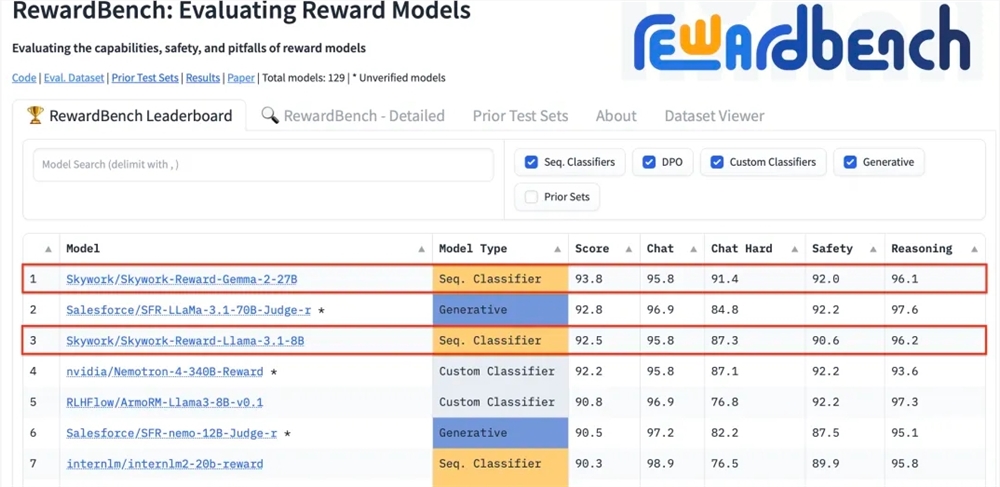
RewardBench是一個專門評估大語言模型中獎勵模型有效性的基準測試榜單,透過多項任務對模型進行綜合評估,包括對話、推理和安全性等領域。此榜單的測試資料集由提示詞、被選響應和被拒絕響應組成的三元組構成,用以測試獎勵模型是否能夠在給定提示詞的情況下,將被選響應正確地排在被拒絕響應之前。
崑崙萬維的Skywork-Reward模型透過精心挑選的偏序資料集和相對較小的基座模型進行開發,與現有獎勵模型相比,其偏序資料僅來自網路公開數據,並透過特定篩選策略獲得高品質的偏好資料集。這些數據涵蓋了廣泛的主題,包括安全性、數學與程式碼等,並經過人工驗證,確保數據的客觀性和獎勵差距的顯著性。
經過測試,崑崙萬維的獎勵模型在對話、安全性等領域展現了出色的表現,尤其在面對困難樣本時,只有Skywork-Reward-Gemma-2-27B模型給出了正確的預測。這項成就標誌著崑崙萬維在全球AI領域的技術實力和創新能力,同時也為AI技術的發展與應用提供了新的可能性。
27B模型位址:
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
8B模型位址:
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
崑崙萬維在RewardBench上的優異表現,展現了其在人工智慧領域的領先技術和創新能力,也為大語言模型的未來發展提供了新的方向和可能性,期待其未來帶來更多突破性成果。