在學術界,虛假論文的氾濫已成為一個嚴峻的問題,嚴重阻礙了科學研究的進步和知識的傳播。為應對這項挑戰,來自紐約州賓漢姆頓大學的研究員阿赫邁德・阿布丁・哈梅德開發了一種名為xFakeSci的機器學習演算法,該演算法能夠有效識別偽造的學術論文,為維護學術誠信提供了新的技術手段。本文將深入探討xFakeSci演算法的原理、應用及未來發展方向,展現其打擊學術造假的巨大潛力。
在現今這個資訊爆炸的時代,尤其是科學研究領域,假論文的出現讓人防不勝防。
最近,來自紐約州賓漢姆頓大學的一位研究員阿赫邁德・阿布丁・哈梅德(Ahmed Abdeen Hamed)開發了一款名為xFakeSci 的機器學習演算法,能夠高達94% 的準確率識別偽造的學術論文。
哈梅德表示,他主要的研究方向是生物醫學資訊學,而在疫情期間,假研究文章更是層出不窮。
他和團隊進行了大量實驗,製作了針對阿茲海默症、癌症和憂鬱症這三個熱門醫學主題的50篇假文章,並與同主題的真實文章進行了對比分析。他希望透過這種方法發現其中的差異和模式。
在研究過程中,哈梅德透過使用美國國家衛生研究院的PubMed 資料庫來提取相關文獻,並運用相同的關鍵字請求ChatGPT 產生論文。他的直覺告訴他,假論文和真實論文之間一定存在某種模式。
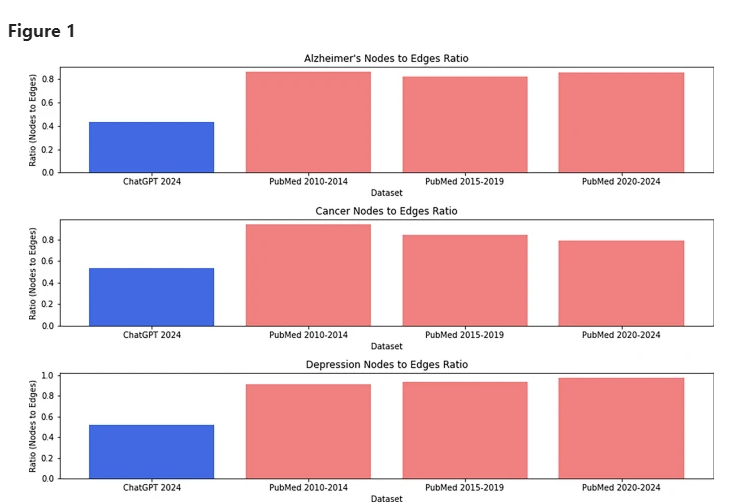
不同資料集的節點與邊緣比率ChatGPT 與科學文章。
經過深入分析,xFakeSci 演算法主要關注兩大特徵:一是文章中的雙字組合(bigrams),例如「氣候變遷」、「臨床試驗」 等,二是這些雙字組合與其他詞彙和概念的關聯。
他發現,假論文中出現的雙字組合數量明顯少於真實論文,儘管這些組合在假論文中卻與其他內容緊密相連。
他指出,AI 產生的論文往往是為了讓讀者信服,而人類研究者的目標則是如實報告實驗結果和方法。
未來,哈梅德計畫將xFakeSci 演算法擴展到更多領域,包括工程、科學及人文學科等,以驗證假論文的特徵是否一致。他強調,隨著AI 技術的不斷進步,辨識真假論文的難度將不斷增加。因此,設計一個全面的解決方案顯得格外重要。
雖然目前的演算法能偵測出94% 的假論文,但仍有6% 的假文獻可能會漏網。他謙虛地表示,雖然取得了重要進展,但仍需不斷努力,以提高識別率並提升公眾的警覺性。
論文入口:https://www.nature.com/articles/s41598-024-66784-6
劃重點:
** 新工具xFakeSci 能高達94% 準確率辨識假科研論文,為科學研究保駕護航。 **
? ** 研究人員製作了大量假論文與真實論文對比,發現兩者在寫作風格上有顯著差異。 **
** 未來將擴展演算法應用範圍,以應對日益複雜的AI 生成論文挑戰。 **
xFakeSci演算法的出現為打擊學術造假提供了強大的武器,但仍需不斷改進和改進。 科技的進步與學術誠信的維護需要共同努力,才能創造出更健康的學術生態。