GoogleDeepMind聯合多所大學研發了一種名為生成獎勵模型(GenRM)的新方法,旨在解決生成式AI在推理任務中準確性和可靠性不足的問題。現有的生成式AI模型雖然在自然語言處理等領域應用廣泛,但常常會自信地輸出錯誤訊息,尤其在對準確性要求極高的領域,這限制了其應用範圍。 GenRM 的創新之處在於將驗證過程重新定義為下一個詞預測任務,將大型語言模型(LLMs)的文本生成能力融入驗證過程,並支援鍊式推理,從而實現更全面和系統的驗證。
最近,GoogleDeepMind 的研究團隊聯合多所大學提出了一種新方法,名為生成獎勵模型(GenRM),旨在提升生成式AI 在推理任務中的準確性和可靠性。
生成式AI 被廣泛應用於自然語言處理等多個領域,主要透過預測一系列詞彙的下一個詞來產生連貫的文本。然而,這些模型有時會自信地輸出錯誤的訊息,尤其在教育、金融和醫療等對準確性要求極高的領域,這無疑是個大問題。
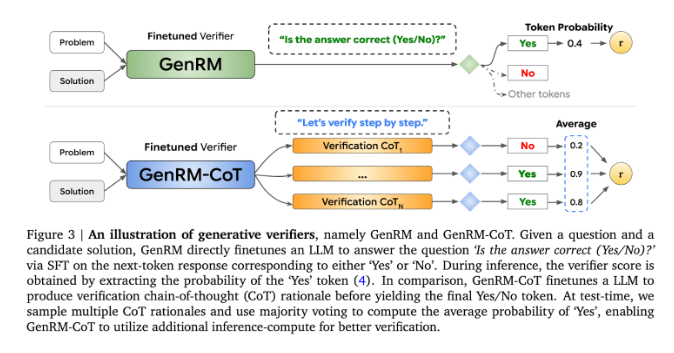
目前,針對生成式AI 模型在輸出準確性上遇到的困難,研究人員嘗試了不同的解決方案。其中,判別式獎勵模型(RMs)被用來根據分數判斷潛在答案的正確與否,但這種方法未能充分利用大型語言模型(LLMs)的生成能力。而另一個常用的方法是“LLM 作為評判者”,但這種方法在解決複雜的推理任務時,效果往往不如專業的驗證器。
GenRM 的創新之處在於將驗證過程重新定義為下一個字預測任務。這意味著,與傳統的判別式獎勵模型不同,GenRM 將LLMs 的文本生成能力融入驗證過程中,使得模型能夠同時產生和評估潛在的解決方案。此外,GenRM 還支援鍊式推理(CoT),即模型在得出最終結論之前,可以產生中間的推理步驟,使驗證過程更加全面和系統化。
透過將生成與驗證結合起來,GenRM 方法採用了一種統一的訓練策略,使得模型能夠在訓練過程中同時提升生成和驗證能力。在實際應用中,模型會產生中間推理步驟,這些步驟用於驗證最終答案。
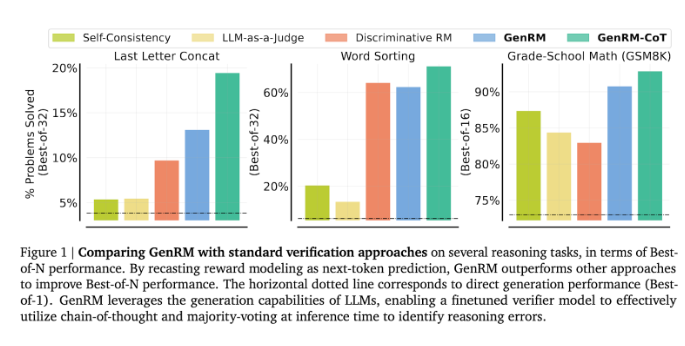
研究人員發現,GenRM 模型在多個嚴謹測驗中表現優異,例如在學齡前數學和演算法問題解決任務中,GenRM 的準確率顯著提高。與判別式獎勵模型和LLM 作為評判者的方法相比,GenRM 的解決問題成功率提高了16%到64%。
例如,在驗證Gemini1.0Pro 模型的輸出時,GenRM 將問題解決成功率從73% 提升到了92.8%。
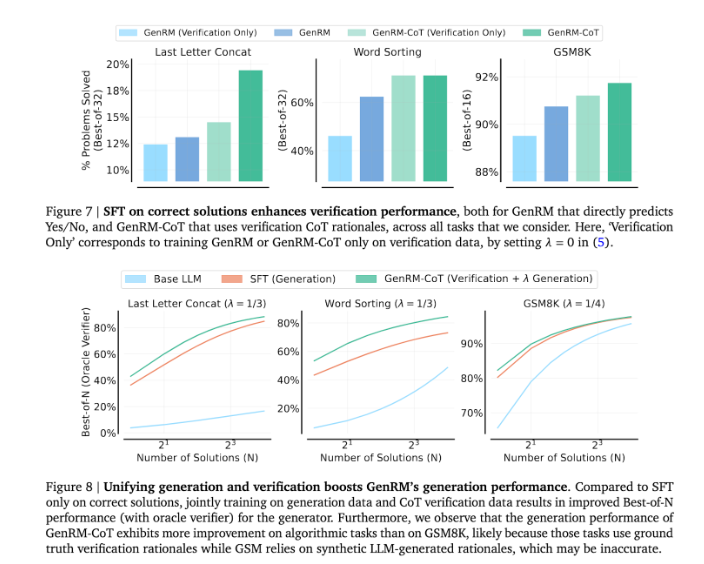
GenRM 方法的推出標誌著生成式AI 領域的一大進步,透過將解決方案產生與驗證統一為一個流程,顯著提高了AI 生成解決方案的準確性和可信賴性。
總而言之,GenRM 的出現為提高生成式AI 的可靠性提供了新的思路,其在解決複雜推理問題上的顯著提升,預示著生成式AI 在更多領域應用的可能性,值得進一步研究和探索。