資料庫查詢最佳化器嚴重依賴基數估計(CE)來預測查詢結果大小,從而選擇最佳執行計劃。不準確的基數估計會導致查詢效能下降。現有CE方法有其局限性,尤其是在處理複雜查詢時。學習型CE模式雖然更準確,但訓練成本高,且缺乏系統性的基準評估。
在現代關係資料庫中,基數估計(CE)起著至關重要的作用。簡單來說,基數估計就是預測資料庫查詢會傳回多少中間結果。這項預測對查詢優化器的執行計劃選擇影響巨大,例如決定連接順序、是否使用索引以及最佳連接方法的選擇。如果基數估計不準確,執行計劃可能會大打折扣,導致查詢速度極慢,嚴重影響資料庫的整體效能。
然而,現有的基數估計方法有許多限制。傳統的CE 技術依賴一些簡化的假設,往往精準預測複雜查詢的基數,尤其是涉及多個表格和條件的情況。雖然學習型CE 模型能提供更好的準確性,但它們的應用卻受到訓練時間長、需要大數據集以及缺乏系統性基準評估的限制。
為了填補這一空白,Google 的研究團隊推出了CardBench,一個全新的基準測試框架。 CardBench 包含超過20個真實世界的資料庫和數千個查詢,遠超過以往的基準。這使得研究人員能夠在各種條件下系統地評估和比較不同的學習型CE 模式。此基準支援三種主要設定:基於實例的模型、零樣本模型和微調模型,適用於不同的訓練需求。
CardBench 的設計還包括一系列工具,可以計算必要的資料統計,產生真實的SQL 查詢,並建立用於訓練CE 模型的註解查詢圖。
此基準測試提供兩組訓練資料:一組用於具有多個篩選條件謂詞的單一資料表查詢,另一組用於涉及兩個資料表的二進位聯接查詢。此基準測試包括9125個單表查詢和8454個二進位連接查詢,適用於其中一個較小的資料集,從而確保為模型評估提供強大且具有挑戰性的環境。源自Google BigQuery 的訓練資料標籤需要7個CPU 年的查詢執行時間,這凸顯了創建此基準測試的重大運算投資。透過提供這些資料集和工具,CardBench 降低了對開發和測試新CE 模型的研究人員的門檻。
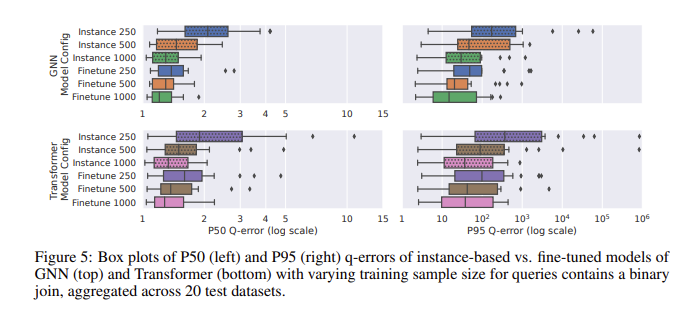
在使用CardBench 進行的效能評估中,微調模型的表現特別突出。雖然零樣本模型在應用於看不見的資料集時難以提高準確性,尤其是在涉及聯接的複雜查詢中,但微調模型可以達到與基於實例的方法相當的準確性,而訓練資料則少得多。例如,微調的圖形神經網路(GNN) 模型在二進位連接查詢中實現了1.32的中位數q 誤差和第95個百分位的q 誤差120,明顯優於零樣本模型。結果表明,即使有500個查詢,微調預訓練模型也可以顯著提高其效能。這使得它們適用於訓練資料可能受限的實際應用。
CardBench 的推出為學習型基數估計領域帶來了新的希望,使研究人員能夠更有效地評估和改進模型,從而推動這一重要領域的進一步發展。
論文入口:https://arxiv.org/abs/2408.16170
總之,CardBench 提供了一個全面且強大的基準測試框架,為學習型基數估計模型的研究和發展提供了重要的工具和資源,推動了資料庫查詢最佳化技術的進步。 其微調模型的優異表現尤其值得關注,為實際應用場景提供了新的可能性。