近日,一項發表在《Cureus》雜誌上的研究顯示,OpenAI的GPT-4模型在未經額外訓練的情況下,成功通過了日本國家物理治療考試。研究人員使用1000個涵蓋記憶、理解、應用、分析和評估等方面的問題對GPT-4進行測試,結果顯示其正確率達73.4%,並通過了所有五個測試部分。這項研究引發了人們對GPT-4在醫療領域應用潛力的關注,同時也揭示了其在處理特定類型問題時的局限性,例如實際問題和包含圖片表格的問題。
最新發表在《Cureus》雜誌上的一項同行評審研究顯示,OpenAI的GPT-4語言模型在未經任何額外訓練的情況下,成功通過了日本國家物理治療考試。
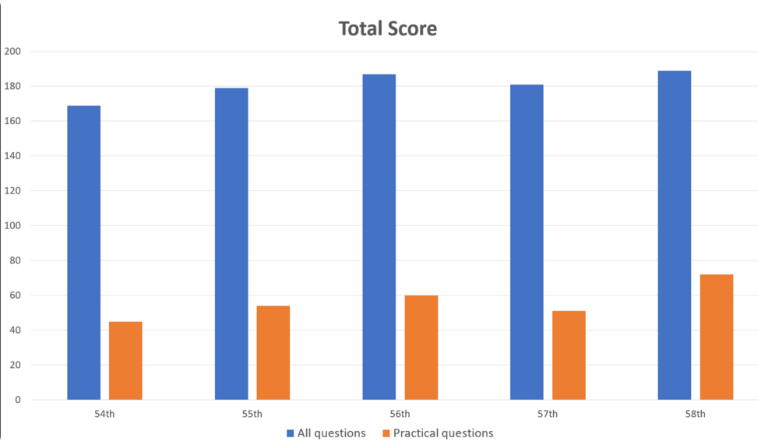
研究者向GPT-4輸入了1,000個問題,涵蓋記憶、理解、應用、分析和評估等面向。結果顯示,GPT-4總體上正確回答了73.4%的問題,通過了所有五個測試部分。然而,研究也揭示了AI在某些領域的限制。

GPT-4在一般問題上表現出色,正確率達80.1%,但實際問題僅為46.6%。同樣,它在處理純文字問題(80.5%正確)方面遠優於帶有圖片和表格的問題(35.4%正確)。這項發現與先前關於GPT-4視覺理解限制的研究結果一致。
值得注意的是,問題難度和文字長度對GPT-4的表現影響不大。儘管模型主要使用英語資料訓練,但在處理日語輸入時也表現良好。
研究人員指出,雖然這項研究展示了GPT-4在臨床復健和醫學教育方面的潛力,但仍需謹慎看待。他們強調,GPT-4並不能正確回答所有問題,未來還需要評估新版本以及模型在書面和推理測驗中的能力。
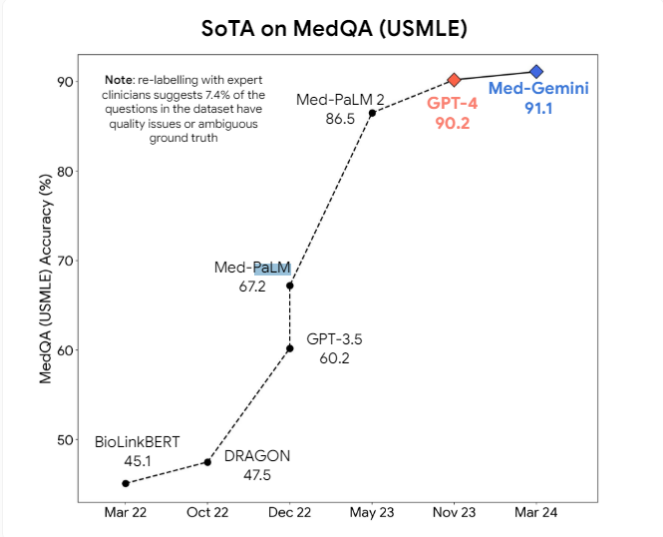
此外,研究人員提出,像GPT-4v這樣的多模態模型可能在視覺理解方面帶來進一步的改進。目前,Google的Med-PaLM2、Med-Gemini等專業醫療AI模型,以及Meta基於Llama3的醫療模型都在積極開發中,旨在在醫療任務中超越通用模型。
然而,專家們認為,醫療AI模型要廣泛應用於實務可能還需要很長時間。目前模型的誤差空間在醫療環境中仍然過大,需要在推理能力上取得顯著進步,才能安全地將這些模型整合到日常醫療實踐中。
這項研究雖然展示了GPT-4在醫療領域的潛力,但也提醒我們,AI技術仍需不斷完善,才能真正應用於複雜的醫療情境。未來,多模態模型和更強大的推理能力將是關鍵的改進方向,確保AI在醫療中的安全性和可靠性。