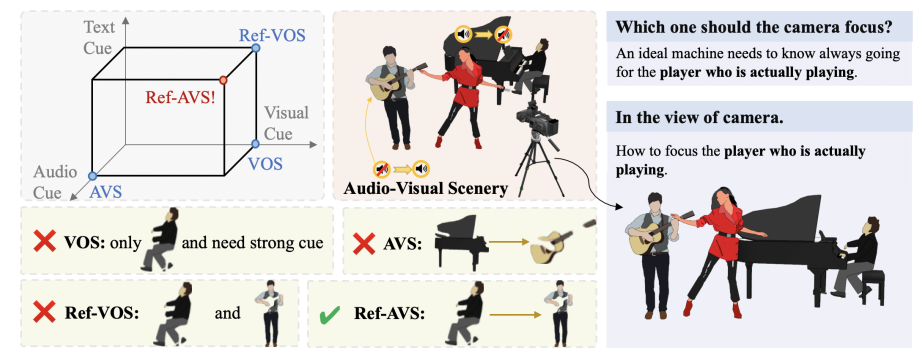
人工智慧領域一直致力於讓機器理解複雜物理世界,這方面的突破對許多領域至關重要。近日,中國人民大學、北京郵電大學和上海AI Lab等機構的研究團隊研發出Ref-AVS技術,為此難題提供了新的解決方案。 Ref-AVS技術透過巧妙的多模態融合方法,整合了視訊物件分割、視訊物件參考分割和視聽分割等多種模態訊息,使得AI系統能夠更精準地理解自然語言指令,並在複雜的視聽場景中精確定位目標物體,突破了以往AI在多模態理解上的限制。
在人工智慧領域,讓機器像人類一樣理解複雜的物理世界一直是個重大挑戰。近日,由中國人民大學、北京郵電大學和上海AI Lab等機構組成的研究團隊提出了一項突破性技術——Ref-AVS,為解決這個難題帶來了新的希望。
Ref-AVS技術的核心在於其獨特的多模態融合方法。它巧妙地整合了視訊物件分割(VOS)、視訊物件參考分割(Ref-VOS)和視聽分割(AVS)等多種模態資訊。這種創新性的融合使得AI系統不僅能夠處理正在發聲的物體,還能辨識場景中不發聲但同樣重要的物體。這項突破讓AI能更精確地理解使用者透過自然語言所描述的指令,並在複雜的視聽場景中精確定位特定物體。
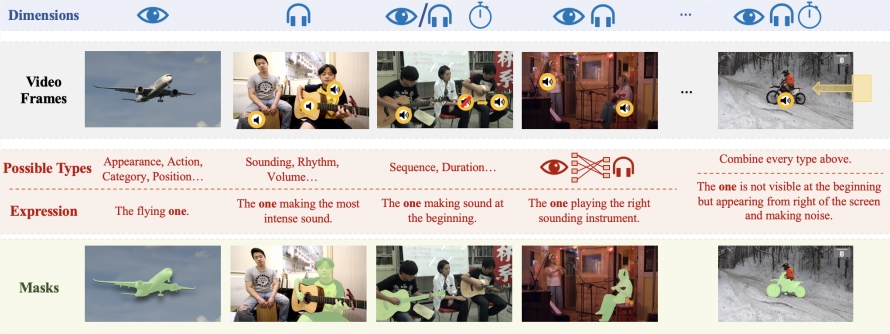
為支撐Ref-AVS技術的研究和驗證,研究團隊建構了一個名為Ref-AVS Bench的大規模資料集。這個資料集包含了40,020個視訊幀,涵蓋6,888個物體和20,261個指代表達式。每個視訊畫面都配有相應的音訊和像素級的詳細標註。這個豐富多元的資料集為多模態研究提供了堅實的基礎,也為未來相關領域的研究開啟了新的可能性。
在一系列嚴格的定量和定性實驗中,Ref-AVS技術展現了卓越的性能。特別是在Seen子集上,Ref-AVS的表現超越了現有的其他方法,充分證明了其強大的分割能力。更值得注意的是,在Unseen和Null子集上的測試結果進一步驗證了Ref-AVS技術優秀的泛化能力和對空引用的穩健性,這對於實際應用場景至關重要。
Ref-AVS技術的成功不僅在學術界引起了廣泛關注,也為未來的實際應用開闢了新的道路。我們可以預見,這項技術將在影片分析、醫療影像處理、自動駕駛和機器人導航等多個領域中發揮重要作用。例如,在醫療領域,Ref-AVS可能幫助醫生更準確地解讀複雜的醫學影像;在自動駕駛領域,它可能提升車輛對周圍環境的感知能力;在機器人技術中,它可能讓機器人更好地理解和執行人類的口頭指示。
這項研究成果已在ECCV2024上展示,相關論文和專案資訊也已公開,為全球對此領域感興趣的研究者和開發者提供了寶貴的學習和探索資源。這種開放共享的態度不僅體現了中國科學研究團隊的學術精神,也將推動整個AI領域的快速發展。
Ref-AVS技術的出現,標誌著人工智慧在多模態理解方面邁出了重要一步。它不僅展現了中國科研團隊在AI領域的創新能力,也為人機互動的未來描繪了一幅更聰明、更自然的藍圖。隨著這項技術的不斷完善和應用,我們有理由期待,未來的AI系統將能更好地理解和適應人類的複雜世界,為各行各業帶來革命性的變革。
論文網址:https://arxiv.org/abs/2407.10957
專案主頁:
https://gewu-lab.github.io/Ref-AVS/
總之,Ref-AVS技術的問世為人工智慧多模態理解領域帶來了新的突破,其強大的性能和廣泛的應用前景值得期待。這項技術將推動人工智慧朝向更智慧、更自然的互動方向發展,為人類社會帶來更多便利。