近日,MLCommons 發布了MLPerf 推理v4.1 的結果,多位AI 推理晶片廠商參與其中,競爭激烈。本次比賽首次包含了AMD、Google、UntetherAI 等廠商的晶片,以及Nvidia 的最新黑威爾晶片。除了性能對比,能源效率也成為重要的競爭維度。各廠商紛紛亮出看家本領,在不同基準測試中展現各自優勢,為AI 推理晶片市場帶來新的活力。
在人工智慧訓練領域,Nvidia 的顯示卡地位幾乎無人能敵,但在AI 推理方面,競爭對手似乎開始迎頭趕上,尤其是在能源效率方面。儘管Nvidia 最新的黑威爾晶片性能強勁,但能否繼續保持領先尚未可知。今天,ML Commons 公佈了最新的AI 推理競賽結果—MLPerf 推理v4.1。這一輪比賽首次有AMD 的Instinct 加速器、Google的Trillium 加速器、加拿大新創公司UntetherAI 的晶片以及Nvidia 的黑威爾晶片參賽。還有兩家公司Cerebras 和FuriosaAI 雖然推出了新的推理晶片,但並未提交MLPerf 的測試。
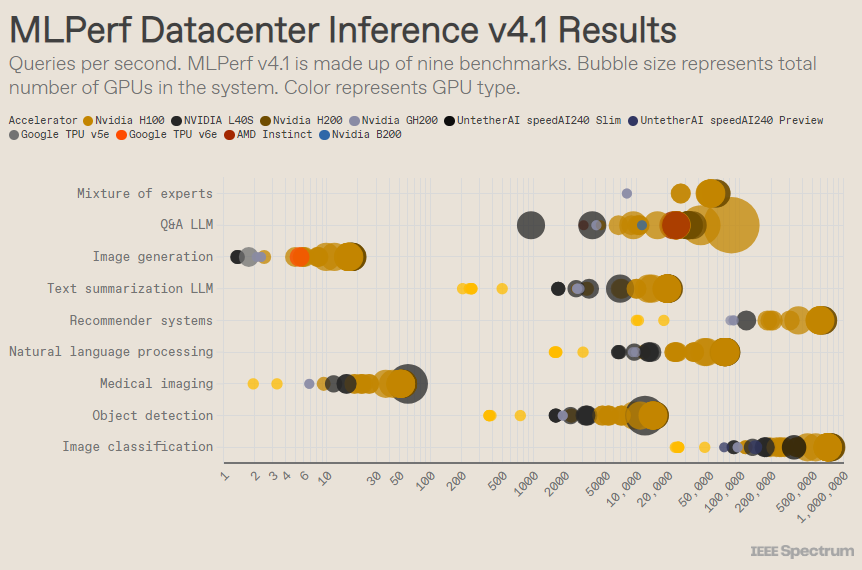
MLPerf 的結構就像一場奧運比賽,有多個項目和子項目。其中「資料中心封閉」 類別的參賽者最多。與開放類別不同,封閉類別要求參賽者在不顯著修改軟體的情況下,直接在給定模型上進行推理。資料中心類別主要測試批次處理請求的能力,而邊緣類別則專注於降低延遲。
每個類別下有9個不同的基準測試,涵蓋各種AI 任務,包括熱門的圖像生成(想想Midjourney)和大型語言模型的問答(例如ChatGPT),還有一些重要但鮮為人知的任務,例如影像分類、物件檢測和推薦引擎。
這一輪比賽增加了一個新基準——「專家混合模型」。這是一種越來越流行的語言模型部署方法,將一個語言模型分割成多個獨立的小模型,每個模型針對特定任務進行微調,例如日常對話、解決數學問題或程式輔助。透過將每個查詢分配給相應的小模型,資源利用得以減少,從而降低成本並提高吞吐量,AMD 的高級技術人員Miroslav Hodak 如是說。

在熱門的「資料中心封閉」 基準測試中,獲勝的仍然是基於Nvidia H200GPU 和GH200超級晶片的提交,它們將GPU 和CPU 結合在一個包中。然而,仔細分析結果會發現一些有趣的細節。某些參賽者使用了多個加速器,而有些則只使用了一個。如果我們按加速器數量歸一化每秒查詢數,並保留每種加速器類型中表現最佳的提交,結果會更加撲朔迷離。需要指出的是,這種方法忽略了CPU 和互連的作用。
在每個加速器的基礎上,Nvidia 的黑威爾在大型語言模型問答任務上表現優異,速度比之前的晶片迭代提升了2.5倍,這是唯一一個它提交的基準測試。 Untether AI 的speedAI240預覽晶片在其唯一提交的影像辨識任務上表現幾乎與H200持平。 Google的Trillium 在影像產生任務上表現略低於H100和H200,而AMD 的Instinct 在大型語言模型問答任務上則表現相當於H100。
黑威爾的成功部分源自於它能夠使用4位元浮點精度進行大型語言模型的運作。 Nvidia 和競爭對手一直在努力降低變換模型(例如ChatGPT)中資料表示的位數,以加快計算速度。 Nvidia 在H100中引入了8位元數學,而這次的提交則是4位數學在MLPerf 基準測試中的首次展示。
使用如此低精度數字的最大挑戰在於保持準確性,Nvidia 的產品行銷總監Dave Salvator 表示。為了在MLPerf 提交中維持高準確率,Nvidia 團隊在軟體方面進行了大量創新。
此外,黑威爾的記憶體頻寬幾乎翻倍,達到了每秒8太字節,而H200則是4.8太字節。
Nvidia 的黑威爾提交使用了單一晶片,但Salvator 表示它設計用於網路和擴展,並將在與Nvidia 的NVLink 互連結合使用時表現最佳。黑威爾GPU 支援多達18個NVLink100GB 每秒的連接,總頻寬達到1.8太字節每秒,幾乎是H100的互連頻寬的兩倍。
Salvator 認為,隨著大型語言模型的規模不斷擴大,即使是推理也將需要多GPU 平台來滿足需求,而黑威爾正是為這種情況而設計的。 「黑威爾是一個平台,」Salvator 說。
Nvidia 將其黑威爾晶片系統提交到預覽子類別,意味著它尚未上市,但預計在下次MLPerf 發布前會可用,大約在六個月後。
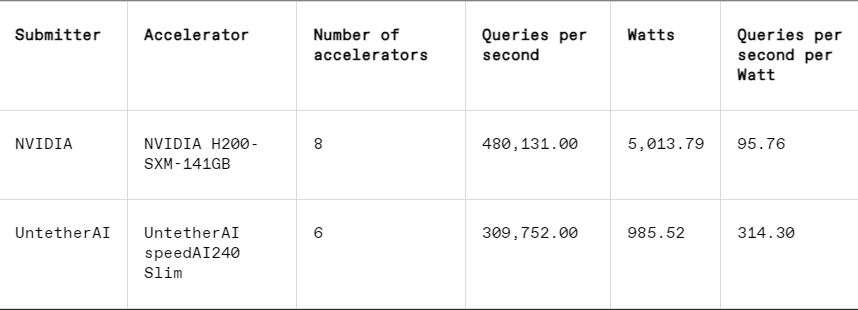
在每個基準測試中,MLPerf 還包括能量測量部分,系統地測試每個系統在執行任務時的實際功耗。這一輪的主要比賽(資料中心封閉能量類別)僅有Nvidia 和Untether AI 兩家提交者參與。雖然Nvidia 參與了所有基準測試,但Untether 只在影像辨識任務中提交了結果。
Untether AI 在這方面表現出色,成功實現了卓越的能源效率。他們的晶片採用了一種名為「記憶體運算」 的方法。 Untether AI 的晶片由一組記憶體單元構成,附近有小型處理器與之相鄰。每個處理器並行工作,與鄰近的記憶體單元中的資料同時處理,從而顯著減少了在記憶體和計算核心之間傳輸模型資料所花費的時間和能量。
「我們發現,進行AI 工作負載時,90% 的能量消耗在於將資料從DRAM 移至快取處理單元,」Untether AI 的產品副總裁Robert Beachler 表示。 “因此,Untether 的做法是將計算移動到數據附近,而不是將數據移動到計算單元。”
此方法在MLPerf 的另一個子類別中表現尤為出色:邊緣封閉。這個類別專注於更實際的用例,例如工廠的機器檢測、引導視覺機器人和自動駕駛車輛—— 這些應用對能源效率和快速處理有嚴格的要求,Beachler 解釋道。
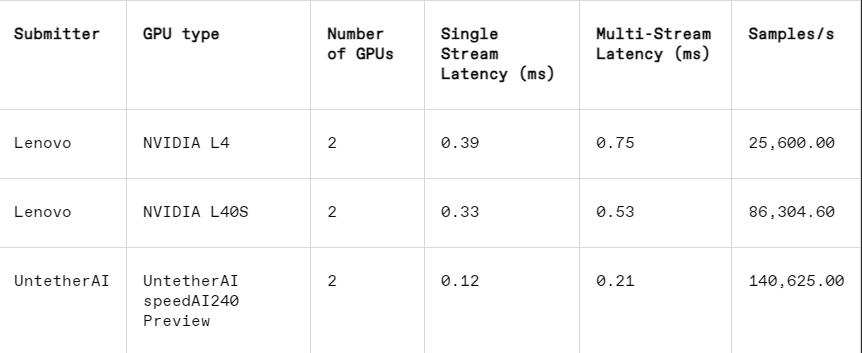
在影像辨識任務中,Untether AI 的speedAI240預覽晶片的延遲效能比Nvidia 的L40S 快了2.8倍,吞吐量(每秒樣本數)也提高了1.6倍。新創公司也在這個類別中提交了功耗結果,但Nvidia 的競爭者並沒有,因此很難進行直接比較。然而,Untether AI 的speedAI240預覽晶片的標稱功耗為150瓦,而Nvidia 的L40S 則為350瓦,顯示出其在功耗方面具有2.3倍的優勢,同時延遲表現也更佳。
雖然Cerebras 和Furiosa 沒有參加MLPerf,但它們也分別發布了新晶片。 Cerebras 在史丹佛大學的IEEE Hot Chips 會議上揭曉了其推理服務。總部位於加州陽光谷的Cerebras 製造的巨型晶片,尺寸大到矽晶圓所允許的極限,從而避免了晶片之間的互連,並極大地提高了設備的內存頻寬,主要用於訓練巨型神經網路。現在,他們已經升級了最新的電腦CS3以支援推理。
儘管Cerebras 沒有提交MLPerf,但該公司聲稱其平台在每秒生成的LLM 令牌數量上超越了H100的7倍和競爭對手Groq 晶片的2倍。 「今天,我們處於生成AI 的撥號時代,」Cerebras 執行長兼聯合創始人Andrew Feldman 表示。 「這都是因為存在內存頻寬瓶頸。無論是Nvidia 的H100還是AMD 的MI300或TPU,它們都使用相同的外部內存,導致相同的限制。我們打破了這一障礙,因為我們採用的是晶圓級設計。
Hot Chips 大會上,來自首爾的Furiosa 也展示了其第二代晶片RNGD(發音為「叛逆者」)。 Furiosa 的新晶片以其張量收縮處理器(TCP)架構為特點。在AI 工作負載中,基本的數學功能是矩陣乘法,通常在硬體中作為一個原語實現。然而,矩陣的大小和形狀,即更廣泛的張量,可以有很大的不同。 RNGD 實現了這種較通用的張量乘法作為原語。 「在推理過程中,批量大小變化很大,因此充分利用給定張量形狀的固有並行性和數據重用至關重要,」Furiosa 創始人兼首席執行官June Paik 在Hot Chips 上表示。
儘管Furiosa 沒有MLPerf,但他們在內部測試中將RNGD 晶片與MLPerf 的LLM 摘要基準進行了比較,結果表現與Nvidia 的L40S 晶片相當,但功耗僅為185瓦,而L40S 則為320瓦。 Paik 表示,隨著進一步的軟體優化,效能將會提升。
IBM 也宣布推出其新的Spyre 晶片,專為企業產生AI 工作負載而設計,預計將在2025年第一季上市。
顯然,AI 推理晶片市場在可預見的未來將會熱鬧非凡。
參考資料:https://spectrum.ieee.org/new-inference-chips
總而言之,MLPerf v4.1 的結果顯示,AI 推理晶片市場競爭日趨激烈,Nvidia 雖然仍保持領先,但AMD、Google和Untether AI 等廠商的崛起不容忽視。未來,能源效率將成為關鍵競爭因素,記憶體運算等新技術也將發揮重要作用。 各廠商的技術創新將持續推動AI 推理能力的提升,為AI 應用的普及與發展提供強勁動力。