在資訊爆炸的時代,精準高效的資訊篩選至關重要。推薦系統作為資訊過載的解決方案,卻常常面臨推薦結果與使用者喜好偏差的問題。來自香港大學團隊研發的EasyRec,為此難題提供了創新的解決方案。它是基於語言模型的推薦系統,即使在資料匱乏的情況下,也能準確預測使用者偏好,提升推薦效率。
在資訊氾濫的時代,推薦系統成為了我們篩選資訊的重要助手。但是,你是否曾因為推薦內容不合口味而感到失望?或者在使用新應用時,推薦系統似乎總是無法精準把握你的需求?現在,EasyRec 的出現,或許能夠解決這些難題。
EasyRec,由香港大學的團隊開發,是一款基於語言模型的推薦系統。它的獨特之處在於,即使在沒有大量使用者資料的情況下,也能透過分析文字資訊來預測使用者的喜好。
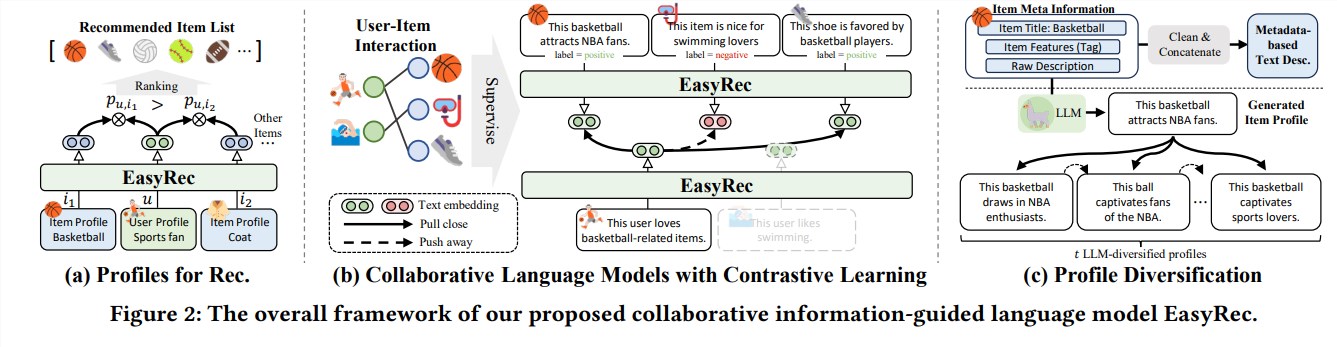
該系統的核心技術是文字行為對齊框架。這項技術透過分析使用者的行為故事,例如瀏覽的商品和閱讀的評價,結合其中的情感和細節,來預測使用者的潛在喜好。
EasyRec 的智慧之處在於它結合了對比學習和協同語言模型。系統不僅學習使用者喜好的商品特徵,也學習其他使用者的數據,透過比較分析,找出最有可能吸引使用者的商品。
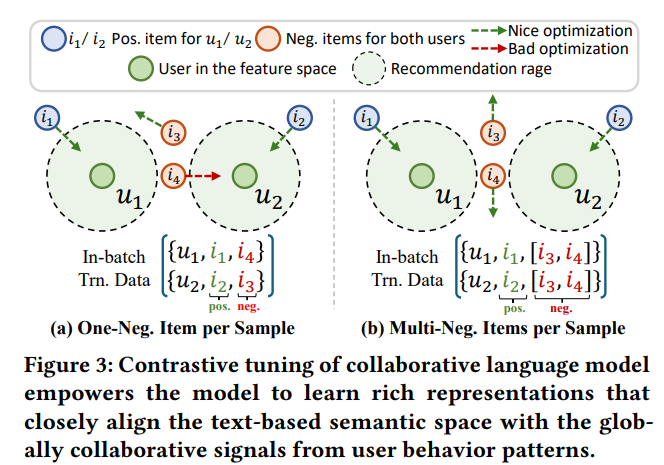
在多個真實世界資料集上的測試表明,EasyRec 在推薦準確性上超越了現有模型,特別是在處理新用戶和新商品的零樣本推薦場景中表現出色。
EasyRec 的另一個優點是它的即插即用特性,可以輕鬆整合到現有的推薦系統中。這使得無論是商業用戶或學術研究者,都能快速提升推薦系統的效能。
隨著技術的不斷進步,EasyRec 的潛力正在進一步挖掘。它不僅能提升商業推薦系統的理解能力,也可能為學術研究帶來新的突破。
論文網址:https://arxiv.org/pdf/2408.08821
EasyRec憑藉其獨特的文本行為對齊框架和對比學習機制,在零樣本推薦場景下展現出優異的性能,為解決推薦系統面臨的挑戰提供了新的思路。其即插即用的特性也方便了廣泛應用,值得期待其在未來商業和學術領域的進一步發展。