微软推出全新轻量级多模态AI模型Phi-3.5-vision,它作为Phi-3家族的新成员,旨在处理文本和视觉输入。该模型在资源受限的环境下表现出色,支持128K上下文长度,非常适合商业和研究应用。Phi-3.5-vision集图像理解、OCR、图表解析等功能于一体,并在多个基准测试中展现了优异性能。其开源特性和高效的设计,使其成为各种AI应用的理想选择。
Phi-3.5-vision模型具备广泛的图像理解、光学字符识别(OCR)、图表和表格解析、多图像或视频剪辑摘要等功能。在图像和视频处理相关的基准测试中,该模型展现出了显著的性能提升。
Phi-3.5-vision模型由一个42亿参数的系统构成,包括图像编码器、连接器、投影器和Phi-3Mini语言模型。它使用高质量的教育数据、合成数据和经过严格筛选的公开文档进行训练,确保了数据质量和隐私。
Phi-3.5-vision包含三款模型:
Phi-3.5Mini Instruct:轻量级AI模型,适合内存或计算资源有限的环境。
Phi-3.5MoE (Mixture of Experts):微软首次推出的“专家混合”模型,擅长处理复杂任务。
Phi-3.5Vision Instruct:多模态模型,集成了文本和图像处理功能。
主要功能特点
Phi-3.5-vision模型的主要功能特点包括图像理解、OCR、图表和表格理解、多图像对比、多图像或视频剪辑摘要、高效的推理能力以及低延迟和内存优化。
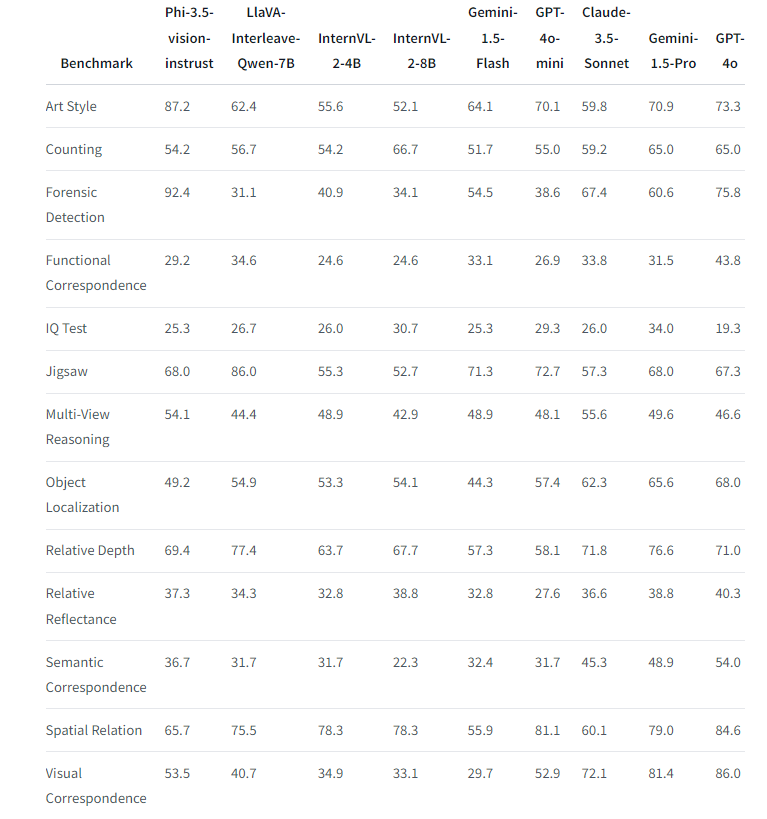
Phi-3.5-vision在多项基准测试中表现优异,如MMMU、MMBench、TextVQA和视频处理能力测试,以及BLINK基准测试,展现了其在多模态和视觉任务中的强大性能。
微软Phi-3.5-vision模型的发布,为AI领域带来了新的选择,特别是在端侧运行和复杂视觉推理方面。它的开源特性和优化设计,使其在资源受限的环境中也能发挥出色的性能,为多种AI驱动的应用提供了强大支持。
模型下载地址:https://huggingface.co/microsoft/Phi-3.5-vision-instruct
总而言之,Phi-3.5-vision凭借其轻量级、多模态和高性能的特点,为AI开发者和研究人员提供了一个强大的工具,推动了AI在更多领域的应用。其开源特性也促进了AI技术的共享和发展。