Transformer架構的興起革新了自然語言處理領域,但其在處理長文本時的高運算成本成為瓶頸。針對這個難題,本文介紹了一種名為Tree Attention的新方法,它透過樹狀歸約的方式,有效降低了長上下文Transformer模型的自註意力計算複雜度,並充分利用了現代GPU集群的網路拓樸結構,大大提升了運算效率。
在這個資訊爆炸的時代,人工智慧如同一顆璀璨的星辰,照亮了人類智慧的夜空。而在這些星辰中,Transformer架構無疑是最耀眼的那一顆,它以自註意力機制為核心,引領了自然語言處理的新時代。然而,即使是最耀眼的星辰,也有其難以觸及的角落。對於長上下文的Transformer模型,自註意力計算的高資源消耗成為了一個難題。想像一下,你正在嘗試讓AI理解一篇長達數萬字的文章,每一個字都要與文章中的每一個其他字進行比較,這樣的計算量無疑是巨大的。
為了解決這個問題,一群來自Zyphra和EleutherAI的科學家們,提出了一種名為Tree Attention的全新方法。
自註意力,作為Transformer模型的核心,其計算複雜度隨著序列長度的增加而呈現二次方成長。這在處理長文本時,尤其是對於大型語言模型(LLMs),成為了一個難以克服的障礙。
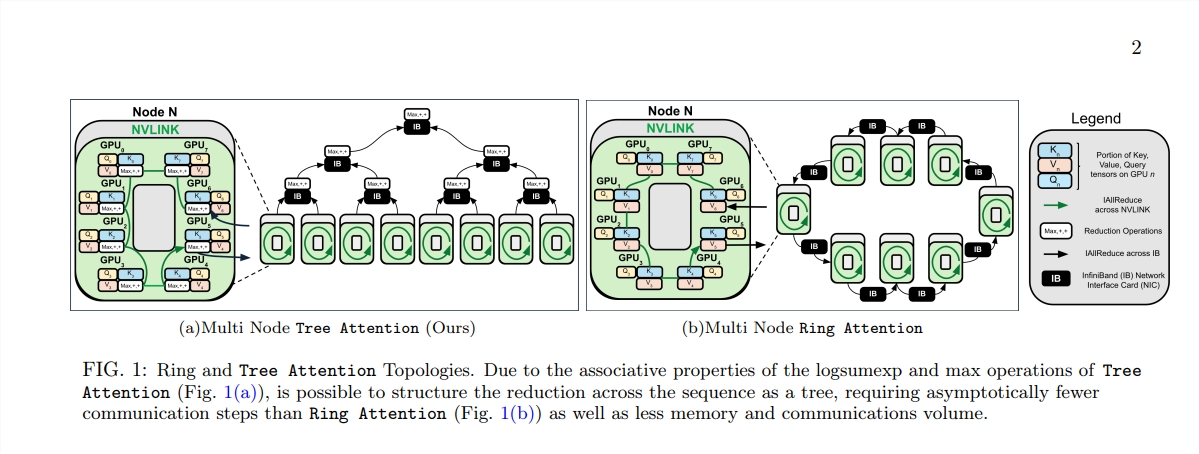
Tree Attention的誕生,就像是在這片計算的森林中,種下了一棵棵能夠高效計算的樹。它透過樹狀歸約的方式,將自註意力的計算分解為多個平行的任務,每個任務就像是樹上的一片葉子,共同構成了一棵完整的樹。
更令人驚嘆的是,Tree Attention的提出者們也推導出了自註意力的能量函數,這不僅為自註意力提供了貝葉斯的解釋,還將其與Hopfield網絡等能量模型緊密聯繫起來。
Tree Attention也特別考慮了現代GPU叢集的網路拓撲結構,透過智慧地利用叢集內部的高頻寬連接,減少了跨節點的通訊需求,從而提高了運算的效率。
科學家們透過一系列實驗,驗證了Tree Attention在不同序列長度和GPU數量下的表現。結果表明,Tree Attention在多個GPU上解碼時,比現有的Ring Attention方法快達8倍,同時顯著減少了通訊量和峰值記憶體使用。
Tree Attention的提出,不僅為長上下文注意力模型的計算提供了一個高效的解決方案,更為我們理解Transformer模型的內部機制提供了新的視角。隨著AI技術的不斷進步,我們有理由相信,Tree Attention將在未來的AI研究和應用中發揮重要作用。
論文地址:https://mp.weixin.qq.com/s/U9FaE6d-HJGsUs7u9EKKuQ
Tree Attention的出現為解決長文本處理的運算瓶頸提供了一個高效且創新的方案,其對Transformer模型的理解和未來發展都具有深遠意義。此方法不僅在表現上取得了顯著提升,更重要的是為後續研究提供了新的想法和方向,值得深入學習和探討。