AI領域權威Andrej Karpathy近期對基於人類回饋的強化學習(RLHF)提出了質疑,認為其並非通往真正人類等級AI的必經之路,引發了業內廣泛關注和熱烈討論。他認為RLHF更像是權宜之計,而非終極解決方案,並以AlphaGo為例,對比了真正強化學習與RLHF在解決問題上的差異。 Karpathy的觀點無疑為當前AI研究方向提供了新的思考角度,也為未來AI發展帶來了新的挑戰。
近日,AI界的知名研究員Andrej Karpathy拋出了一個頗具爭議的觀點,他認為目前廣受推崇的基於人類反饋的強化學習(RLHF)技術可能並非通往真正人類級別問題解決能力的必由之路。這項言論無疑為目前AI研究領域投下了一枚重磅炸彈。
RLHF曾被視為ChatGPT等大型語言模型(LLM)成功的關鍵因素,被譽為賦予AI理解力、服從性和自然互動能力的秘密武器。在傳統的AI訓練流程中,RLHF通常作為預訓練和監督式微調(SFT)之後的最後一個環節。然而,Karpathy卻將RLHF比喻為一種瓶頸和權宜之計,認為它遠非AI進化的終極解決方案。
Karpathy巧妙地將RLHF與DeepMind公司的AlphaGo做了比較。 AlphaGo採用了他所稱的真正的RL(強化學習)技術,透過不斷與自己對弈並最大化勝率,最終在沒有人類幹預的情況下超越了頂級人類棋手。這種方法透過優化神經網路直接從遊戲結果中學習,達到了超越人類的表現水準。
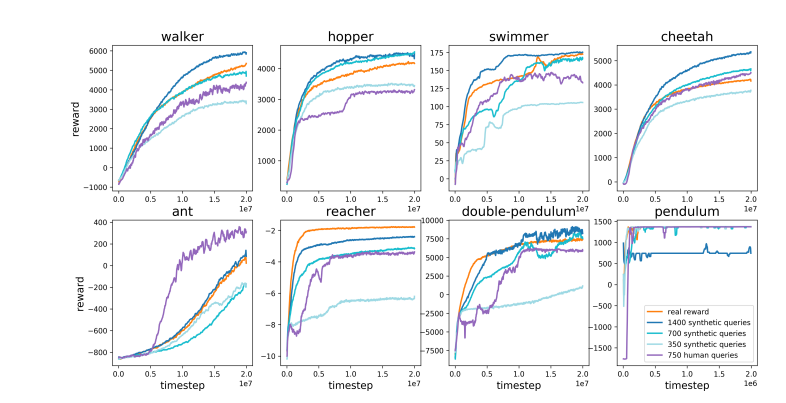
相較之下,Karpathy認為RLHF更像是在模仿人類偏好,而非真正解決問題。他設想如果AlphaGo採用RLHF方法,人類評估者將需要比較大量的棋局狀態並選擇偏好,這個過程可能需要高達10萬次比較才能訓練出一個模仿人類氛圍檢查的獎勵模型。然而,這種基於氛圍的評判在圍棋這樣的嚴謹遊戲中可能會產生誤導性結果。
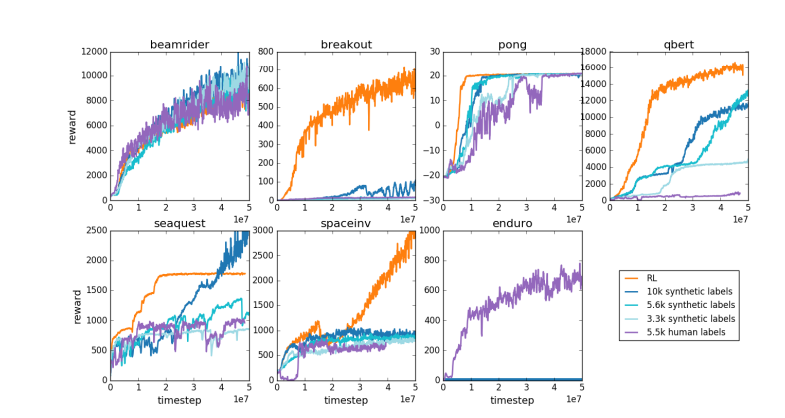
同理,目前LLM的獎勵模型工作原理也類似——它傾向於對人類評估者在統計上似乎偏好的答案進行高排名。這更像是一種迎合人類表面喜好的代理,而非真正的問題解決能力的體現。更令人擔憂的是,模型可能會迅速學會如何利用這種獎勵函數,而非真正提升自身能力。
Karpathy指出,雖然強化學習在像圍棋這樣的封閉環境中表現出色,但對於開放式語言任務來說,真正的強化學習仍然難以實現。這主要是因為在開放性任務中,很難定義明確的目標和獎勵機制。如何為總結一篇文章、回答關於pip安裝的模糊問題、講一個笑話或將Java代碼重寫為Python等任務給出客觀的獎勵?Karpathy提出了這個富有洞察力的問題,朝這個方向發展並非原則上不可能,但也絕非易事,它需要一些創意的思考。

儘管如此,Karpathy仍然認為,如果能夠解決這個難題,語言模型有望真正匹配甚至超越人類的問題解決能力。這一觀點與Google DeepMind最近發表的一篇論文不謀而合,該論文指出開放性是通用人工智慧(AGI)的基礎。
作為今年離開OpenAI的幾位高級AI專家之一,Karpathy最近正在為自己的教育AI創業公司奔走。他的這番言論無疑為AI研究領域注入了新的思考向度,也為未來AI發展方向提供了寶貴的洞見。
Karpathy的觀點引發了業界廣泛討論。支持者認為,他揭示了當前AI研究中的一個關鍵問題,即如何使AI真正具備解決複雜問題的能力,而不僅僅是模仿人類行為。反對者則擔心,過早放棄RLHF可能會導致AI發展方向的偏離。
論文網址:https://arxiv.org/pdf/1706.03741
Karpathy的觀點引發了關於AI未來發展方向的深入討論,其對RLHF的質疑促使研究者們重新審視當前AI訓練方法,並探索更有效的路徑,最終目標是實現真正意義上的人工智慧。