大型語言模型(LLM)的進步令人矚目,但在一些簡單問題上卻表現出意想不到的缺陷。 Andrej Karpathy 敏銳地指出了這種「鋸齒狀智能」現象,即LLM在複雜任務上游刃有餘,卻在簡單問題上頻頻出錯。 這引發了對LLM本質缺陷以及未來改進方向的深入思考,本文將對此進行詳細解讀,並探討如何更好地利用LLM並規避其限制。
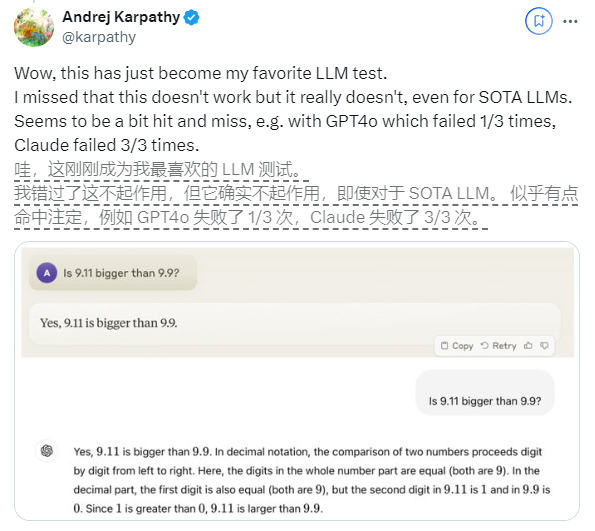
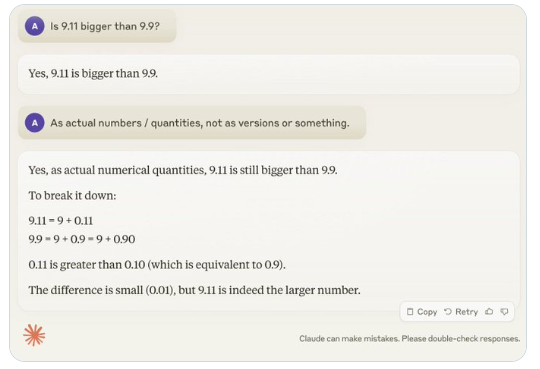
近期,一個看似簡單的問題「9.11比9.9大嗎?」在全球範圍內引發了廣泛關注,幾乎所有的大型語言模型(LLM)在這個問題上都出現了失誤。這現象引起了AI領域專家Andrej Karpathy的注意,他從這個問題出發,深入探討了當前大模型技術的本質缺陷和未來改進方向。
Karpathy將這種現象稱為「鋸齒智能」或「參差不齊的智能」(jagged intelligence),指出最先進的LLM雖然能夠執行各種複雜任務,如解決高難度數學問題,但在一些看似簡單的問題上卻表現糟糕,這種智能的不均衡性類似於鋸齒的形狀。
例如,OpenAI研究員Noam Brown發現LLM在井字棋遊戲中的表現不佳,即使在用戶即將獲勝的情況下,模型仍然無法做出正確的決策。 Karpathy認為,這是因為模型做出了「毫無道理」的決策,而Noam則認為這可能是由於訓練資料中缺乏相關策略討論導致的。
另一個例子是LLM在數字母數量時出現的錯誤。即使是最新發布的Llama3.1,也會在簡單的問題上給出錯誤答案。 Karpathy解釋說,這源於LLM缺乏“自知之明”,即模型無法分辨自己能做什麼、不能做什麼,導致模型在面對任務時都“迷之自信”。
為了解決這個問題,Karpathy提到了Meta發布的Llama3.1論文中提出的解決方案。論文建議在後訓練階段達到模型對齊,讓模型發展出自我認知,知道自己知道什麼,僅靠添加事實知識是無法根除幻覺問題的。 Llama團隊提出了一種名為「知識探測」的訓練方式,鼓勵模型只回答自己了解的問題,拒絕產生不確定的答案。
Karpathy認為,儘管目前AI的能力有種種問題,但這並不構成根本缺陷,也有可行的解決方案。他提出,目前的AI訓練思路僅僅是“模仿人類標籤並擴展規模”,要繼續提升AI的智能,就需要在整個開發堆疊中進行更多工作。
在問題完全解決之前,如果要將LLM用於生產環境,就應該只限於它們擅長的任務,注意“鋸齒狀邊緣”,並始終保持人類的參與度。這樣,我們才能更好地利用AI的潛力,同時避免其限制所帶來的風險。
總而言之,LLM的「鋸齒狀智能」是目前AI領域面臨的挑戰,但並非無法克服。透過改進訓練方法,提升模型的自知能力,並謹慎地應用於實際場景,我們可以更好地發揮LLM的優勢,推動人工智慧技術持續發展。