大型語言模型(LLMs)的快速發展帶來了令人驚嘆的自然語言處理能力,但其龐大的運算和儲存需求限制了其普及。運行一個擁有1760億參數的模型需要數百GB的儲存空間和多塊高階GPU,這使得成本高且難以推廣。為了解決這個問題,研究者致力於模型壓縮技術,例如量化,以降低模型大小和運行需求,但同時也面臨精度損失的風險。
人工智慧(AI)正變得越來越聰明,尤其是那些大型語言模型(LLMs),它們在處理自然語言方面的能力讓人驚嘆。但你知道嗎?這些聰明的AI大腦背後,是需要巨大的計算力和儲存空間來支撐的。
一個擁有1760億參數的多語言模型Bloom,光是儲存模型的權重就需要至少350GB的空間,而且運行起來還需要好幾塊高階GPU。這不僅成本高,而且難以普及。
為了解決這個問題,研究者提出了一種稱為「量化」的技術。量化,就像是給AI大腦做了一次“瘦身”,通過將模型的權重和激活映射到更低位數的數據格式,不僅減少了模型的體積,還加快了模型的運行速度。但這個過程也有風險,可能會失去一些準確性。
面對這個挑戰,北京航空航太大學和商湯科技的研究者們聯手開發了LLMC工具包。 LLMC就像是AI的私人減肥教練,它能夠幫助研究者和開發者找到最適合的減肥方案,既能讓AI模型變得更輕盈,又不會影響它的智力水平。
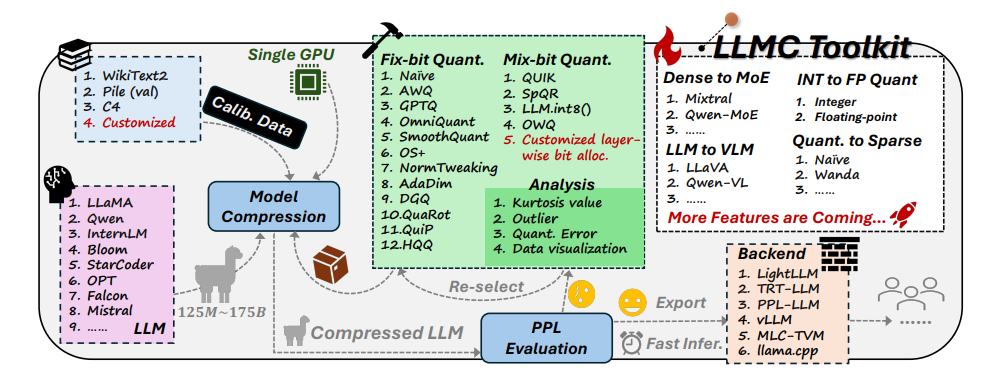
LLMC工具包有三大特點:
多樣化:LLMC提供了16種不同的量化方法,就像是為AI準備了16種不同的減肥食譜。無論你的AI是想全身減肥還是局部瘦身,LLMC都能滿足你的需求。
低成本:LLMC非常節省資源,即使是處理超大型模型,也只需要很少的硬體支援。例如,只用一塊40GB的A100GPU,就能對擁有1750億參數的OPT-175B模型進行調整評估。這就像是用家用跑步機就能訓練出奧運冠軍一樣高效!
高相容性:LLMC支援多種量化設定和模型格式,也相容於多種後端和硬體平台。這就像是萬能教練,無論你用什麼裝備,它都能幫你制定合適的訓練計畫。
LLMC的實際應用:讓AI更聰明、更節能
LLMC工具包的出現,為大型語言模型的量化提供了一個全面、公正的基準測試。它考慮了訓練資料、演算法和資料格式這三個關鍵因素,幫助使用者找到最佳的效能優化方案。
在實際應用中,LLMC可以幫助研究者和開發者更有效率地整合合適的演算法和低位元格式,推動大型語言模型的壓縮普及。這意味著,未來我們可能會看到更多輕量級但同樣強大的AI應用。
論文的作者們也分享了一些有趣的發現和建議:
選擇訓練資料時,應該選擇與測試資料在詞彙分佈上更相似的資料集,就像人類減肥要根據自身情況選擇合適的食譜一樣。
在量化演算法方面,他們探討了轉換、裁剪和重建三種主要技術的影響,就像是比較了不同的運動方式對減肥的效果。
在選擇整數還是浮點數量化時,他們發現浮點量化在處理複雜情況時更有優勢,而在某些特殊情況下,整數量化可能會更好。這就像是在不同的減重階段,需要採用不同的運動強度。
LLMC工具包的問世,為AI領域帶來了一股新風。它不僅為研究者和開發者提供了一個強大的助手,也為AI的未來發展指明了方向。透過LLMC,我們可以期待看到更多輕量級、高效能的AI應用,讓AI真正走進我們的日常生活。
專案地址:https://github.com/ModelTC/llmc
論文網址:https://arxiv.org/pdf/2405.06001
總而言之,LLMC工具包為解決大型語言模型的資源消耗問題提供了一個有效的解決方案,它不僅降低了模型運行的成本和門檻,也提升了模型的效率和可用性,為AI的普及和發展注入了新的活力。未來,我們可以期待更多基於LLMC的輕量級AI應用出現,為我們的生活帶來更多便利。