Meta訓練Llama 3.1大型語言模式的經歷,為我們展現了AI發展中前所未有的挑戰與機會。 16384塊GPU的龐大集群,在54天的訓練週期內,平均每3小時就發生一次故障,這不僅凸顯了AI模型規模的快速增長,也暴露了超算系統穩定性方面的巨大瓶頸。本文將深入探討Meta在Llama 3.1訓練過程中所遇到的挑戰,以及他們為因應這些挑戰所採取的策略,並分析其對整個AI產業帶來的啟示。
在人工智慧的世界裡,每一次突破都伴隨著令人瞠目結舌的數據。想像一下,16384塊GPU同時運轉,這不是科幻電影裡的場景,而是Meta公司在訓練最新Llama3.1模型時的真實寫照。然而,在這場技術盛宴的背後,隱藏著平均每3小時就會發生一次的故障。這個驚人的數字,不僅展示了AI發展的速度,也暴露了當前技術面臨的巨大挑戰。
從Llama1使用的2028塊GPU,到Llama3.1的16384塊,這個跨越式的增長不僅是數量上的變化,更是對現有超算系統穩定性的極限挑戰。 Meta的研究數據顯示,在Llama3.1的54天訓練週期裡,共發生了419次意外組件故障,其中約一半與H100GPU及其HBM3記憶體相關。這個數據讓我們不得不思考:在追求AI性能突破的同時,系統的可靠性是否也同步提升了?
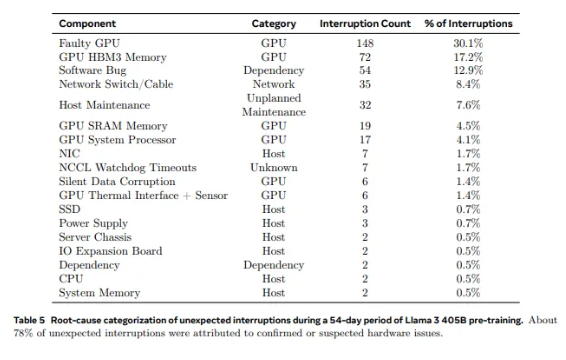
事實上,在超算領域有一個不爭的事實:規模越大,故障就越難以避免。 Meta的Llama3.1訓練集群由成千上萬的處理器、數十萬個其他晶片和數百英里的電纜組成,其複雜程度堪比一座小型城市的神經網路。在這樣的龐然大物中,故障似乎成了家常便飯。
面對頻繁的故障,Meta團隊並沒有束手無策。他們採取了一系列應對策略:減少作業啟動和檢查點時間,開發專有的診斷工具,利用PyTorch的NCCL飛行記錄器等。這些措施不僅提高了系統的容錯能力,也增強了自動化處理能力。 Meta的工程師們就像現代版的消防員,隨時準備撲滅可能影響訓練進程的火情。
然而,挑戰不僅來自硬體本身。環境因素和功耗波動也為超算集群帶來了意想不到的考驗。 Meta團隊發現,溫度的晝夜變化和GPU功耗的劇烈波動,都會對訓練表現產生顯著影響。這項發現提醒我們,在追求技術突破的同時,也不能忽視環境和能耗管理的重要性。
Llama3.1的訓練過程,堪稱是超算系統穩定性與可靠性的極限測試。 Meta團隊面對挑戰所採取的應對策略和開發的自動化工具,為整個AI產業提供了寶貴的經驗和啟示。儘管困難重重,但我們有理由相信,隨著技術的不斷進步,未來的超算系統將會更加強大和穩定。
在這個AI技術快速發展的時代,Meta的嘗試無疑是一次勇敢的冒險。它不僅推動了AI模型的性能邊界,也為我們展示了在追求極限過程中所面臨的真實挑戰。讓我們期待AI技術帶來的無限可能,同時也為那些在技術前沿不懈奮鬥的工程師們點讚。他們的每一次嘗試、每一次失敗、每一次突破,都在為人類的科技進步鋪路。
參考資料:
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training- one-failure-every-three-hours-for-metas-16384-gpu-training-cluster
Llama 3.1的訓練案例為我們提供了寶貴的經驗教訓,也指明了未來超算系統發展方向:在追求性能的同時,必須高度重視系統穩定性和可靠性,並積極探索應對各種故障的策略。這樣,才能確保AI技術持續穩定發展,造福人類。