Nvidia AI 最新发布的 ChatQA2 模型,在长文本上下文理解和检索增强生成 (RAG) 领域取得了显著突破。它基于强大的 Llama3 模型,通过扩展上下文窗口至 128K tokens 并采用三阶段指令微调,显著提升了指令遵循能力、RAG 性能和长文本理解能力。ChatQA2 在处理海量文本数据时,能够保持上下文连贯性和高召回率,并在多个基准测试中展现出与 GPT-4-Turbo 相媲美的性能,甚至在某些方面超越了它。 这标志着大型语言模型在处理长文本方面取得了重大进展。
性能突破:ChatQA2通过将上下文窗口扩展到128K tokens,并采用三阶段指令调整过程,显著提升了指令遵循能力、RAG性能和长文本理解。这一技术突破使得模型在处理长达10亿tokens的数据集时,能够保持上下文的连贯性和高召回率。
技术细节:ChatQA2的开发采用了详尽且可复现的技术方案。模型首先通过持续预训练,将Llama3-70B的上下文窗口从8K扩展到128K tokens。接着,应用了三个阶段的指令调整过程,确保模型能够有效处理各种任务。
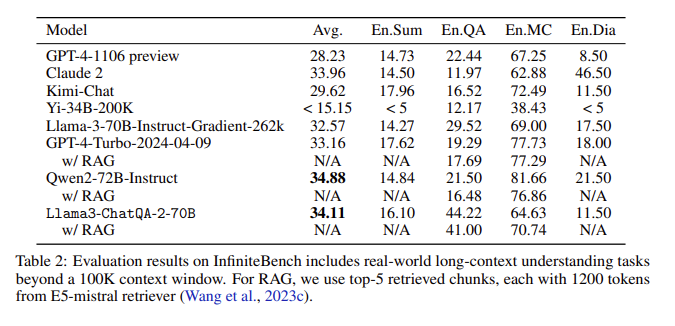
评估结果:在InfiniteBench评估中,ChatQA2在长文本总结、问答、多项选择和对话等任务上取得了与GPT-4-Turbo-2024-0409相媲美的准确性,并在RAG基准测试中超越了它。这一成绩凸显了ChatQA2在不同上下文长度和功能上的全面能力。
解决关键问题:ChatQA2针对RAG流程中的关键问题,如上下文碎片化和低召回率,通过使用最先进的长文本检索器,提高了检索的准确性和效率。
通过扩展上下文窗口并实施三阶段指令调整过程,ChatQA2实现了与GPT-4-Turbo相当的长文本理解和RAG性能。这一模型为各种下游任务提供了灵活的解决方案,通过先进的长文本和检索增强生成技术,平衡了准确性和效率。
论文入口:https://arxiv.org/abs/2407.14482
ChatQA2的出现为长文本处理和RAG应用带来了新的可能性,其高效性和准确性为未来人工智能的发展提供了重要的参考价值。 该模型的开放研究也促进了学术界和工业界的合作,推动了该领域的持续进步。 期待未来看到更多基于此模型的创新应用。