Llama 3.1,這個擁有4050億參數的巨型開源語言模型,在未經官方發布的情況下,因洩漏事件而引發了AI領域的巨大震動。其效能之強大,甚至在某些基準測試中超越了GPT-4o,為開源模型樹立了新的標竿。 Reddit上的熱烈討論,更是證明了其對AI社群的衝擊力。本文將深入探討Llama 3.1的性能、亮點以及安全措施,揭開這款神秘模型的面紗。
Llama3.1洩漏了!你沒聽錯,這個擁有4050億參數的開源模型,已經在Reddit上引起了軒然大波。這可能是迄今為止最接近GPT-4o的開源模型,甚至在某些方面超越了它。
Llama3.1是由Meta(原Facebook)開發的大型語言模型。雖然官方還沒有正式發布,但洩漏的版本已經在社區引起了轟動。這個模型不僅包含了基礎模型,還有8B、70B和最大參數的405B的基準測試結果。
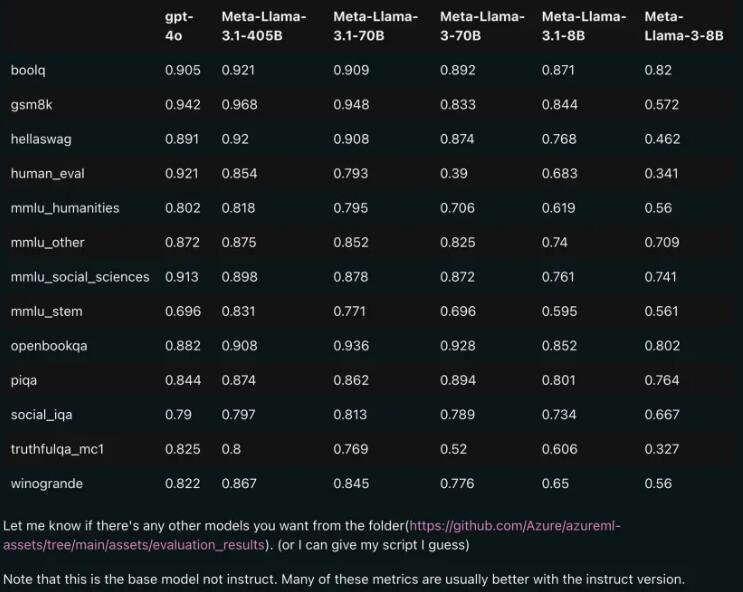
性能對比:Llama3.1vs GPT-4o
從洩漏的比較結果來看,即使是70B版本的Llama3.1,在多項基準測試上也超過了GPT-4o。這可是開源模型首次在多個benchmark上達到SOTA(State of the Art,即最先進的技術)水平,讓人不禁感嘆:開源的力量真是強大!
模型亮點:多語言支持,更豐富的訓練數據
Llama3.1模型使用了公開來源的15T+ tokens進行訓練,預訓練資料截止日期為2023年12月。它不僅支援英語,還包括法語、德語、印地語、義大利語、葡萄牙語、西班牙語和泰語等多種語言。這讓它在多語言對話用例中表現出色。

Llama3.1研究團隊非常重視模型的安全性。他們採用了多方面數據收集方法,結合人工生成數據與合成數據,以減輕潛在的安全風險。此外,模型還引入了邊界prompt和對抗性prompt,以增強資料品質控制。
模型卡來源:https://pastebin.com/9jGkYbXY#google_vignette
Llama 3.1的洩露,無疑將對AI領域產生深遠的影響。它不僅展示了開源模型的巨大潛力,也引發了對模型安全性和倫理問題的進一步思考。未來,我們將持續關注Llama 3.1及其後續發展,期待其為AI技術進步帶來更多驚喜。