NaturalSpeech2
v1.0
naturalspeech2 github. Recently, Microsoft announced that it will launch a new large model: NaturalSpeech2. Compared with previous large models, NaturalSpeech2 speech reconstruction is "more accurate", will not "stick to read", and can bring users a better experience and Serve.
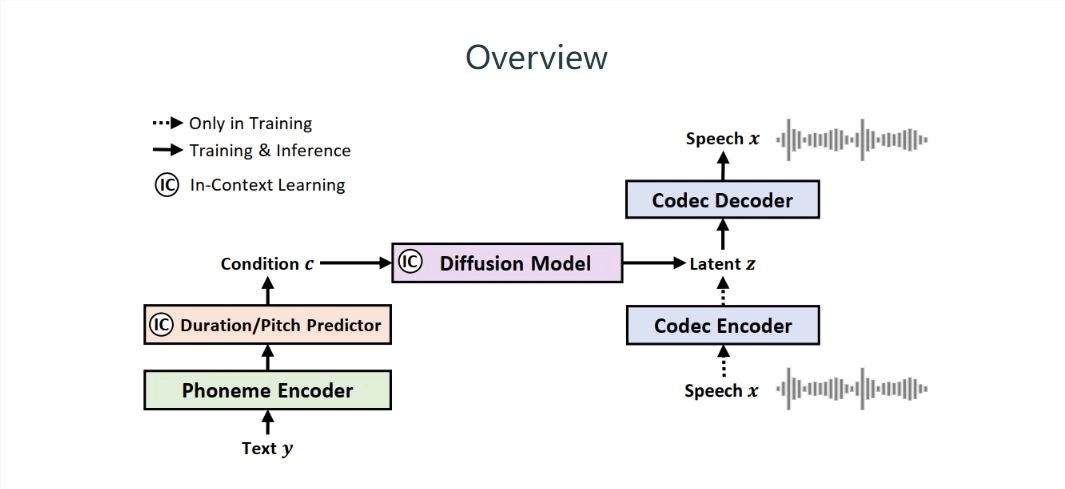
Microsoft recently launched a speech model called NaturalSpeech2. This model adopts a "potential diffusion" design and has outstanding results at the zero-sample speech synthesis level. Microsoft claims that the model provides a "commercial-grade" speech/singing solution that can Give users a high-quality and diverse speech synthesis experience.
Microsoft conducted a series of demonstrations of NaturalSpeech2, demonstrating its ability to generate speech with different speaker identities, prosody, and styles (such as singing) in zero-sample situations.
It is reported that, unlike traditional speech-to-text (TTS) systems, Microsoft's NaturalSpeech2 uses "continuous vectors" instead of "discrete markers" to represent speech, thereby generating more complete speech segments and not producing "stick reading" that is "devoid of emotion". (Speaking word by word)" phenomenon.
Experimental results show that the speech generated by NaturalSpeech2 under zero-sample conditions is nearly consistent with the prosody of speech prompts and real speech, and the naturalness (measured by CMOS) on the LibriTTS and VCTK test sets is indistinguishable from real speech.
The paper for this project is currently published on GitHub
1. Large model officially launched by Microsoft
2. It will bring many rich new interactions to players.
3. Currently under intense development, please stay tuned.