مستودع البيانات التحليلية Apache Kylin v4.0.3 النسخة الرسمية
4.0.3
Apache Kylin: أداة استعلام دون الثانية للبيانات واسعة النطاق للغاية
محرر الكود الهابط
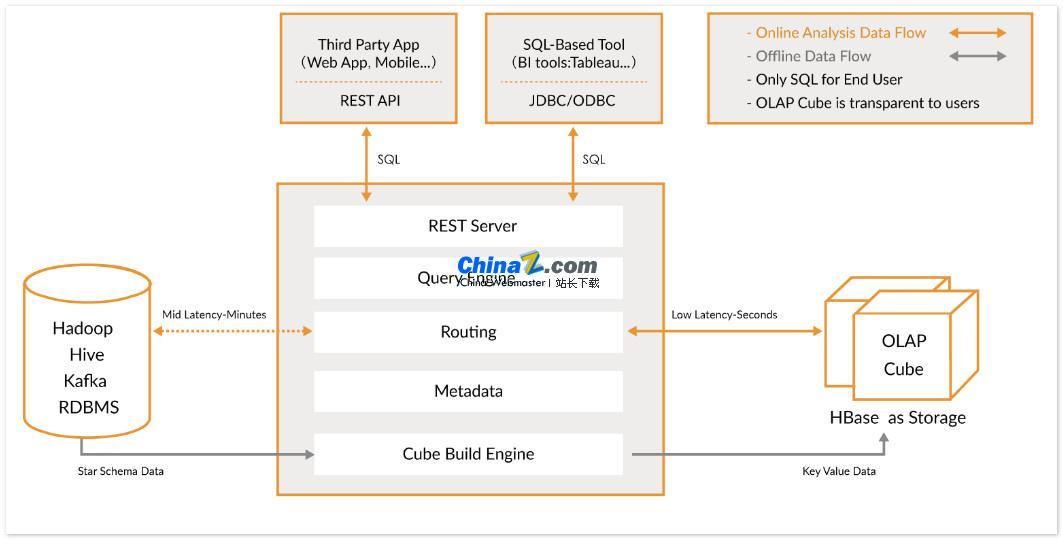
Apache Kylin هو مستودع بيانات تحليلية مفتوح المصدر وموزع يوفر واجهة استعلام SQL وإمكانيات التحليل متعدد الأبعاد (OLAP) بالإضافة إلى Hadoop/Spark، ويمكنه معالجة البيانات واسعة النطاق بكفاءة. تم تطويره في الأصل بواسطة eBay وساهم في مجتمع المصادر المفتوحة، وهو يكمل الاستعلامات حول البيانات الضخمة في ثوانٍ فرعية.
خطوات كيلين الثلاث الرئيسية
يتيح Kylin للمستخدمين تنفيذ استعلامات فرعية على مجموعات بيانات كبيرة جدًا في ثلاث خطوات فقط:
1. حدد نموذج نجمة أو ندفة ثلج في مجموعة البيانات الخاصة بك: أولاً، تحتاج إلى تحديد نموذج نجمة أو ندفة ثلج لوصف مجموعة البيانات الخاصة بك. سيساعد هذا Kylin على فهم العلاقة بين البيانات وبالتالي تحسين أداء الاستعلام.
2. Build Cube: Build Cube في جدول البيانات المحدد هو الوحدة المخصصة لـ Kylin للحساب المسبق للبيانات وتخزينها، مما يمكن أن يحسن سرعة الاستعلام بشكل كبير.
3. استخدم استعلام SQL القياسي: استخدم بناء جملة SQL القياسي للاستعلام عن Cube من خلال ODBC أو JDBC أو RESTFUL API الذي يمكنه إرجاع نتائج الاستعلام في ثوانٍ فرعية.
قدرات التكامل في Kylin
يتكامل Kylin مع مجموعة متنوعة من أدوات تصور البيانات، مثل Tableau وPower BI وما إلى ذلك. يمكن للمستخدمين استخدام أدوات ذكاء الأعمال هذه لتحليل بيانات Hadoop وعرض رؤى البيانات بشكل مرئي.
تلخيص
تعد Apache Kylin أداة قوية يمكنها مساعدة المستخدمين على إكمال الاستعلامات المتعلقة ببيانات واسعة النطاق للغاية في ثوانٍ فرعية. إن سهولة الاستخدام وقابلية التوسع والكفاءة تجعله مثاليًا للتعامل مع تحليل البيانات واسعة النطاق.