ورقة بحثية: حول التعميم الصفري لنماذج الرؤية واللغة في وقت الاختبار: هل نحتاج حقًا إلى التعلم الفوري؟ .
المؤلفون: مكسيم زانيلا، إسماعيل بن عايد.
هذا هو مستودع GitHub الرسمي لأبحاثنا التي تم قبولها في CVPR '24. يقدم هذا العمل طريقة MeanShift Test-time Augmentation (MTA)، مع الاستفادة من نماذج لغة الرؤية دون الحاجة إلى التعلم الفوري. تعمل طريقتنا على زيادة صورة واحدة بشكل عشوائي إلى N طرق عرض معززة، ثم تتناوب بين خطوتين رئيسيتين (راجع mta.py والتفاصيل في قسم التعليمات البرمجية.):
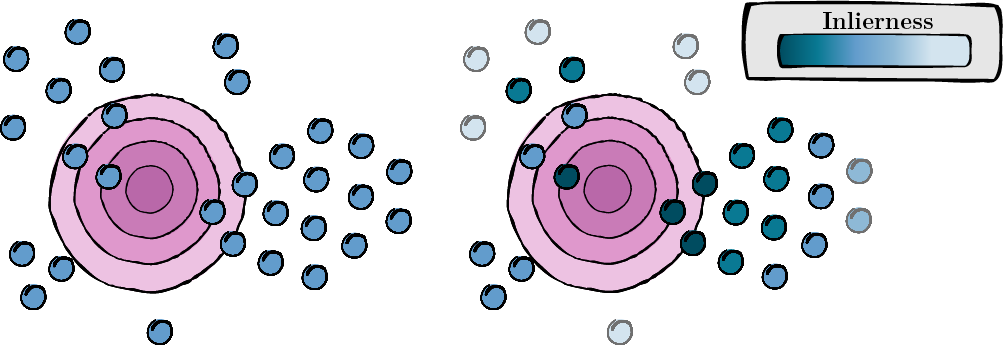
تتضمن هذه الخطوة حساب درجة لكل عرض معزز لتقييم مدى ملاءمته وجودته (درجة القصور).
الشكل 1: حساب النقاط لكل عرض معزز.
استنادا إلى الدرجات المحسوبة في الخطوة السابقة، فإننا نسعى إلى وضع نقاط البيانات (MeanShift).
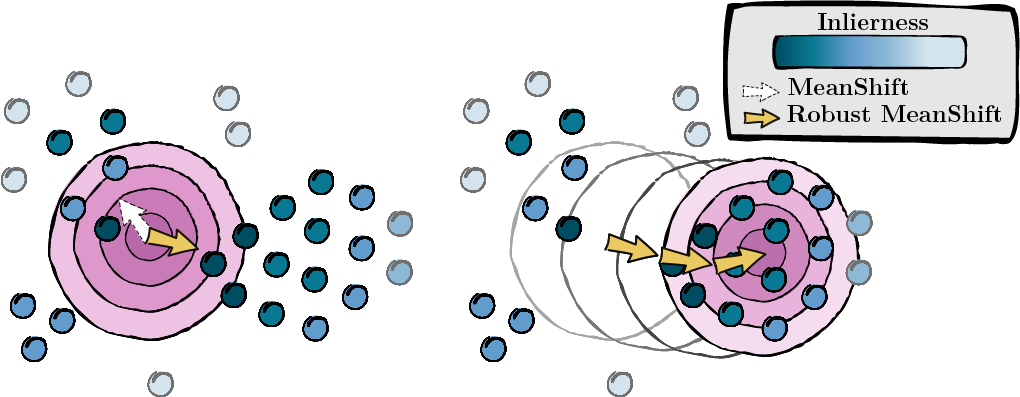
الشكل 2: البحث عن الوضع، مرجحًا بدرجات القصور الذاتي.
نحن نتبع تركيب TPT والمعالجة المسبقة. وهذا يضمن أن يتم تنسيق مجموعة البيانات الخاصة بك بشكل مناسب. يمكنك العثور على مستودعهم هنا. إذا كان الأمر أكثر ملاءمة، يمكنك تغيير أسماء المجلدات لكل مجموعة بيانات في القاموس ID_to_DIRNAME في data/datautils.py (السطر 20).
قم بتنفيذ MTA على مجموعة بيانات ImageNet باستخدام بذرة عشوائية تبلغ 1 ومطالبة "صورة لـ" عن طريق إدخال الأمر التالي:
python main.py --data /path/to/your/data --mta --testsets I --seed 1أو مجموعات البيانات الـ 15 مرة واحدة:
python main.py --data /path/to/your/data --mta --testsets I/A/R/V/K/DTD/Flower102/Food101/Cars/SUN397/Aircraft/Pets/Caltech101/UCF101/eurosat --seed 1مزيد من المعلومات حول الإجراء في mta.py.
gaussian_kernelsolve_mtay ) بشكل موحد.إذا وجدت هذا المشروع مفيدا، يرجى ذكره على النحو التالي:
@inproceedings { zanella2024test ,
title = { On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? } ,
author = { Zanella, Maxime and Ben Ayed, Ismail } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 23783--23793 } ,
year = { 2024 }
}نعرب عن امتناننا لمؤلفي TPT لمساهمتهم مفتوحة المصدر. يمكنك العثور على مستودعهم هنا.