واجهة ChatTTS على شبكة الإنترنت
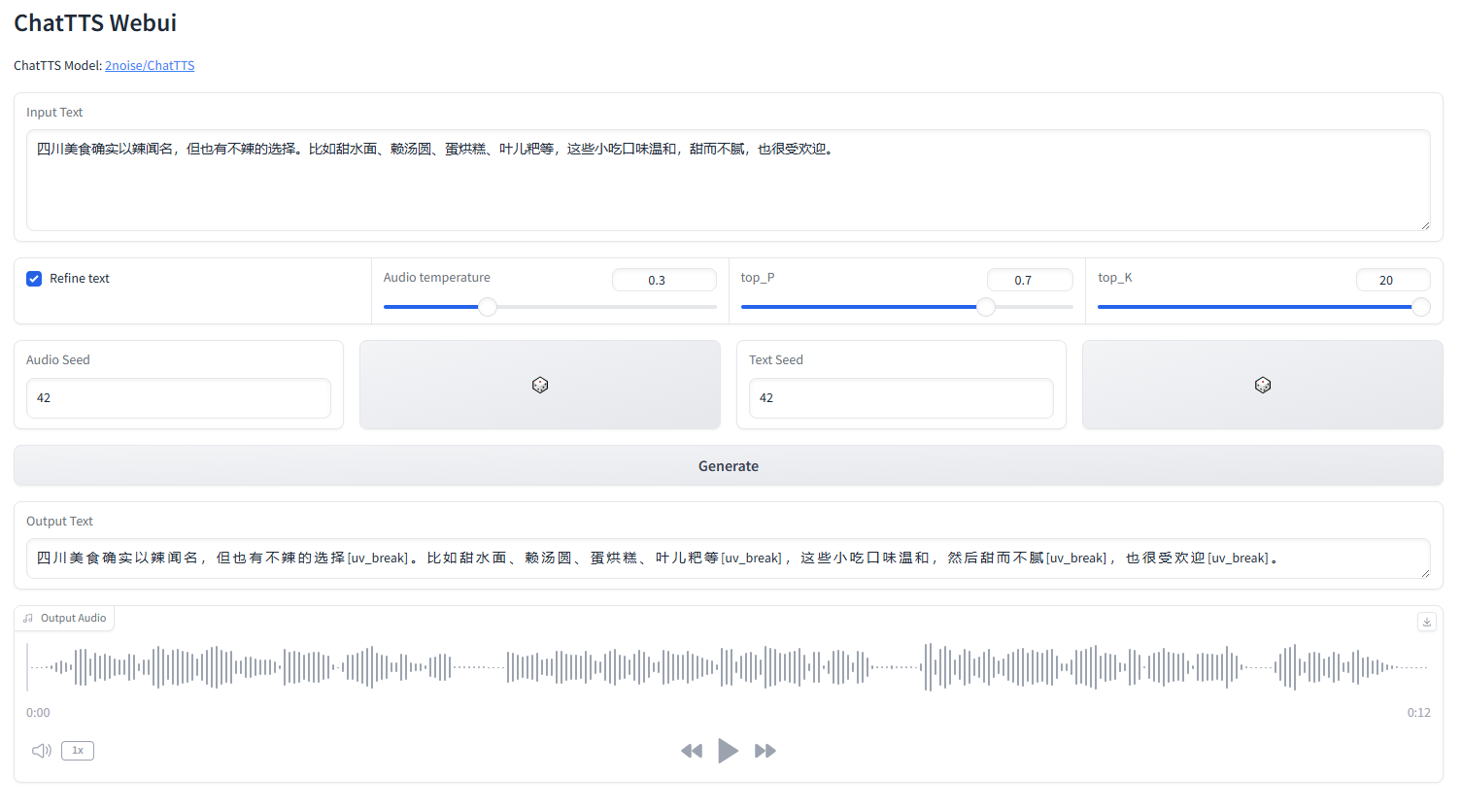
ابدأ تشغيل webui.py
python webui.py
python webui.py --server_port=8080conda create -n chattts python=3.9
conda activate chattts
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
pip install omegaconf vocos transformers vector-quantize-pytorchالإنجليزية |中文简体
ChatTTS هو نموذج تحويل النص إلى كلام مصمم خصيصًا لسيناريو الحوار مثل مساعد LLM. وهو يدعم اللغتين الإنجليزية والصينية. تم تدريب نموذجنا بأكثر من 100000 ساعة مكونة من اللغة الصينية والإنجليزية. الإصدار مفتوح المصدر على HuggingFace هو نموذج تم تدريبه مسبقًا لمدة 40000 ساعة بدون SFT.
للاستفسارات الرسمية حول النموذج وخريطة الطريق، يرجى الاتصال بنا على [email protected]. يمكنك الانضمام إلى مجموعة QQ الخاصة بنا: 808364215 للمناقشة. نرحب دائمًا بإضافة مشكلات جيثب.
للحصول على وصف تفصيلي للنموذج، يمكنك الرجوع إلى الفيديو على بيليبيلي
هذا الريبو للأغراض الأكاديمية فقط. إنه مخصص للاستخدام التعليمي والبحثي، ولا ينبغي استخدامه لأي أغراض تجارية أو قانونية. لا يضمن المؤلفون دقة المعلومات أو اكتمالها أو موثوقيتها. المعلومات والبيانات المستخدمة في هذا الريبو هي للأغراض الأكاديمية والبحثية فقط. البيانات التي تم الحصول عليها من مصادر متاحة للجمهور، ولا يطالب المؤلفون بأي ملكية أو حقوق طبع ونشر للبيانات.
ChatTTS هو نظام قوي لتحويل النص إلى كلام. ومع ذلك، من المهم جدًا استخدام هذه التكنولوجيا بطريقة مسؤولة وأخلاقية. للحد من استخدام ChatTTS، أضفنا كمية صغيرة من الضوضاء عالية التردد أثناء تدريب النموذج الذي يبلغ 40000 ساعة، وقمنا بضغط جودة الصوت قدر الإمكان باستخدام تنسيق MP3، لمنع الجهات الفاعلة الضارة من استخدامه المحتمل لأغراض إجرامية. الأغراض. وفي الوقت نفسه، قمنا بتدريب نموذج الكشف داخليًا ونخطط لفتح مصدره في المستقبل.
import ChatTTS
from IPython . display import Audio
chat = ChatTTS . Chat ()
chat . load_models ()
texts = [ "<PUT YOUR TEXT HERE>" ,]
wavs = chat . infer ( texts , use_decoder = True )
Audio ( wavs [ 0 ], rate = 24_000 , autoplay = True ) ###################################
# Sample a speaker from Gaussian.
import torch
std , mean = torch . load ( 'ChatTTS/asset/spk_stat.pt' ). chunk ( 2 )
rand_spk = torch . randn ( 768 ) * std + mean
params_infer_code = {
'spk_emb' : rand_spk , # add sampled speaker
'temperature' : .3 , # using custom temperature
'top_P' : 0.7 , # top P decode
'top_K' : 20 , # top K decode
}
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = {
'prompt' : '[oral_2][laugh_0][break_6]'
}
wav = chat . infer ( "<PUT YOUR TEXT HERE>" , params_refine_text = params_refine_text , params_infer_code = params_infer_code )
###################################
# For word level manual control.
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wav = chat . infer ( text , skip_refine_text = True , params_infer_code = params_infer_code ) inputs_en = """
chat T T S is a text to speech model designed for dialogue applications.
[uv_break]it supports mixed language input [uv_break]and offers multi speaker
capabilities with precise control over prosodic elements [laugh]like like
[uv_break]laughter[laugh], [uv_break]pauses, [uv_break]and intonation.
[uv_break]it delivers natural and expressive speech,[uv_break]so please
[uv_break] use the project responsibly at your own risk.[uv_break]
""" . replace ( ' n ' , '' ) # English is still experimental.
params_refine_text = {
'prompt' : '[oral_2][laugh_0][break_4]'
}
audio_array_cn = chat . infer ( inputs_cn , params_refine_text = params_refine_text )
audio_array_en = chat . infer ( inputs_en , params_refine_text = params_refine_text )للحصول على مقطع صوتي مدته 30 ثانية، يلزم توفر ذاكرة GPU سعة 4 جيجابايت على الأقل. بالنسبة لوحدة معالجة الرسومات 4090D، يمكنها إنشاء صوت يتوافق مع حوالي 7 رموز دلالية في الثانية. يبلغ عامل الوقت الحقيقي (RTF) حوالي 0.65.
هذه مشكلة تحدث عادةً مع نماذج الانحدار الذاتي (لللحاء والوادي). من الصعب عمومًا تجنبه. يمكن للمرء تجربة عينات متعددة للعثور على نتيجة مناسبة.
في النموذج الذي تم إصداره حاليًا، وحدات التحكم الوحيدة على مستوى الرمز المميز هي [laugh] و[uv_break] و[lbreak]. في الإصدارات المستقبلية، قد نفتح نماذج مفتوحة المصدر تتمتع بقدرات إضافية للتحكم في المشاعر.


