DeepKE
DeepKE 2.2.7
الإنجليزية | 简体中文
مجموعة أدوات استخلاص المعرفة المبنية على التعلم العميق
لبناء الرسم البياني المعرفي
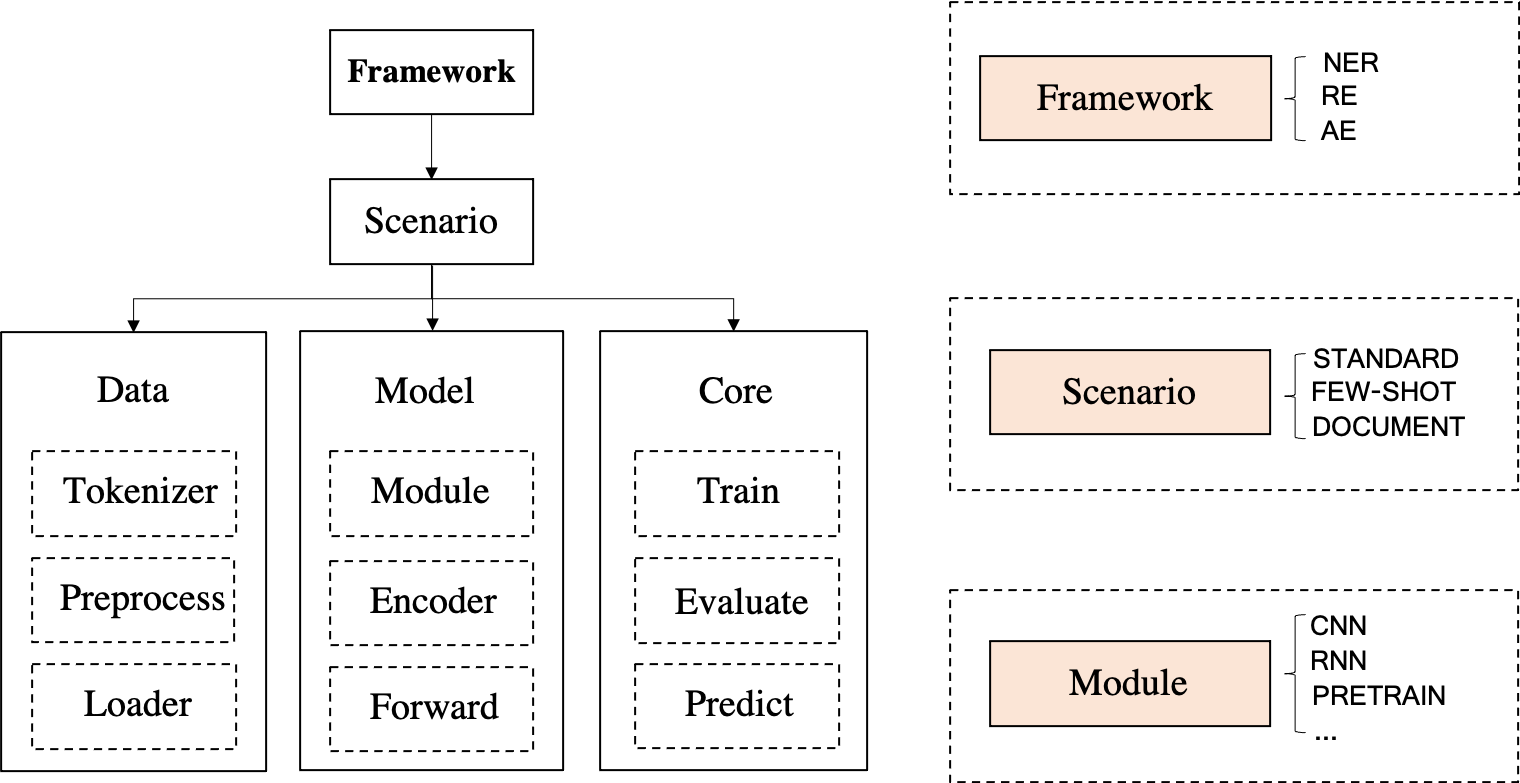
DeepKE عبارة عن مجموعة أدوات لاستخراج المعرفة لبناء الرسم البياني المعرفي الذي يدعم سيناريوهات cnSchema منخفضة الموارد وعلى مستوى المستند ومتعددة الوسائط لاستخراج الكيان والعلاقات والسمات . نحن نقدم المستندات والعروض التوضيحية عبر الإنترنت والورق والشرائح والملصقات للمبتدئين.
\ في مسارات الملفات؛wisemodel أو modescape .إذا واجهت أي مشكلات أثناء تثبيت DeepKE وDeepKE-LLM، فيرجى التحقق من النصائح أو إرسال مشكلة على الفور، وسنساعدك في حل المشكلة!
April, 2024 قمنا بإصدار نموذج جديد لاستخراج المعلومات قائم على المخطط ثنائي اللغة (الصينية والإنجليزية) يسمى OneKE استنادًا إلى Chinese-Alpaca-2-13B.Feb, 2024 قمنا بإصدار مجموعة بيانات تعليمات استخلاص المعلومات (IE) عالية الجودة (0.32 مليار رمز) ثنائية اللغة (الصينية والإنجليزية) عالية الجودة باسم IEPile، إلى جانب نموذجين مدربين على IEPile وbaichuan2-13b-iepile-lora وllama2 -13ب-إيبيل-لورا.Sep 2023 تم إصدار مجموعة بيانات تعليمات ثنائية اللغة الصينية الإنجليزية لاستخراج المعلومات (IE) تسمى InstructIE لمهمة إنشاء الرسم البياني المعرفي القائم على التعليمات (KGC القائمة على التعليمات)، كما هو مفصل هنا.June, 2023 نقوم بتحديث DeepKE-LLM لدعم استخراج المعرفة باستخدام KnowLM وChatGLM وLLaMA-series وGPT-series وما إلى ذلك.Apr, 2023 لقد أضفنا نماذج جديدة، بما في ذلك CP-NER(IJCAI'23)، وASP(EMNLP'22)، وPRGC(ACL'21)، وPURE(NAACL'21)، وتوفير إمكانات استخراج الأحداث (الصينية والإنجليزية)، وعرضت التوافق مع الإصدارات الأعلى من حزم بايثون (مثل المحولات).Feb, 2023 لقد دعمنا استخدام LLM (GPT-3) مع التعلم في السياق (استنادًا إلى EasyInstruct) وتوليد البيانات، وأضفنا نموذج NER W2NER (AAAI'22). Nov, 2022 إضافة تعليمات التعليقات التوضيحية للبيانات للتعرف على الكيانات واستخراج العلاقات، ووضع العلامات التلقائية على البيانات ضعيفة الإشراف (استخراج الكيانات واستخراج العلاقات)، وتحسين التدريب على وحدات معالجة الرسومات المتعددة.
Sept, 2022 تم قبول الورقة DeepKE: مجموعة أدوات استخلاص المعرفة القائمة على التعلم العميق لقاعدة المعرفة من قبل المسار التوضيحي لنظام EMNLP 2022.
Aug, 2022 لقد أضفنا دعمًا لزيادة البيانات (الصينية والإنجليزية) لاستخراج العلاقات منخفضة الموارد.
June, 2022 لقد أضفنا دعمًا متعدد الوسائط لاستخراج الكيانات والعلاقات.
May, 2022 لقد أصدرنا مخطط DeepKE-cn مع نماذج استخلاص المعرفة الجاهزة.
Jan, 2022 لقد أصدرنا ورقة DeepKE: مجموعة أدوات استخلاص المعرفة القائمة على التعلم العميق لقاعدة المعرفة
Dec, 2021 لقد أضفنا dockerfile لإنشاء البيئة تلقائيًا.
Nov, 2021 تم إصدار العرض التوضيحي لـ DeepKE، الذي يدعم الامتداد في الوقت الفعلي دون النشر والتدريب.
تم إصدار وثائق DeepKE، التي تحتوي على تفاصيل DeepKE مثل أكواد المصدر ومجموعات البيانات.
Oct, 2021 pip install deepke
تم إصدار رموز Deepke-v2.0.
Aug, 2019 تم إصدار رموز Deepke-v1.0.
Aug, 2018 تم إطلاق مشروع بدء التشغيل DeepKE وأكواد Deepke-v0.1.
هناك دليل على التنبؤ. يتم إنشاء ملف GIF بواسطة Terminalizer. احصل على الرمز. 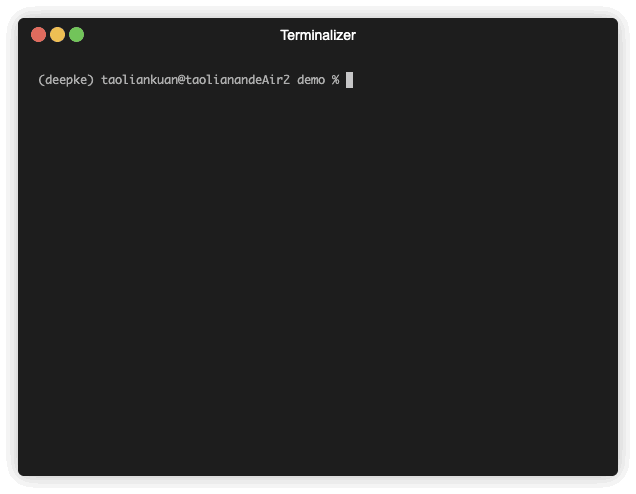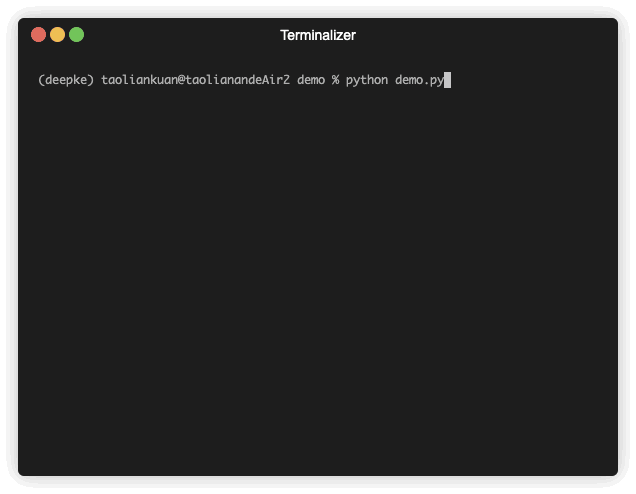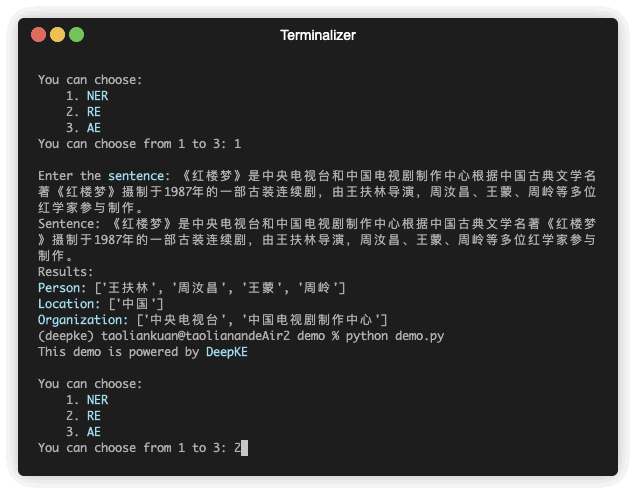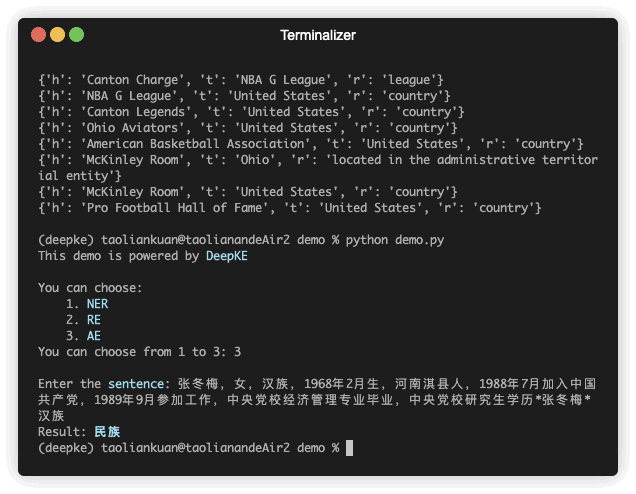
في عصر النماذج الكبيرة، يستخدم DeepKE-LLM تبعية جديدة تمامًا للبيئة.
conda create -n deepke-llm python=3.9
conda activate deepke-llm
cd example/llm
pip install -r requirements.txt
يرجى ملاحظة أن ملف requirements.txt موجود في المجلد example/llm .
pip install deepke .الخطوة 1 قم بتنزيل الكود الأساسي
git clone --depth 1 https://github.com/zjunlp/DeepKE.git الخطوة 2 قم بإنشاء بيئة افتراضية باستخدام Anaconda وأدخلها.
conda create -n deepke python=3.8
conda activate deepkeقم بتثبيت DeepKE باستخدام كود المصدر
pip install -r requirements.txt
python setup.py install
python setup.py develop تثبيت DeepKE pip ( غير مستحسن! )
pip install deepkeالخطوة 3 أدخل دليل المهام
cd DeepKE/example/re/standardالخطوة 4: قم بتنزيل مجموعة البيانات، أو اتبع تعليمات الشرح للحصول على البيانات
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gzيتم دعم العديد من أنواع تنسيقات البيانات، والتفاصيل موجودة في كل جزء.
التدريب على الخطوة 5 (يمكن تغيير معلمات التدريب في مجلد conf )
نحن ندعم ضبط المعلمات المرئية باستخدام wandb .
python run.py التنبؤ بالخطوة 6 (يمكن تغيير معلمات التنبؤ في مجلد conf )
قم بتعديل مسار النموذج المُدرب في predict.yaml . يجب استخدام المسار المطلق للنموذج، مثل xxx/checkpoints/2019-12-03_ 17-35-30/cnn_ epoch21.pth .
python predict.pyالخطوة 1: تثبيت عميل Docker
قم بتثبيت Docker وابدأ خدمة Docker.
الخطوة 2: اسحب صورة عامل الإرساء وقم بتشغيل الحاوية
docker pull zjunlp/deepke:latest
docker run -it zjunlp/deepke:latest /bin/bashالخطوات المتبقية هي نفس الخطوة 3 وما بعدها في تكوين البيئة اليدوي .
بيثون == 3.8
يسعى التعرف على الكيانات المسماة إلى تحديد وتصنيف الكيانات المسماة المذكورة في النص غير المنظم إلى فئات محددة مسبقًا مثل أسماء الأشخاص والمنظمات والمواقع والمنظمات وما إلى ذلك.
يتم تخزين البيانات في ملفات .txt . بعض الحالات على النحو التالي (يمكن للمستخدمين تصنيف البيانات بناءً على الأدوات Doccano، أو MarkTool، أو يمكنهم استخدام الإشراف الضعيف مع DeepKE للحصول على البيانات تلقائيًا):
| جملة | شخص | موقع | منظمة |
|---|---|---|---|
| رقم 9 في 4 أيام من اليوم هو يوم العمل: أفضل وقت في العمل قد يكون من الأفضل أن تكون في 9 أيام من 3 أيام إلى 4 أيام من 4 أيام. | جديد | جديد | 人民日报 |
| """""""""""""""""""""""""""""""""" | 王扶林,周汝昌,王蒙,周岭 | ||
| لا داعي للقلق بشأن هذا الأمر. | بالتأكيد | 陕西省، 安市 |
اقرأ العملية التفصيلية في ملف README المحدد
قياسي (إشراف كامل)
نحن ندعم LLM ونوفر النموذج الجاهز DeepKE-cnSchema-NER، والذي سيستخرج الكيانات في cnSchema دون تدريب.
الخطوة 1 أدخل DeepKE/example/ner/standard . قم بتنزيل مجموعة البيانات.
wget 120.27.214.45/Data/ner/standard/data.tar.gz
tar -xzvf data.tar.gz تدريب الخطوة 2
يمكن تخصيص مجموعة البيانات والمعلمات في مجلد data ومجلد conf على التوالي.
python run.pyالتنبؤ الخطوة 3
python predict.pyطلقات قليلة
الخطوة 1 أدخل DeepKE/example/ner/few-shot . قم بتنزيل مجموعة البيانات.
wget 120.27.214.45/Data/ner/few_shot/data.tar.gz
tar -xzvf data.tar.gz الخطوة 2: التدريب في بيئة منخفضة الموارد
الدليل الذي يتم فيه تحميل النموذج وحفظه ويمكن تخصيص معلمات التكوين في مجلد conf .
python run.py +train=few_shot يمكن للمستخدمين تعديل load_path في conf/train/few_shot.yaml لاستخدام النموذج المحمّل الحالي.
الخطوة 3 أضف - predict إلى conf/config.yaml ، وقم بتعديل loda_path كمسار للنموذج و write_path كمسار حيث يتم حفظ النتائج المتوقعة في conf/predict.yaml ، ثم قم بتشغيل python predict.py
python predict.pyمتعدد الوسائط
الخطوة 1 أدخل DeepKE/example/ner/multimodal . قم بتنزيل مجموعة البيانات.
wget 120.27.214.45/Data/ner/multimodal/data.tar.gz
tar -xzvf data.tar.gzنحن نستخدم كائنات RCNN المكتشفة وكائنات التأريض المرئية من الصور الأصلية كمعلومات محلية مرئية، حيث يتم استخدام RCNN عبر fast_rcnn والتأريض المرئي عبر onestage_grounding.
الخطوة 2 التدريب في بيئة الوسائط المتعددة
data ومجلد conf على التوالي.load_path في conf/train.yaml باعتباره المسار الذي تم حفظ النموذج الذي تم تدريبه فيه آخر مرة. ويمكن تخصيص سجلات حفظ المسار التي تم إنشاؤها في التدريب بواسطة log_dir . python run.pyالتنبؤ الخطوة 3
python predict.pyاستخراج العلاقة هو مهمة استخراج العلاقات الدلالية بين الكيانات من نص غير منظم.
يتم تخزين البيانات في ملفات .csv . بعض الحالات على النحو التالي (يمكن للمستخدمين تصنيف البيانات بناءً على الأدوات Doccano، أو MarkTool، أو يمكنهم استخدام الإشراف الضعيف مع DeepKE للحصول على البيانات تلقائيًا):
| جملة | علاقة | رأس | Head_offset | ذيل | Tail_offset |
|---|---|---|---|---|---|
| يمكن أن تكون هذه هي المرة الأولى التي يتم فيها استخدام هذه التقنية. | 导演 | 父也是爹 | 1 | 王军 | 8 |
| "يبدو أن هذا هو ما يحدث في كل مكان." | 连载网站 | 玄珠 | 1 | 纵横中文网 | 7 |
| لا داعي للقلق بشأن هذا الأمر. | 所在城市 | 西湖 | 8 | 杭州 | 2 |
!ملاحظة: إذا كان هناك أنواع كيانات متعددة لعلاقة واحدة، فيمكن إضافة أنواع الكيانات إلى العلاقة كمدخلات.
اقرأ العملية التفصيلية في ملف README المحدد
قياسي (إشراف كامل)
نحن ندعم LLM ونوفر النموذج الجاهز DeepKE-cnSchema-RE، والذي سيستخرج العلاقات في cnSchema دون تدريب.
الخطوة 1 أدخل المجلد DeepKE/example/re/standard . قم بتنزيل مجموعة البيانات.
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz تدريب الخطوة 2
يمكن تخصيص مجموعة البيانات والمعلمات في مجلد data ومجلد conf على التوالي.
python run.pyالتنبؤ الخطوة 3
python predict.pyطلقات قليلة
الخطوة 1 أدخل DeepKE/example/re/few-shot . قم بتنزيل مجموعة البيانات.
wget 120.27.214.45/Data/re/few_shot/data.tar.gz
tar -xzvf data.tar.gz الخطوة 2 التدريب
data ومجلد conf على التوالي.train_from_saved_model في conf/train.yaml باعتباره المسار الذي تم حفظ النموذج الذي تم تدريبه فيه في المرة الأخيرة. ويمكن تخصيص سجلات حفظ المسار التي تم إنشاؤها في التدريب بواسطة log_dir . python run.pyالتنبؤ الخطوة 3
python predict.py وثيقة
الخطوة 1 أدخل DeepKE/example/re/document . قم بتنزيل مجموعة البيانات.
wget 120.27.214.45/Data/re/document/data.tar.gz
tar -xzvf data.tar.gz تدريب الخطوة 2
data ومجلد conf على التوالي.train_from_saved_model في conf/train.yaml باعتباره المسار الذي تم حفظ النموذج الذي تم تدريبه فيه في المرة الأخيرة. ويمكن تخصيص سجلات حفظ المسار التي تم إنشاؤها في التدريب بواسطة log_dir . python run.pyالتنبؤ الخطوة 3
python predict.pyمتعدد الوسائط
الخطوة 1 أدخل DeepKE/example/re/multimodal . قم بتنزيل مجموعة البيانات.
wget 120.27.214.45/Data/re/multimodal/data.tar.gz
tar -xzvf data.tar.gzنحن نستخدم كائنات RCNN المكتشفة وكائنات التأريض المرئية من الصور الأصلية كمعلومات محلية مرئية، حيث يتم استخدام RCNN عبر fast_rcnn والتأريض المرئي عبر onestage_grounding.
تدريب الخطوة 2
data ومجلد conf على التوالي.load_path في conf/train.yaml باعتباره المسار الذي تم حفظ النموذج الذي تم تدريبه فيه آخر مرة. ويمكن تخصيص سجلات حفظ المسار التي تم إنشاؤها في التدريب بواسطة log_dir . python run.pyالتنبؤ الخطوة 3
python predict.pyاستخراج السمات هو استخراج سمات للكيانات في نص غير منظم.
يتم تخزين البيانات في ملفات .csv . بعض الحالات على النحو التالي:
| جملة | أت | الأنف والحنجرة | Ent_offset | فال | Val_offset |
|---|---|---|---|---|---|
| 张冬梅,女,汉族,1968年2月生,河南淇县人 | 民族 | 张冬梅 | 0 | 汉族 | 6 |
| في هذه الحالة، قد يكون من الصعب على أي شخص أن يفعل ذلك. | جديد | هذا هو | 0 | 三国时期 | 8 |
| 10 نوفمبر 2014 1 مايو 2014 | 上映时间 | 黄金时代 | 19 | 2014 10 نوفمبر 1 | 0 |
اقرأ العملية التفصيلية في ملف README المحدد
قياسي (إشراف كامل)
الخطوة 1 أدخل المجلد DeepKE/example/ae/standard . قم بتنزيل مجموعة البيانات.
wget 120.27.214.45/Data/ae/standard/data.tar.gz
tar -xzvf data.tar.gz تدريب الخطوة 2
يمكن تخصيص مجموعة البيانات والمعلمات في مجلد data ومجلد conf على التوالي.
python run.pyالتنبؤ الخطوة 3
python predict.py.tsv ، بعض الحالات هي كما يلي:| جملة | نوع الحدث | مشغل | دور | دعوى | |
|---|---|---|---|---|---|
| قد يكون من المفيد الحصول على 27 يومًا من موعد التسليم لا داعي للقلق بشأن هذا الأمر. | 组织行为-罢工 | 罢工 | 罢工人员 | 法国巴黎卢浮宫博物馆员工 | |
| 时间 | 当地时间27日 | ||||
| شكرا جزيلا | 法国巴黎卢浮宫博物馆 | ||||
| لقد حققت أرباح 2019 في عام 2019 نجاحًا بنسبة 17٪: لقد حققت نجاحًا كبيرًا | 财经/交易-出售/收购 | 收购 | 出售方 | شكرا جزيلا | |
| 收购方 | في الحقيقة | ||||
| 交易物 | شكرا جزيلا | ||||
| يجب أن يكون لديك 13 يومًا من أفضل المنتجات في العالم، لا داعي للقلق بشأن هذا الأمر. | 灾害/意外-坠机 | جديد | 时间 | 13 يوم | |
| شكرا جزيلا | 美国亚特兰 | ||||
اقرأ العملية التفصيلية في ملف README المحدد
قياسي (إشراف كامل)
الخطوة 1 أدخل المجلد DeepKE/example/ee/standard . قم بتنزيل مجموعة البيانات.
wget 120.27.214.45/Data/ee/DuEE.zip
unzip DuEE.zipالخطوة 2 التدريب
يمكن تخصيص مجموعة البيانات والمعلمات في مجلد data ومجلد conf على التوالي.
python run.pyالخطوة 3 التنبؤ
python predict.py 1. سيؤدي Using nearest mirror ، الخميس في الصين، إلى تسريع عملية تثبيت Anaconda ؛ aliyun في الصين، سوف يسرع pip install XXX .
2. عند مواجهة ModuleNotFoundError: No module named 'past' ، قم بتشغيل pip install future .
3. إنه بطيء في تثبيت نماذج اللغة المدربة مسبقًا عبر الإنترنت. يوصى بتنزيل النماذج المُدربة مسبقًا قبل الاستخدام وحفظها في المجلد pretrained . اقرأ README.md في كل دليل مهام للتحقق من المتطلبات المحددة لحفظ النماذج المدربة مسبقًا.
4. الإصدار القديم من DeepKE موجود في فرع Deepke-v1.0. يمكن للمستخدمين تغيير الفرع لاستخدام الإصدار القديم. تم نقل الإصدار القديم بالكامل إلى استخراج العلاقة القياسية (مثال/إعادة/معيار).
5. إذا كنت تريد تعديل كود المصدر، فمن المستحسن تثبيت DeepKE مع أكواد المصدر. إذا لم يكن الأمر كذلك، فإن التعديل لن يعمل. انظر القضية
6. يمكن العثور على المزيد من أعمال استخلاص المعرفة ذات الموارد المنخفضة في استخلاص المعرفة في سيناريوهات الموارد المنخفضة: المسح والمنظور.
7. تأكد من الإصدارات الدقيقة للمتطلبات في requirements.txt .
في الإصدار التالي، نخطط لإصدار LLM أقوى لـ KE.
وفي الوقت نفسه، سنقدم صيانة طويلة الأمد لإصلاح الأخطاء وحل المشكلات وتلبية الطلبات الجديدة . لذلك إذا كان لديك أي مشاكل، يرجى طرح القضايا علينا.
إنشاء الرسم البياني للمعرفة بكفاءة البيانات، 高效知识图谱构建 (برنامج تعليمي حول CCKS 2022) [الشرائح]
إنشاء رسم بياني معرفي فعال وقوي (برنامج تعليمي حول AACL-IJCNLP 2022) [الشرائح]
عائلة PromptKG: معرض للتعلم السريع والأعمال البحثية المتعلقة بمرحلة رياض الأطفال ومجموعات الأدوات وقائمة الأوراق [الموارد]
استخلاص المعرفة في سيناريوهات الموارد المنخفضة: المسح والمنظور [مسح] [قائمة الأوراق]
Doccano، MarkTool، LabelStudio: مجموعة أدوات التعليقات التوضيحية للبيانات
LambdaKG: مكتبة ومعيار لتضمينات KG المستندة إلى PLM
EasyInstruct: إطار عمل سهل الاستخدام لتعليم نماذج اللغات الكبيرة
مواد القراءة :
إنشاء الرسم البياني للمعرفة بكفاءة البيانات، 高效知识图谱构建 (برنامج تعليمي حول CCKS 2022) [الشرائح]
إنشاء رسم بياني معرفي فعال وقوي (برنامج تعليمي حول AACL-IJCNLP 2022) [الشرائح]
عائلة PromptKG: معرض للتعلم السريع والأعمال البحثية المتعلقة بمرحلة رياض الأطفال ومجموعات الأدوات وقائمة الأوراق [الموارد]
استخلاص المعرفة في سيناريوهات الموارد المنخفضة: المسح والمنظور [مسح] [قائمة الأوراق]
مجموعة الأدوات ذات الصلة :
Doccano، MarkTool، LabelStudio: مجموعة أدوات التعليقات التوضيحية للبيانات
LambdaKG: مكتبة ومعيار لتضمينات KG المستندة إلى PLM
EasyInstruct: إطار عمل سهل الاستخدام لتعليم نماذج اللغات الكبيرة
يرجى الاستشهاد بورقتنا إذا كنت تستخدم DeepKE في عملك
@inproceedings { EMNLP2022_Demo_DeepKE ,
author = { Ningyu Zhang and
Xin Xu and
Liankuan Tao and
Haiyang Yu and
Hongbin Ye and
Shuofei Qiao and
Xin Xie and
Xiang Chen and
Zhoubo Li and
Lei Li } ,
editor = { Wanxiang Che and
Ekaterina Shutova } ,
title = { DeepKE: {A} Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population } ,
booktitle = { {EMNLP} (Demos) } ,
pages = { 98--108 } ,
publisher = { Association for Computational Linguistics } ,
year = { 2022 } ,
url = { https://aclanthology.org/2022.emnlp-demos.10 }
}نينغيو تشانغ، هاوفن وانغ، فاي هوانغ، فييو شيونغ، ليانكوان تاو، شين شو، هونغهاو غوي، زينرو تشانغ، تشوانكي تان، تشيانغ تشن، شياوهان وانغ، زيكون شي، زينرونج لي، هاييانغ يو، هونغبين يي، شوفي تشياو، بينغ وانغ ، يوكي تشو، شين شيه، شيانغ تشن، تشوبو لي، لي لي، شياوتشوان ليانغ، يونزي ياو، جينغ تشن، يوكي تشو، شومين دينغ، وين تشانغ، قوتشو تشنغ، هواجون تشين
المساهمون في المجتمع: thredreams، eltociear، Ziwen Xu، Rui Huang، Xiaolong Weng


