صفحة المشروع | ورق | البطاقة النموذجية؟
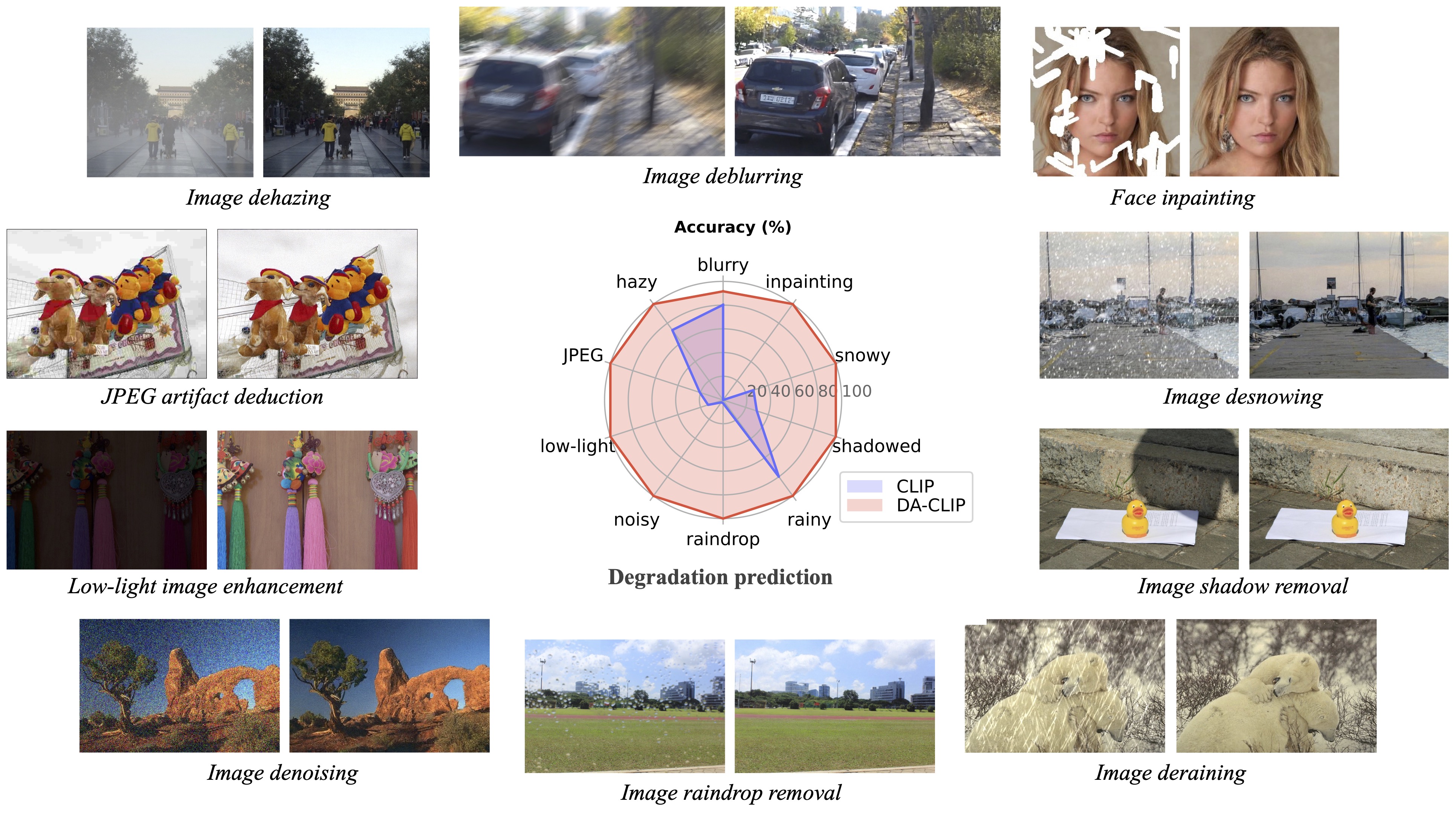
يقدم عملنا اللاحق استعادة الصور الواقعية في البرية باستخدام نماذج لغة الرؤية التي يتم التحكم فيها (CVPRW 2024) عينة خلفية لتوليد صور أفضل ويتعامل مع صور التدهور المختلط في العالم الحقيقي المشابهة لـ Real-ESRGAN.
[ 2024.04.16 ] ورقة المتابعة الخاصة بنا "استعادة الصور الواقعية في البرية باستخدام نماذج لغة الرؤية التي يتم التحكم فيها" متاحة الآن على ArXiv!
[ 2024.04.15 ] تم تحديث نموذج الأشعة تحت الحمراء البرية لتدهور العالم الحقيقي وأخذ العينات الخلفية لتوليد صور أفضل. يتم توفير الأوزان المدربة مسبقًا Wild-ir.pth وwild-daclip_ViT-L-14.pt أيضًا لـ Wild-ir.
[ 2024.01.20 ] ؟؟؟ تم قبول ورقة DA-CLIP الخاصة بنا من قبل ICLR 2024 ؟؟؟ كما نقدم نموذجًا أكثر قوة في بطاقة النموذج.
[ 2023.10.25 ] تمت إضافة روابط مجموعة البيانات للتدريب والاختبار.
[ 2023.10.13 ] تمت إضافة النسخة التجريبية وواجهة برمجة التطبيقات. شكرا ل @chenxwh !!! قمنا بتحديث العرض التوضيحي Hugging Face والعرض التوضيحي Colab عبر الإنترنت. شكرًا لـfffiloni وcamenduru !!! لقد صنعنا أيضًا بطاقة نموذجية في وجه معانق؟ وقدم المزيد من الأمثلة للاختبار.
[ 2023.10.09 ] تم إصدار الأوزان المدربة مسبقًا لـ DA-CLIP ونموذج Universal IR في الرابط 1 والرابط 2، على التوالي. بالإضافة إلى ذلك، نوفر أيضًا ملف تطبيق Gradio للحالة التي تريد فيها اختبار صورك الخاصة.
نظام التشغيل: أوبونتو 20.04
نفيديا:
كودا: 11.4
بيثون 3.8
ننصحك أولاً بإنشاء بيئة افتراضية تحتوي على:
python3 -m venv .envsource .env/bin/activate تثبيت النقطة -U النقطة تثبيت النقطة -r متطلبات.txt
أدخل إلى الدليل universal-image-restoration وقم بتشغيل:
استيراد الشعلة من PIL import Imageimport open_clipcheckpoint = 'pretrained/daclip_ViT-B-32.pt'model، المعالجة المسبقة = open_clip.create_model_from_pretrained('daclip_ViT-B-32'، pretrained=checkpoint)tokenizer = open_clip.get_tokenizer('ViT-B-32) ')الصورة = preprocess(Image.open("haze_01.png")).unsqueeze(0)degradations = ['حركة ضبابية','ضبابية','jpeg-compressed','إضاءة منخفضة','صاخبة','قطرة مطر' ،'ممطر'،'مظلل'،'ثلجي'،'غير مكتمل']نص = الرمز المميز(الانحطاطات)مع torch.no_grad()، torch.cuda.amp.autocast():text_features = model.encode_text(text)image_features, degra_features = model.encode_image(image, control=True)degra_features /= degra_features.norm(dim=-1, keepdim=True)text_features / = text_features.norm(dim=-1, keepdim=True)text_probs = (100.0 * degra_features @ text_features.T).softmax(dim=-1)index = torch.argmax(text_probs[0])print(f"Task: {task_name}: {degradations[index]} - {text_probs[0][index]}")إعداد مجموعات بيانات التدريب والاختبار باتباع قسم إنشاء مجموعة البيانات الورقية الخاص بنا على النحو التالي:
#### لمجموعة بيانات التدريب ######## (غير مكتملة تعني الرسم الداخلي) ####datasets/universal/train|--motion-blurry| |--LQ/*.png| |--GT/*.png|--ضبابي|--jpeg-compressed|--low-light|--صاخب|--قطرة مطر|--ممطر|--مظلل|--ثلجي|--غير مكتمل## ## لاختبار مجموعة البيانات ######## (نفس بنية القطار) ####datasets/universal/val ...#### للتسميات التوضيحية النظيفة ####datasets/universal/daclip_train.csv datasets/universal/daclip_val.csv
ثم قم بالدخول إلى الدليل universal-image-restoration/config/daclip-sde وقم بتعديل مسارات مجموعة البيانات في ملفات الخيارات في options/train.yml و options/test.yml .
يمكنك إضافة المزيد من المهام أو مجموعات البيانات إلى كل من دليلي train و val وإضافة كلمة التدهور إلى distortion .
| التدهور | ضبابية الحركة | ضبابي | مضغوط بصيغة jpeg* | الإضاءة المنخفضة | صاخبة * (نفس الصورة لJPEG) |
|---|---|---|---|---|---|
| مجموعات البيانات | جوبرو | RESIDE-6K | ديف2ك + فليكر2ك | مضحك جداً | ديف2ك + فليكر2ك |
| التدهور | قطرة مطر | ممطر | مظلل | ثلجي | غير مكتمل |
|---|---|---|---|---|---|
| مجموعات البيانات | قطرة مطر | Rain100H: تدريب، اختبار | إس آر دي | ثلج 100 ألف | سيليباHQ-256 |
يجب عليك فقط استخراج مجموعات بيانات القطار للتدريب ، ويمكن تنزيل جميع مجموعات بيانات التحقق من الصحة في Google Drive. بالنسبة لمجموعات البيانات بتنسيق jpeg وnoisy، يمكنك إنشاء صور LQ باستخدام هذا البرنامج النصي.
راجع DA-CLIP.md للحصول على التفاصيل.
الكود الرئيسي للتدريب موجود في universal-image-restoration/config/daclip-sde والشبكة الأساسية لـ DA-CLIP موجودة في universal-image-restoration/open_clip/daclip_model.py .
ضع أوزان DA-CLIP المُدربة مسبقًا في الدليل pretrained وتحقق من مسار daclip .
يمكنك بعد ذلك تدريب النموذج باتباع نصوص bash أدناه:
cd Universal-image-restoration/config/daclip-sde# لوحدة معالجة الرسوميات الفردية:python3 Train.py -opt=options/train.yml# للتدريب الموزع، تحتاج إلى تغيير gpu_ids في الخيار filepython3 -m torch.distributed.launch - -nproc_per_node=2 --master_port=4321 Train.py -opt=options/train.yml --launcher pytorch
سيتم حفظ النماذج وسجلات التدريب في log/universal-ir . يمكنك طباعة السجل الخاص بك في الوقت المناسب عن طريق تشغيل tail -f log/universal-ir/train_universal-ir_***.log -n 100 .
يمكن استخدام نفس خطوات التدريب لاستعادة الصورة في البرية (wild-ir).
| اسم النموذج | وصف | جوجل درايف | HuggingFace |
|---|---|---|---|
| دا كليب | نموذج CLIP المدرك للتدهور | تحميل | تحميل |
| عالمي-IR | نموذج استعادة الصور العالمي القائم على DA-CLIP | تحميل | تحميل |
| مزيج DA-CLIP | نموذج CLIP المدرك للتدهور (إضافة تمويه غاوسي + طلاء للوجه وتمويه غاوسي + ممطر) | تحميل | تحميل |
| مزيج عالمي للأشعة تحت الحمراء | نموذج استعادة الصور العالمي القائم على DA-CLIP (إضافة تدريب قوي وتدهور المزيج) | تحميل | تحميل |
| وايلد دا كليب | نموذج CLIP المدرك للتدهور في البرية (ViT-L-14) | تحميل | تحميل |
| وايلد-IR | نموذج استعادة الصور القائم على DA-CLIP في البرية | تحميل | تحميل |
لتقييم طريقتنا في استعادة الصور، يرجى تعديل المسار المعياري ومسار النموذج والتشغيل
cd Universal-image-restoration/config/universal-ir بايثون test.py -opt=options/test.yml
نقدم هنا ملف app.py لاختبار صورك الخاصة. قبل ذلك، تحتاج إلى تنزيل الأوزان المدربة مسبقًا (DA-CLIP و UIR) وتعديل مسار النموذج في options/test.yml . ثم ببساطة عن طريق تشغيل python app.py ، يمكنك فتح http://localhost:7860 لاختبار النموذج. (نوفر أيضًا العديد من الصور ذات الانحطاطات المختلفة في images دير). نقدم أيضًا المزيد من الأمثلة من مجموعة بيانات الاختبار الخاصة بنا في محرك جوجل.
يمكن استخدام نفس الخطوات لاستعادة الصورة في البرية (wild-ir).
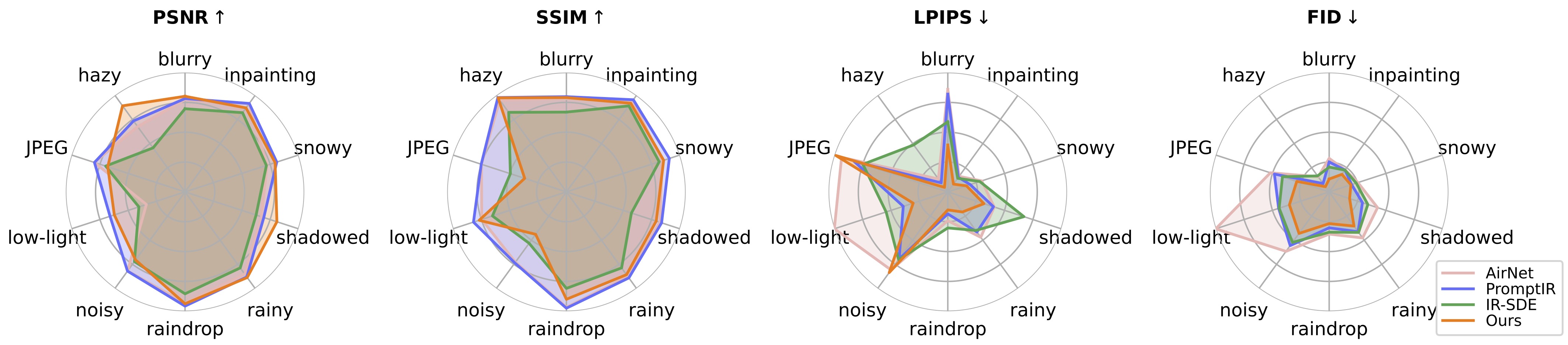



؟ أثناء الاختبار، وجدنا أن النموذج الحالي المُدرب مسبقًا لا يزال من الصعب معالجة بعض صور العالم الحقيقي التي قد يكون لها تحولات في التوزيع مع مجموعة بيانات التدريب الخاصة بنا (التي تم التقاطها من أجهزة مختلفة أو بدقة أو تدهور مختلفة). نحن نعتبره عملاً مستقبليًا وسنحاول أن نجعل نموذجنا أكثر عملية! نحن نشجع أيضًا المستخدمين المهتمين بعملنا على تدريب نماذجهم الخاصة باستخدام مجموعة بيانات أكبر وأنواع أكثر تدهورًا.
؟ راجع للشغل، وجدنا أيضًا أن تغيير حجم الصور المدخلة مباشرةً سيؤدي إلى أداء ضعيف لمعظم المهام . يمكننا أن نحاول إضافة خطوة تغيير الحجم إلى التدريب ولكنها دائمًا ما تدمر جودة الصورة بسبب الاستيفاء.
؟ بالنسبة لمهمة الرسم الداخلي، يدعم نموذجنا الحالي رسم الوجه فقط نظرًا لقيود مجموعة البيانات. نحن نقدم أمثلة على الأقنعة الخاصة بنا ويمكنك استخدام البرنامج النصي generator_masked_face لإنشاء وجوه غير مكتملة.
شكر وتقدير: يعتمد DA-CLIP الخاص بنا على IR-SDE وopen_clip. شكرا على الكود الخاص بهم!
إذا كان لديك أي سؤال، يرجى الاتصال بـ: [email protected]
إذا كان الكود الخاص بنا يساعد في بحثك أو عملك، فيرجى التفكير في الاستشهاد بورقتنا البحثية. فيما يلي مراجع BibTeX:
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}
@article{luo2024photo,
title={Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2404.09732},
year={2024}
}

