
شوان جو 1* ، ييمينغ جاو 1* ، تشاويانغ تشانغ 1*# ، زيانغ يوان 1 ، شينتاو وانغ 1 ، أيلينغ تسنغ، يو شيونغ، تشيانغ شو، ينغ شان 1
1 ARC Lab، Tencent PCG 2 الجامعة الصينية في هونج كونج * المساهمة المتساوية # قائد المشروع
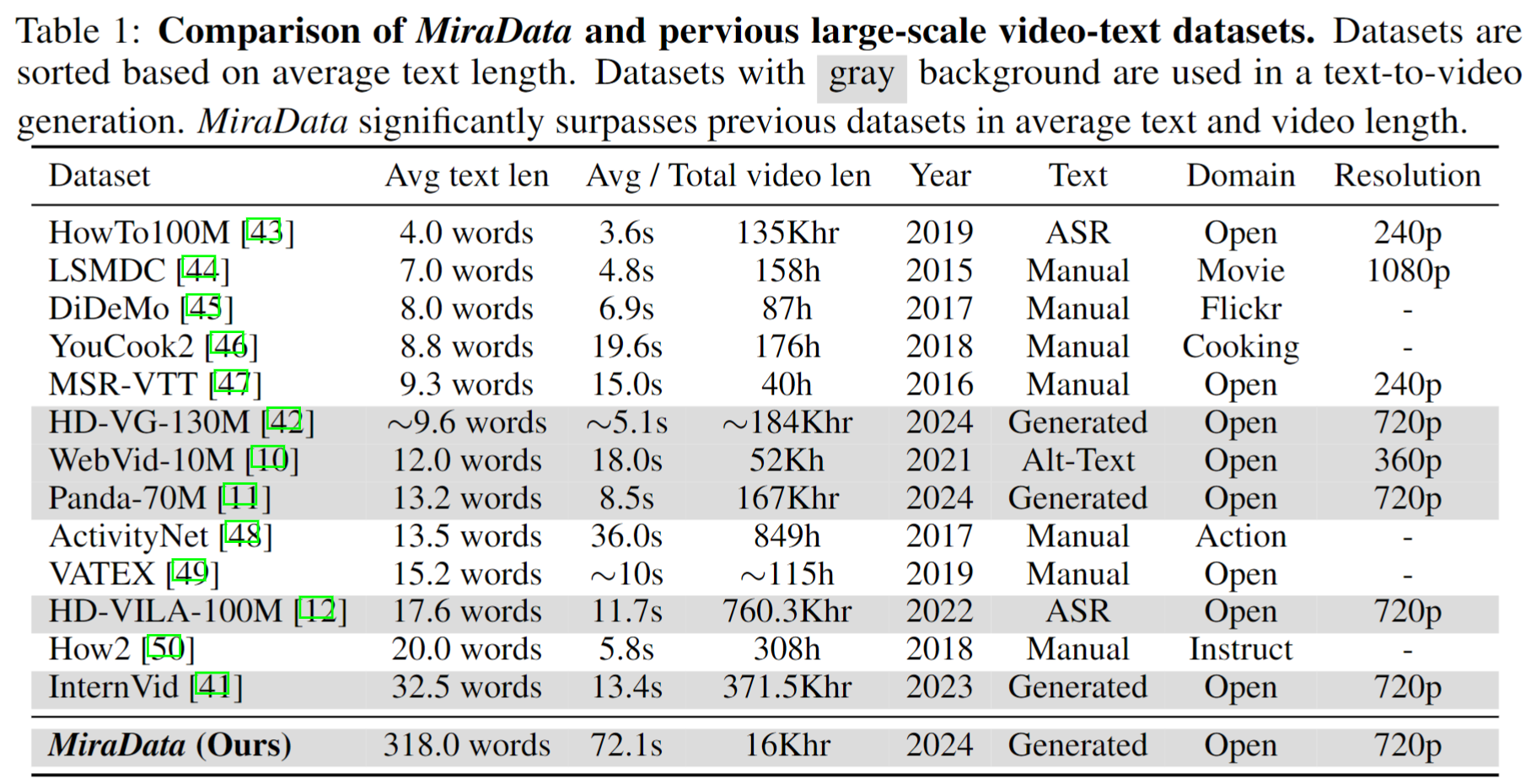
تلعب مجموعات بيانات الفيديو دورًا حاسمًا في إنشاء الفيديو مثل Sora. ومع ذلك، غالبًا ما تكون مجموعات بيانات الفيديو النصية الحالية غير كافية عندما يتعلق الأمر بمعالجة تسلسلات الفيديو الطويلة والتقاط انتقالات اللقطات . لمعالجة هذه القيود، نقدم MiraData ، وهي مجموعة بيانات فيديو مصممة خصيصًا لمهام إنشاء الفيديو الطويلة. علاوة على ذلك، لتقييم الاتساق الزمني وكثافة الحركة في إنشاء الفيديو بشكل أفضل، نقدم MiraBench ، الذي يعزز المعايير الحالية عن طريق إضافة اتساق ثلاثي الأبعاد ومقاييس قوة الحركة القائمة على التتبع. يمكنك العثور على مزيد من التفاصيل في ورقتنا البحثية.
قمنا بإصدار أربعة إصدارات من MiraData، تحتوي على بيانات 330K و93K و42K و9K.
يتم توفير الملف التعريفي لهذا الإصدار من MiraData في Google Drive وHuggingFace Dataset. بالإضافة إلى ذلك، من أجل فهم أفضل وأسرع لتكوين ملف التعريف الخاص بنا، قمنا بشكل عشوائي بإجراء عينة من مجموعة مكونة من 100 مقطع فيديو، والتي يمكن الوصول إليها هنا. يحتوي ملف التعريف على معلومات الفهرس التالية:
{download_id}.{clip_id}لتنزيل مقاطع الفيديو وتقسيمها إلى مقاطع، ابدأ بتنزيل ملفات التعريف من Google Drive أو HuggingFace Dataset. بمجرد حصولك على ملفات التعريف، يمكنك استخدام البرامج النصية التالية لتنزيل عينات الفيديو:
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
سنقوم بإزالة عينات الفيديو من صفحة الويب الخاصة بمجموعة البيانات / Github / المشروع طالما كنت في حاجة إليها. يرجى الاتصال بنا للحصول على الطلب.
لجمع MiraData، نختار أولاً قنوات youtube يدويًا في سيناريوهات مختلفة ونقوم بتضمين مقاطع فيديو من HD-VILA-100M وVideovo وPixabay وPexels. بعد ذلك، يتم تنزيل جميع مقاطع الفيديو الموجودة في القنوات المقابلة وتقسيمها باستخدام PySceneDetect. استخدمنا بعد ذلك نماذج متعددة لدمج المقاطع القصيرة معًا وتصفية مقاطع الفيديو منخفضة الجودة. بعد ذلك، قمنا باختيار مقاطع فيديو ذات فترات طويلة. أخيرًا، قمنا بتعليق جميع مقاطع الفيديو باستخدام GPT-4V.

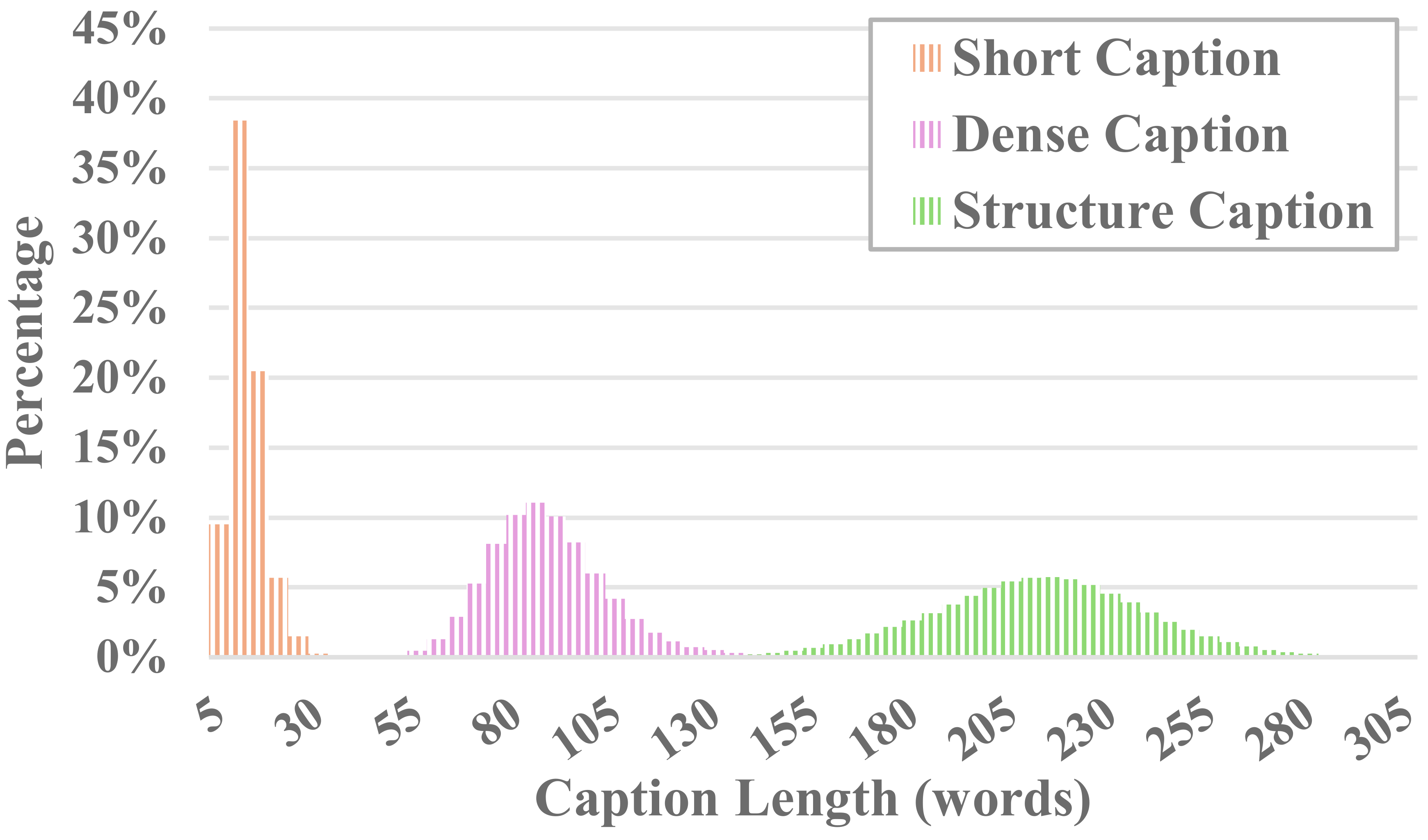
يكون كل فيديو في MiraData مصحوبًا بتعليقات توضيحية منظمة. توفر هذه التسميات التوضيحية أوصافًا تفصيلية من وجهات نظر مختلفة، مما يعزز ثراء مجموعة البيانات.
ستة أنواع من التسميات التوضيحية
لقد اختبرنا طرق LLM المرئية مفتوحة المصدر الحالية وGPT-4V، ووجدنا أن التسميات التوضيحية لـ GPT-4V تظهر دقة وتماسكًا أفضل في الفهم الدلالي من حيث التسلسل الزمني.
من أجل تحقيق التوازن بين تكاليف التعليقات التوضيحية ودقة التسميات التوضيحية، قمنا بشكل موحد باختبار 8 إطارات لكل فيديو وترتيبها في شبكة 2x4 لصورة واحدة كبيرة. بعد ذلك، نستخدم نموذج التسمية التوضيحية لـ Panda-70M لتعليق كل مقطع فيديو بتعليق من جملة واحدة، والذي يكون بمثابة تلميح للمحتوى الرئيسي، وإدخاله في المطالبة المضبوطة لدينا. من خلال تغذية الموجه المضبوط بدقة وصورة كبيرة مقاس 2x4 إلى GPT-4V، يمكننا إخراج التسميات التوضيحية بكفاءة لأبعاد متعددة في جولة واحدة فقط من المحادثة. يمكن العثور على محتوى المطالبة المحدد في caption_gpt4v.py، ونحن نرحب بالجميع للمساهمة في المزيد من بيانات الفيديو النصية عالية الجودة. ؟

لتقييم إنشاء مقاطع فيديو طويلة، قمنا بتصميم 17 مقياس تقييم في MiraBench من 6 وجهات نظر، بما في ذلك الاتساق الزمني، وقوة الحركة الزمنية، والاتساق ثلاثي الأبعاد، والجودة المرئية، ومحاذاة النص والفيديو، واتساق التوزيع. تشمل هذه المقاييس معظم معايير التقييم الشائعة المستخدمة في نماذج إنشاء الفيديو السابقة ومعايير تحويل النص إلى فيديو.
لتقييم مقاطع الفيديو التي تم إنشاؤها، يرجى أولاً إعداد بيئة بايثون من خلال:
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
ثم قم بإجراء التقييم من خلال:
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
يمكنك اتباع المثال الموجود في data/evaluation_example لتقييم مقاطع الفيديو التي أنشأتها بنفسك.
يرجى الاطلاع على الترخيص.
إذا وجدت هذا المشروع مفيدًا لبحثك، فيرجى الاستشهاد بمقالتنا. ؟
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
لأية استفسارات، يرجى إرسال بريد إلكتروني إلى [email protected] .
MiraData خاضع لترخيص GPL-v3 وهو مدعوم للاستخدام التجاري. إذا كنت بحاجة إلى ترخيص تجاري لـ MiraData، فلا تتردد في الاتصال بنا.


