storm
v1.0.0 & EMNLP 2024 Paper Accepted!
| معاينة البحث | ورقة العاصفة | ورقة العاصفة المشتركة | الموقع |
آخر الأخبار
[2024/09] تم الآن إصدار قاعدة بيانات Co-STORM ودمجها في حزمة python knowledge-storm v1.0.0. قم بتشغيل pip install knowledge-storm --upgrade للتحقق من ذلك.
[2024/09] نقدم STORM التعاوني (Co-STORM) لدعم تنظيم المعرفة التعاونية بين الإنسان والذكاء الاصطناعي! تم قبول ورقة Co-STORM في المؤتمر الرئيسي EMNLP 2024.
[2024/07] يمكنك الآن تثبيت الحزمة الخاصة بنا باستخدام pip install knowledge-storm !
[2024/07] نضيف VectorRM لدعم التأريض على المستندات المقدمة من المستخدم، واستكمال الدعم الحالي لمحركات البحث ( YouRM ، BingSearch ). (راجع رقم 58)
[2024/07] أصدرنا ضوءًا تجريبيًا للمطورين، وهو عبارة عن واجهة مستخدم بسيطة تم إنشاؤها باستخدام إطار عمل مبسط في Python، وهو مفيد للتطوير المحلي واستضافة العروض التوضيحية (الخروج رقم 54)
[2024/06] سنقدم STORM في NAACL 2024! تابعونا في جلسة الملصقات 2 في 17 يونيو أو قم بمراجعة مواد العرض التقديمي لدينا.
[2024/05] نضيف دعم بحث Bing في rm.py. اختبار STORM باستخدام GPT-4o - نقوم الآن بتكوين جزء إنشاء المقالة في العرض التوضيحي الخاص بنا باستخدام نموذج GPT-4o .
[2024/04] قمنا بإصدار نسخة مُعاد تصنيعها من قاعدة بيانات STORM! نحدد واجهة لخط أنابيب STORM ونعيد تنفيذ STORM-wiki (راجع src/storm_wiki ) لتوضيح كيفية إنشاء خط الأنابيب. نحن نقدم واجهة برمجة التطبيقات (API) لدعم تخصيص نماذج اللغات المختلفة وتكامل الاسترجاع/البحث.
في حين أن النظام لا يستطيع إنتاج مقالات جاهزة للنشر والتي غالبًا ما تتطلب عددًا كبيرًا من التعديلات، إلا أن محرري ويكيبيديا ذوي الخبرة وجدوا ذلك مفيدًا في مرحلة ما قبل الكتابة.
لقد جرب أكثر من 70.000 شخص معاينة البحث المباشر لدينا. جربه لترى كيف يمكن لـ STORM أن يساعدك في رحلة استكشاف المعرفة الخاصة بك ويرجى تقديم تعليقات لمساعدتنا في تحسين النظام!
تقسم STORM عملية إنشاء مقالات طويلة تحتوي على استشهادات إلى خطوتين:
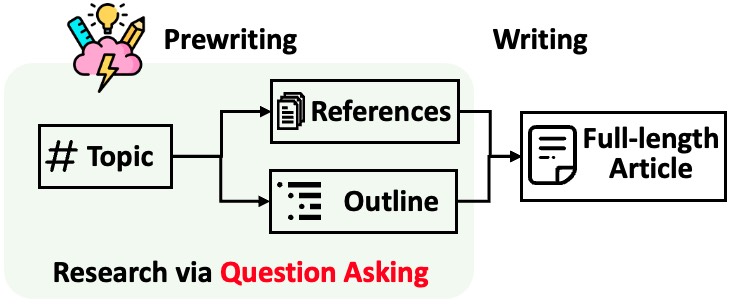
تحدد STORM أن جوهر أتمتة عملية البحث هو طرح الأسئلة الجيدة التي يجب طرحها تلقائيًا. إن مطالبة نموذج اللغة مباشرة بطرح الأسئلة لا تعمل بشكل جيد. لتحسين عمق واتساع الأسئلة، تتبنى STORM استراتيجيتين:
تقترح Co-STORM بروتوكول حوار تعاوني ينفذ سياسة إدارة الأدوار لدعم التعاون السلس بين الأشخاص
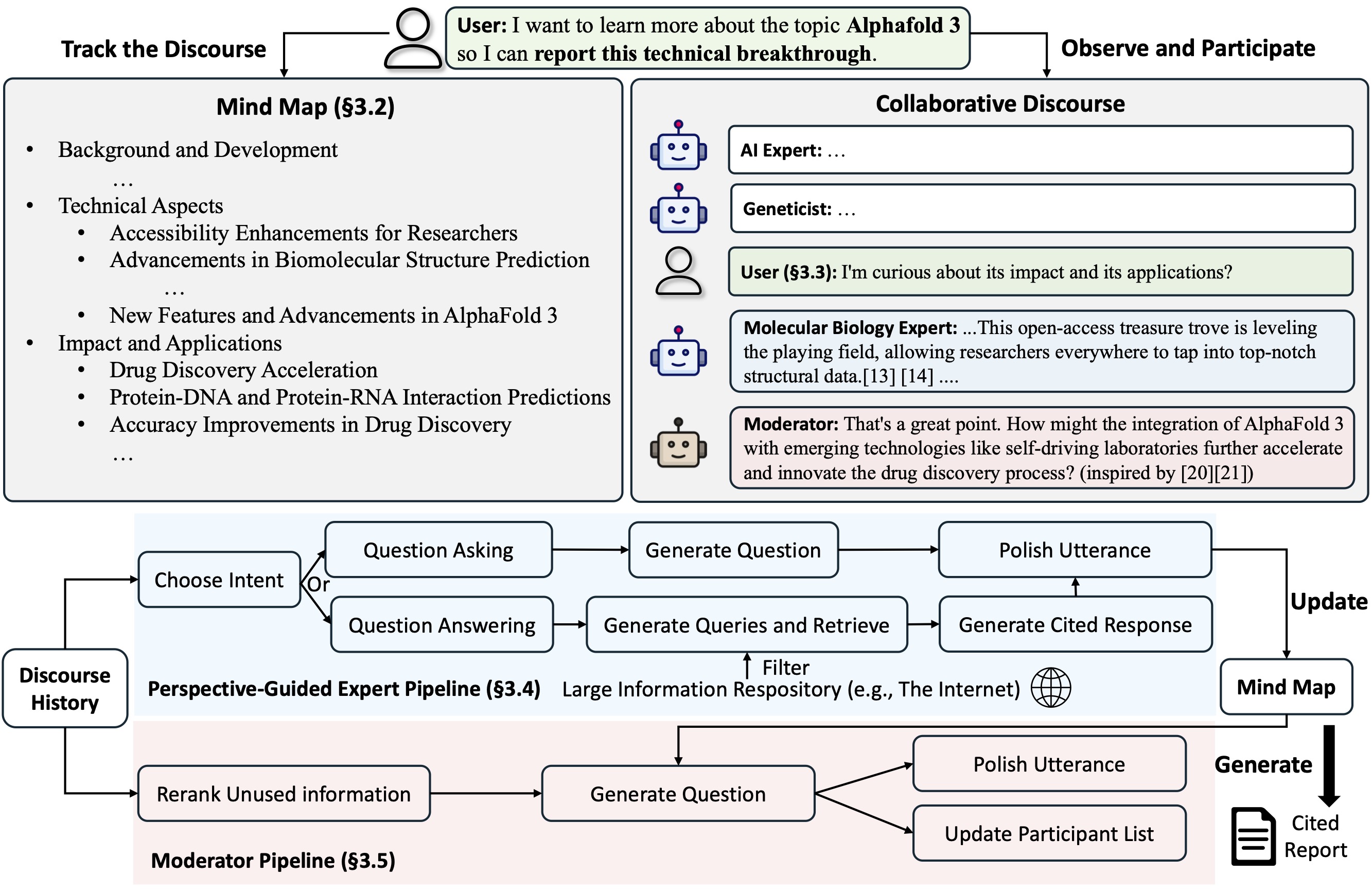
تحتفظ Co-STORM أيضًا بخريطة ذهنية ديناميكية محدثة، والتي تنظم المعلومات المجمعة في هيكل مفاهيمي هرمي، يهدف إلى بناء مساحة مفاهيمية مشتركة بين المستخدم البشري والنظام . لقد ثبت أن الخريطة الذهنية تساعد في تقليل العبء العقلي عندما يكون الخطاب طويلاً ومتعمقًا.
يتم تنفيذ كل من STORM وCo-STORM بطريقة معيارية للغاية باستخدام dspy.
لتثبيت مكتبة عاصفة المعرفة، استخدم pip install knowledge-storm .
يمكنك أيضًا تثبيت الكود المصدري الذي يسمح لك بتعديل سلوك محرك STORM مباشرة.
استنساخ مستودع جيت.
git clone https://github.com/stanford-oval/storm.git
cd stormتثبيت الحزم المطلوبة.
conda create -n storm python=3.11
conda activate storm
pip install -r requirements.txtحاليا، دعم الحزمة لدينا:
OpenAIModel ، AzureOpenAIModel ، ClaudeModel ، VLLMClient ، TGIClient ، TogetherClient ، OllamaClient ، GoogleModel ، DeepSeekModel ، GroqModel كمكونات لنموذج اللغةYouRM و BingSearch VectorRM و SerperRM و BraveRM و SearXNG و DuckDuckGoSearchRM و TavilySearchRM و GoogleSearch و AzureAISearch كمكونات وحدة الاسترجاع؟ إن العلاقات العامة لدمج المزيد من نماذج اللغة في Knowledge_storm/lm.py ومحركات البحث/المستردات في Knowledge_storm/rm.py تحظى بتقدير كبير!
يعمل كل من STORM وCo-STORM في طبقة تنظيم المعلومات، وتحتاج إلى إعداد وحدة استرجاع المعلومات ووحدة نموذج اللغة لإنشاء فئات Runner الخاصة بهما على التوالي.
يتم تعريف محرك تنظيم المعرفة STORM على أنه فئة بسيطة من Python STORMWikiRunner . فيما يلي مثال على استخدام محرك بحث You.com ونماذج OpenAI.
import os
from knowledge_storm import STORMWikiRunnerArguments , STORMWikiRunner , STORMWikiLMConfigs
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . rm import YouRM
lm_configs = STORMWikiLMConfigs ()
openai_kwargs = {
'api_key' : os . getenv ( "OPENAI_API_KEY" ),
'temperature' : 1.0 ,
'top_p' : 0.9 ,
}
# STORM is a LM system so different components can be powered by different models to reach a good balance between cost and quality.
# For a good practice, choose a cheaper/faster model for `conv_simulator_lm` which is used to split queries, synthesize answers in the conversation.
# Choose a more powerful model for `article_gen_lm` to generate verifiable text with citations.
gpt_35 = OpenAIModel ( model = 'gpt-3.5-turbo' , max_tokens = 500 , ** openai_kwargs )
gpt_4 = OpenAIModel ( model = 'gpt-4o' , max_tokens = 3000 , ** openai_kwargs )
lm_configs . set_conv_simulator_lm ( gpt_35 )
lm_configs . set_question_asker_lm ( gpt_35 )
lm_configs . set_outline_gen_lm ( gpt_4 )
lm_configs . set_article_gen_lm ( gpt_4 )
lm_configs . set_article_polish_lm ( gpt_4 )
# Check out the STORMWikiRunnerArguments class for more configurations.
engine_args = STORMWikiRunnerArguments (...)
rm = YouRM ( ydc_api_key = os . getenv ( 'YDC_API_KEY' ), k = engine_args . search_top_k )
runner = STORMWikiRunner ( engine_args , lm_configs , rm ) يمكن استحضار مثيل STORMWikiRunner بطريقة run البسيطة:
topic = input ( 'Topic: ' )
runner . run (
topic = topic ,
do_research = True ,
do_generate_outline = True ,
do_generate_article = True ,
do_polish_article = True ,
)
runner . post_run ()
runner . summary ()do_research : إذا كان هذا صحيحًا، قم بمحاكاة المحادثات ذات وجهات نظر مختلفة لجمع معلومات حول الموضوع؛ وإلا، تحميل النتائج.do_generate_outline : إذا كان True، قم بإنشاء مخطط تفصيلي للموضوع؛ وإلا، تحميل النتائج.do_generate_article : إذا كان صحيحًا، قم بإنشاء مقالة حول الموضوع بناءً على المخطط التفصيلي والمعلومات المجمعة؛ وإلا، تحميل النتائج.do_polish_article : إذا كان صحيحًا، قم بتحسين المقالة عن طريق إضافة قسم تلخيص و(اختياريًا) إزالة المحتوى المكرر؛ وإلا، تحميل النتائج. يتم تعريف محرك تنظيم المعرفة Co-STORM على أنه فئة بسيطة من Python CoStormRunner . فيما يلي مثال على استخدام محرك بحث Bing ونماذج OpenAI.
from knowledge_storm . collaborative_storm . engine import CollaborativeStormLMConfigs , RunnerArgument , CoStormRunner
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . logging_wrapper import LoggingWrapper
from knowledge_storm . rm import BingSearch
# Co-STORM adopts the same multi LM system paradigm as STORM
lm_config : CollaborativeStormLMConfigs = CollaborativeStormLMConfigs ()
openai_kwargs = {
"api_key" : os . getenv ( "OPENAI_API_KEY" ),
"api_provider" : "openai" ,
"temperature" : 1.0 ,
"top_p" : 0.9 ,
"api_base" : None ,
}
question_answering_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
discourse_manage_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
utterance_polishing_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 2000 , ** openai_kwargs )
warmstart_outline_gen_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
question_asking_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 300 , ** openai_kwargs )
knowledge_base_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
lm_config . set_question_answering_lm ( question_answering_lm )
lm_config . set_discourse_manage_lm ( discourse_manage_lm )
lm_config . set_utterance_polishing_lm ( utterance_polishing_lm )
lm_config . set_warmstart_outline_gen_lm ( warmstart_outline_gen_lm )
lm_config . set_question_asking_lm ( question_asking_lm )
lm_config . set_knowledge_base_lm ( knowledge_base_lm )
# Check out the Co-STORM's RunnerArguments class for more configurations.
topic = input ( 'Topic: ' )
runner_argument = RunnerArgument ( topic = topic , ...)
logging_wrapper = LoggingWrapper ( lm_config )
bing_rm = BingSearch ( bing_search_api_key = os . environ . get ( "BING_SEARCH_API_KEY" ),
k = runner_argument . retrieve_top_k )
costorm_runner = CoStormRunner ( lm_config = lm_config ,
runner_argument = runner_argument ,
logging_wrapper = logging_wrapper ,
rm = bing_rm ) يمكن استحضار مثيل CoStormRunner باستخدام أساليب warmstart() و step(...) .
# Warm start the system to build shared conceptual space between Co-STORM and users
costorm_runner . warm_start ()
# Step through the collaborative discourse
# Run either of the code snippets below in any order, as many times as you'd like
# To observe the conversation:
conv_turn = costorm_runner . step ()
# To inject your utterance to actively steer the conversation:
costorm_runner . step ( user_utterance = "YOUR UTTERANCE HERE" )
# Generate report based on the collaborative discourse
costorm_runner . knowledge_base . reorganize ()
article = costorm_runner . generate_report ()
print ( article )نحن نقدم البرامج النصية في مجلد الأمثلة الخاص بنا كبداية سريعة لتشغيل STORM وCo-STORM بتكوينات مختلفة.
نقترح استخدام secrets.toml لإعداد مفاتيح API. قم بإنشاء ملف secrets.toml ضمن الدليل الجذر وأضف المحتوى التالي:
# Set up OpenAI API key.
OPENAI_API_KEY= " your_openai_api_key "
# If you are using the API service provided by OpenAI, include the following line:
OPENAI_API_TYPE= " openai "
# If you are using the API service provided by Microsoft Azure, include the following lines:
OPENAI_API_TYPE= " azure "
AZURE_API_BASE= " your_azure_api_base_url "
AZURE_API_VERSION= " your_azure_api_version "
# Set up You.com search API key.
YDC_API_KEY= " your_youcom_api_key " لتشغيل STORM مع نماذج عائلة gpt ذات التكوينات الافتراضية:
قم بتشغيل الأمر التالي.
python examples/storm_examples/run_storm_wiki_gpt.py
--output-dir $OUTPUT_DIR
--retriever you
--do-research
--do-generate-outline
--do-generate-article
--do-polish-articleلتشغيل STORM باستخدام نماذج اللغة المفضلة لديك أو التأريض على مجموعتك الخاصة: راجع الأمثلة/storm_examples/README.md.
لتشغيل Co-STORM مع نماذج عائلة gpt ذات التكوينات الافتراضية،
BING_SEARCH_API_KEY="xxx" و ENCODER_API_TYPE="xxx" إلى secrets.tomlpython examples/costorm_examples/run_costorm_gpt.py
--output-dir $OUTPUT_DIR
--retriever bingإذا قمت بتثبيت الكود المصدري، فيمكنك تخصيص STORM بناءً على حالة الاستخدام الخاصة بك. يتكون محرك STORM من 4 وحدات:
يتم تعريف واجهة كل وحدة في knowledge_storm/interface.py ، بينما يتم إنشاء مثيلاتها في knowledge_storm/storm_wiki/modules/* . يمكن تخصيص هذه الوحدات وفقًا لمتطلباتك المحددة (على سبيل المثال، إنشاء أقسام بتنسيق نقطي بدلاً من فقرات كاملة).
إذا قمت بتثبيت الكود المصدري، فيمكنك تخصيص Co-STORM بناءً على حالة الاستخدام الخاصة بك
knowledge_storm/interface.py ، بينما يتم إنشاء مثيل لها في knowledge_storm/collaborative_storm/modules/co_storm_agents.py . يمكن تخصيص سياسات وكيل LLM المختلفة.DiscourseManager في knowledge_storm/collaborative_storm/engine.py . يمكن تخصيصها وتحسينها. لتسهيل دراسة التنظيم التلقائي للمعرفة والبحث عن المعلومات المعقدة، يصدر مشروعنا مجموعات البيانات التالية:
مجموعة بيانات FreshWiki عبارة عن مجموعة من 100 مقالة ويكيبيديا عالية الجودة تركز على الصفحات الأكثر تحريرًا من فبراير 2022 إلى سبتمبر 2023. راجع القسم 2.1 في ورقة STORM لمزيد من التفاصيل.
يمكنك تنزيل مجموعة البيانات من Huggingface مباشرة. لتسهيل مشكلة تلوث البيانات، نقوم بأرشفة الكود المصدري لخط بناء البيانات الذي يمكن تكراره في التواريخ المستقبلية.
لدراسة اهتمامات المستخدمين بمهام البحث عن المعلومات المعقدة في البرية، استخدمنا البيانات التي تم جمعها من معاينة بحث الويب لإنشاء مجموعة بيانات WildSeek. لقد قمنا باختزال البيانات لضمان تنوع المواضيع وجودة البيانات. كل نقطة بيانات عبارة عن زوج يشتمل على موضوع وهدف المستخدم لإجراء بحث عميق حول الموضوع. لمزيد من التفاصيل، يرجى الرجوع إلى القسم 2.2 والملحق أ من ورقة Co-STORM.
مجموعة بيانات WildSeek متاحة هنا.
بالنسبة للتجارب الورقية لـ STORM، يرجى التبديل إلى فرع NAACL-2024-code-backup هنا.
بالنسبة للتجارب الورقية لـ Co-STORM، يرجى التبديل إلى فرع EMNLP-2024-code-backup (العنصر النائب في الوقت الحالي، سيتم تحديثه قريبًا).
يعمل فريقنا بنشاط على:
إذا كان لديك أي أسئلة أو اقتراحات، فلا تتردد في فتح مشكلة أو سحب الطلب. نحن نرحب بالمساهمات لتحسين النظام وقاعدة التعليمات البرمجية!
شخص الاتصال: Yijia Shao وYucheng Jiang
نود أن نشكر ويكيبيديا على محتواها الممتاز مفتوح المصدر. يتم الحصول على مجموعة بيانات FreshWiki من Wikipedia، المرخصة بموجب ترخيص Creative Commons Attribution-ShareAlike (CC BY-SA).
نحن ممتنون جدًا لميشيل لام لتصميم شعار هذا المشروع وDekun Ma لقيادة تطوير واجهة المستخدم.
يرجى الاستشهاد بورقتنا إذا كنت تستخدم هذا الرمز أو جزء منه في عملك:
@misc { jiang2024unknownunknowns ,
title = { Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations } ,
author = { Yucheng Jiang and Yijia Shao and Dekun Ma and Sina J. Semnani and Monica S. Lam } ,
year = { 2024 } ,
eprint = { 2408.15232 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.15232 } ,
}
@inproceedings { shao2024assisting ,
title = { {Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models} } ,
author = { Yijia Shao and Yucheng Jiang and Theodore A. Kanell and Peter Xu and Omar Khattab and Monica S. Lam } ,
year = { 2024 } ,
booktitle = { Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) }
}

