bulk
1.0.0
تُعد Bulk أداة مطور سريعة لتطبيق بعض التصنيفات المجمعة. نظرًا لمجموعة بيانات معدة بتضمينات ثنائية الأبعاد، يمكنها إنشاء واجهة تسمح لك بإضافة بعض التعليقات التوضيحية المجمعة بسرعة، وإن كانت أقل دقة.
python -m pip install --upgrade pip
python -m pip install bulk
مستقبل الجزء الأكبر هو تقديم الأدوات التي يمكن أن تساعدك في دفتر الملاحظات. في الوقت الحالي، يعد BaseTextExplorer هو الأداة الرئيسية المدعومة. بالنظر إلى بعض البيانات التي تمت معالجتها مسبقًا، يمكنك استخدام المستكشف للبحث في UMAP ثنائي الأبعاد لتضمينات النص.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
umap = UMAP ()
text_emb_pipeline = make_pipeline (
enc , umap
)
# Load sentences
sentences = list ( pd . read_csv ( "tests/data/text.csv" )[ 'text' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]لاستخدام القطعة، تحتاج فقط إلى تشغيل هذا:
from bulk . widgets import BaseTextExplorer
widget = BaseTextExplorer ( df )
widget . show ()سيسمح لنا ذلك باستكشاف المجموعات التي تظهر في بياناتنا بسرعة. يمكنك الضغط باستمرار على مؤشر الماوس للانتقال إلى وضع التحديد، وعندما تحدد العناصر، سترى مجموعة فرعية عشوائية تظهر على اليمين. يمكنك إعادة أخذ عينة من اختيارك بالنقر فوق زر إعادة العينة.
عند إجراء التحديدات، يمكنك رؤية الأداة على التحديث الصحيح، ولكن يمكنك أيضًا الحصول على البيانات من إحدى سمات Python.
widget . selected_idx
widget . selected_texts
widget . selected_dataframeإن القدرة على استكشاف هذه المجموعات أمر رائع، ولكن يبدو أننا قد نتمكن من استكشاف كل شيء بسهولة أكبر إذا كان لدينا المزيد من الأدوات تحت تصرفنا. على وجه الخصوص، نريد أن يكون لدينا برنامج تشفير حتى نتمكن من استخدام الاستعلامات في المساحة المضمنة لدينا. ستسمح لنا واجهة المستخدم أدناه باستكشاف المزيد من التفاعلية من خلال تحديث الألوان باستخدام رسالة نصية.
from embetter . text import SentenceEncoder
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
# Pay attention here! The rows in df needs to align with the rows in X!
widget = BaseTextExplorer ( df , X = X , encoder = enc )
widget . show ()بفضل أدوات مثل ipywidget وanywidget، يمكننا حقًا البدء في إنشاء بعض الأدوات للحفاظ على دفتر الملاحظات هو المكان المناسب لتلبية احتياجاتك من البيانات. نظرًا لبعض الأدوات المناسبة، لن تتمكن أبدًا من تجاوز دفتر ملاحظات Jupyter!
الاهتمام الأساسي لهذا المشروع هو العمل على أدوات جودة البيانات. إن القدرة على تحديد نقاط البيانات بشكل مجمّع تبدو بمثابة مكان رائع للبدء. ربما يمكنك العثور على مجموعة فرعية مثيرة للاهتمام لتعليقها أولاً، وربما تتفاجأ عندما ترى مجموعتين مختلفتين يجب أن تكونا واحدة. كل تلك الأشياء الجيدة يمكن أن تحدث في دفتر الملاحظات!
يأتي Bulk أيضًا مع تطبيق ويب صغير يستخدم Bokeh لتزويدك بواجهات التعليقات التوضيحية استنادًا إلى تمثيلات UMAP للتضمينات. ويقدم واجهة للنص. كانت هذه الواجهة هي الواجهة/الميزة الأصلية لهذا المشروع.
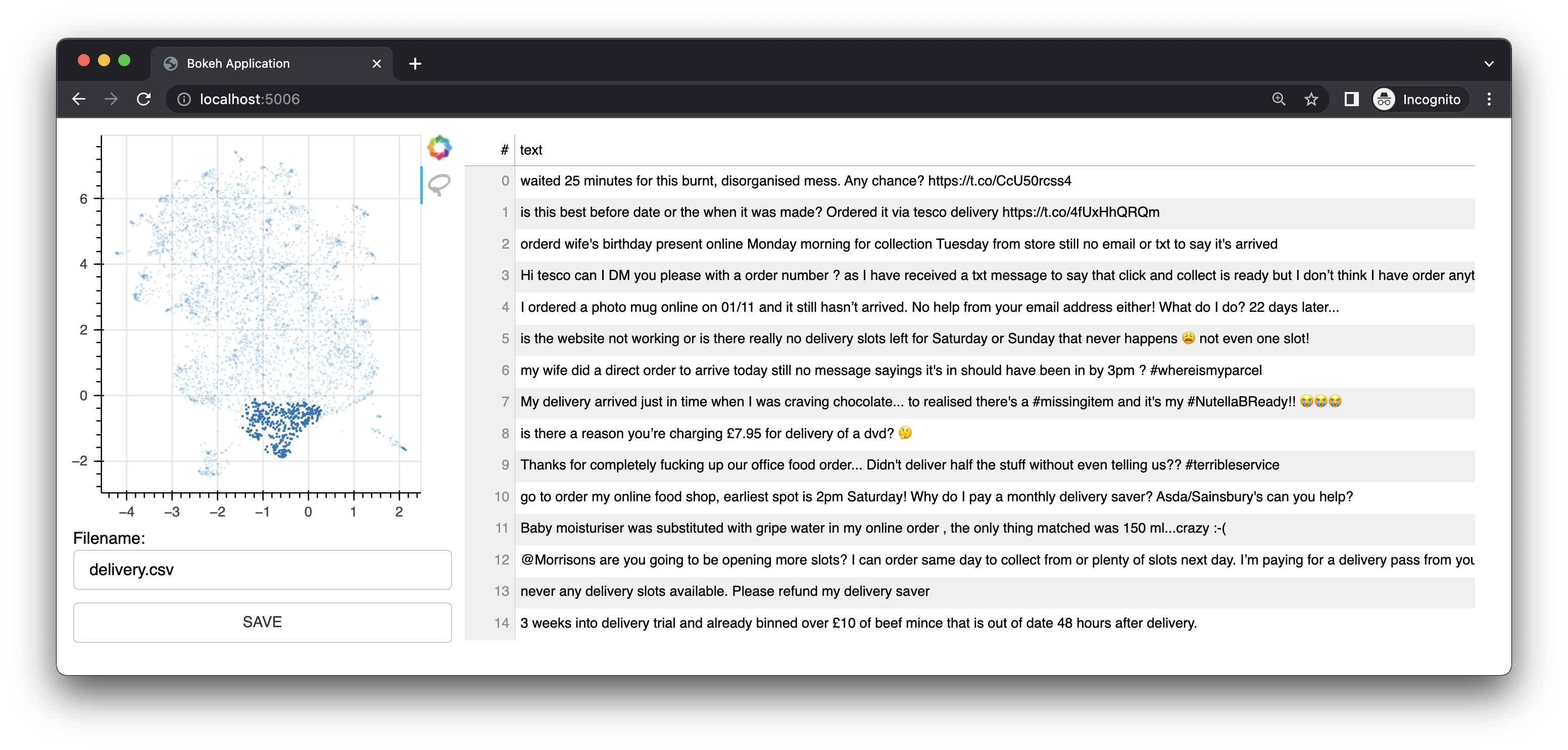
كما يتميز بواجهة الصور.
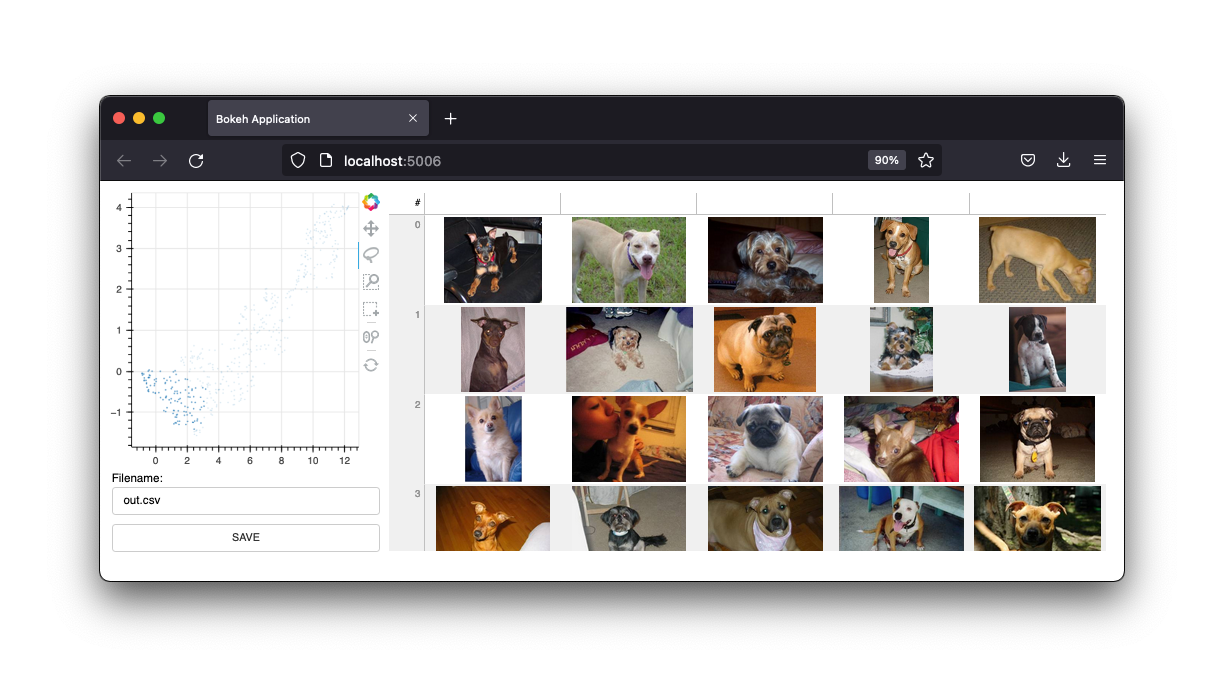
سنحتفظ بهذه الواجهات، لكن مستقبل هذا المشروع سيكون عبارة عن عناصر واجهة مستخدم من دفتر ملاحظات Jupyter. وكما هو الحال، فإن تطبيق الويب لا يزال مفيدًا بالتأكيد.
إذا كان لديك فضول لمعرفة المزيد، فقد تقدر هذا الفيديو على YouTube للنص وهذا الفيديو على YouTube لرؤية الكمبيوتر.
لاستخدام مجموعة كبيرة من النصوص، ستحتاج أولاً إلى إعداد ملف CSV أولاً.
ملحوظة
يستخدم المثال أدناه embetter لإنشاء التضمينات وumap لتقليل الأبعاد. ولكنك حر تمامًا في استخدام أي أداة تضمين نص تفضلها. سوف تحتاج إلى تثبيت هذه الأدوات بشكل منفصل. لاحظ أن إمبيتر يستخدم محولات الجملة تحت الغطاء.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
text_emb_pipeline = make_pipeline (
SentenceEncoder ( 'all-MiniLM-L6-v2' ),
UMAP ()
)
# Load sentences
sentences = list ( pd . read_csv ( "original.csv" )[ 'sentences' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]
df . to_csv ( "ready.csv" , index = False ) يمكنك الآن استخدام ملف ready.csv هذا لتطبيق بعض العلامات المجمعة.
python -m bulk text ready.csv
إذا كنت تبحث عن ملف مثال لتجربته، فيمكنك تنزيل ملف العرض التوضيحي .csv في هذا المستودع. تحتوي مجموعة البيانات هذه على مجموعة فرعية من مجموعة البيانات الموجودة على Kaggle. يمكنك العثور على النسخة الأصلية هنا.
يمكنك أيضًا تمرير عمود إضافي إلى ملف CSV الخاص بك يسمى "اللون". سيتم بعد ذلك استخدام هذا العمود لتلوين النقاط في الواجهة.
يمكنك أيضًا تمرير --keywords إلى تطبيق سطر الأوامر لتمييز العناصر التي تحتوي على كلمات رئيسية محددة.
python -m bulk text ready.csv --keywords "deliver,card,website,compliment"
يستخدم المثال أدناه مكتبة embetter لإنشاء مجموعة بيانات لوضع العلامات المجمعة على الصور.
ملحوظة
يستخدم المثال أدناه embetter لإنشاء التضمينات وumap لتقليل الأبعاد. ولكنك حر تمامًا في استخدام أي أداة تضمين نص تفضلها. سوف تحتاج إلى تثبيت هذه الأدوات بشكل منفصل. لاحظ أن الممبر يستخدم TIMM أسفل الغطاء.
import pathlib
import pandas as pd
from sklearn . pipeline import make_pipeline
from umap import UMAP
from sklearn . preprocessing import MinMaxScaler
# pip install "embetter[vision]"
from embetter . grab import ColumnGrabber
from embetter . vision import ImageLoader , TimmEncoder
# Build image encoding pipeline
image_emb_pipeline = make_pipeline (
ColumnGrabber ( "path" ),
ImageLoader ( convert = "RGB" ),
TimmEncoder ( 'xception' ),
UMAP (),
MinMaxScaler ()
)
# Make dataframe with image paths
img_paths = list ( pathlib . Path ( "downloads" , "pets" ). glob ( "*" ))
dataf = pd . DataFrame ({
"path" : [ str ( p ) for p in img_paths ]
})
# Make csv file with Umap'ed model layer
# Note! Bulk assumes the image path column to be called "path"!
X = image_emb_pipeline . fit_transform ( dataf )
dataf [ 'x' ] = X [:, 0 ]
dataf [ 'y' ] = X [:, 1 ]
dataf . to_csv ( "ready.csv" , index = False )يؤدي هذا إلى إنشاء ملف CSV يمكن تحميله بكميات كبيرة عبر؛
python -m bulk image ready.csv
يمكنك أيضًا إنشاء مجموعة من الصور المصغرة لصورك. يمكن أن يكون هذا مفيدًا إذا كنت تعمل مع مجموعة بيانات كبيرة.
python -m bulk util resize ready.csv ready2.csv temp
سيؤدي هذا إلى إنشاء مجلد يسمى temp يحتوي على جميع الصور التي تم تغيير حجمها. يمكنك بعد ذلك استخدام هذا المجلد كوسيطة --thumbnail-path .
python -m bulk image ready2.csv --thumbnail-path temp
يمكنك أيضًا استخدام مجموعة كبيرة لتنزيل بعض مجموعات البيانات للعب بها. لمزيد من المعلومات:
python -m bulk download --help
قد تساعدك الواجهة على وضع العلامات بسرعة كبيرة، لكن الملصقات نفسها قد تكون مزعجة إلى حد ما. حالة الاستخدام المقصودة لهذه الأداة هي إعداد مجموعات فرعية مثيرة للاهتمام لاستخدامها لاحقًا في prodi.gy.


