MedCalc Bench
1.0.0
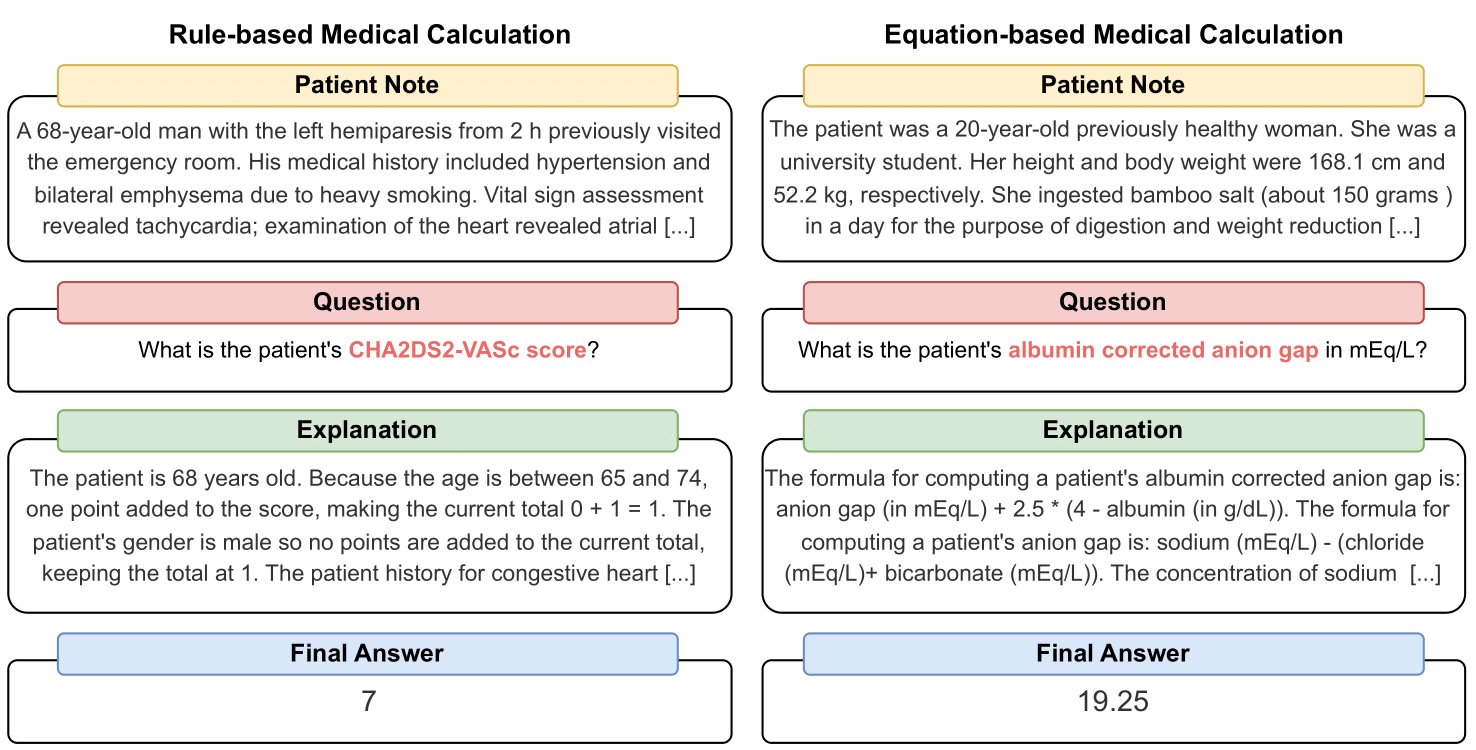
MedCalc-Bench هي أول مجموعة بيانات حسابية طبية تُستخدم لقياس قدرة ماجستير إدارة الأعمال على العمل كآلات حاسبة سريرية. يتكون كل مثيل في مجموعة البيانات من ملاحظة للمريض، وسؤال يطلب حساب قيمة سريرية محددة، وقيمة إجابة نهائية، وحل خطوة بخطوة يشرح كيفية الحصول على الإجابة النهائية. تغطي مجموعة البيانات الخاصة بنا 55 مهمة حسابية مختلفة والتي تكون إما حسابات قائمة على القواعد أو حسابات قائمة على المعادلات. تحتوي مجموعة البيانات هذه على مجموعة بيانات تدريب مكونة من 10,053 مثيلًا ومجموعة بيانات اختبار مكونة من 1,047 مثيلًا.
بشكل عام، نأمل أن تكون مجموعة البيانات والمقاييس المعيارية الخاصة بنا بمثابة دعوة لتحسين مهارات التفكير الحسابي لطلاب ماجستير القانون في البيئات الطبية.
النسخة الأولية لدينا متاحة على: https://arxiv.org/abs/2406.12036.
لتنزيل ملف CSV لمجموعة بيانات تقييم MedCalc-Bench، يرجى تنزيل الملف، test_data.csv داخل مجلد dataset في هذا المستودع. يمكنك أيضًا تنزيل مجموعة الاختبار المقسمة من HuggingFace على https://huggingface.co/datasets/ncbi/MedCalc-Bench.
بالإضافة إلى 1,047 حالة تقييم، نقدم أيضًا مجموعة بيانات تدريبية مكونة من 10,053 حالة يمكن استخدامها لضبط ماجستير إدارة الأعمال مفتوح المصدر (انظر القسم ج من الملحق). يمكن العثور على بيانات التدريب في ملف dataset/train_data.csv.zip ويمكن فك ضغطها للحصول على train_data.csv . يمكن أيضًا العثور على مجموعة بيانات التدريب هذه في قسم القطار الخاص برابط HuggingFace.
يحتوي كل مثيل في مجموعة البيانات على المعلومات التالية:
لتثبيت كافة الحزم اللازمة لهذا المشروع، يرجى تشغيل الأمر التالي: conda env create -f environment.yml . سيؤدي هذا الأمر إلى إنشاء بيئة medcalc-bench conda. لتشغيل نماذج OpenAI، ستحتاج إلى توفير مفتاح OpenAI الخاص بك في بيئة الشقة هذه. يمكنك القيام بذلك عن طريق تنفيذ الأمر التالي في بيئة medcalc-bench : export OPENAI_API_KEY = YOUR_API_KEY ، حيث YOUR_API_KEY هو مفتاح OpenAI API الخاص بك. ستحتاج أيضًا إلى توفير رمز HuggingFace المميز الخاص بك في هذه البيئة عن طريق تشغيل الأمر التالي: export HUGGINGFACE_TOKEN=your_hugging_face_token ، حيث يكون your_hugging_face_token هو رمز Huggingface_token الخاص بك.
لإعادة إنتاج الجدول 2 من الورقة، cd الأول في مجلد evaluation . بعد ذلك، يرجى تشغيل الأمر التالي: python run.py --model <model_name> and --prompt <prompt_style> .
خيارات --model هي أدناه:
خيارات --prompt هي أدناه:
من هذا، سوف تحصل على ملف jsonl واحد يُخرج حالة كل سؤال: عند تنفيذ run.py ، سيتم حفظ النتائج في ملف يسمى <model>_<prompt>.jsonl . يمكن العثور على هذا الملف في مجلد outputs .
سيكون لكل مثيل في jsonl البيانات التعريفية التالية المرتبطة به:
{
"Row Number": Row index of the item,
"Calculator Name": Name of calculation task,
"Calculator ID": ID of the calculator,
"Category": type of calculation (risk, severity, diagnosis for rule-based calculators and lab, risk, physical, date, dosage for equation-based calculators),
"Note ID": ID of the note taken directly from MedCalc-Bench,
"Patient Note": Paragraph which is the patient note taken directly from MedCalc-Bench,
"Question": Question asking for a specific medical value to be computed,
"LLM Answer": Final Answer Value from LLM,
"LLM Explanation": Step-by-Step explanation by LLM,
"Ground Truth Answer": Ground truth answer value,
"Ground Truth Explanation": Step-by-step ground truth explanation,
"Result": "Correct" or "Incorrect"
}
بالإضافة إلى ذلك، نقدم متوسط الدقة ونسبة الانحراف المعياري لكل فئة فرعية في ملف json بعنوان results_<model>_<prompt_style>.json . يمكن العثور على الدقة التراكمية والانحراف المعياري بين جميع الحالات البالغ عددها 1047 ضمن المفتاح "الشامل" لـ JSON. يمكن العثور على هذا الملف في مجلد results .
بالإضافة إلى نتائج الجدول 2 في الورقة الرئيسية، طلبنا أيضًا من طلاب LLM كتابة تعليمات برمجية لإجراء العمليات الحسابية بدلاً من جعل LLM يقوم بذلك بنفسه. يمكن العثور على نتائج ذلك في الملحق د. ونظرًا للحسابات المحدودة، قمنا فقط بتشغيل نتائج GPT-3.5 وGPT-4. لفحص المطالبات والتشغيل ضمن هذا الإعداد، يرجى فحص ملف generate_code_prompt.py الموجود في مجلد evaluation .
لتشغيل هذا الرمز، ما عليك سوى cd في مجلد evaluations وتشغيل ما يلي: python generate_code_prompt.py --gpt <gpt_model> . خيارات <gpt_model> هي إما 4 لتشغيل GPT-4 أو 35 لتشغيل GPT-3.5-turbo-16k. سيتم بعد ذلك حفظ النتائج في ملف jsonl باسم: code_exec_{model_name}.jsonl في مجلد outputs . لاحظ أنه في هذه الحالة، سيكون model_name هو gpt_4 إذا اخترت التشغيل باستخدام GPT-4. بخلاف ذلك، سيكون model_name هو gpt_35_16k إذا اخترت التشغيل باستخدام GPT-3.5-turbo.
البيانات التعريفية لكل مثيل في ملف jsonl لنتائج مترجم التعليمات البرمجية هي نفس معلومات المثيل المتوفرة في القسم أعلاه. والفرق الوحيد هو أننا نقوم بتخزين سجل دردشة LLM بين المستخدم والمساعد ولدينا مفتاح "سجل دردشة LLM" بدلاً من مفتاح "شرح LLM". بالإضافة إلى ذلك، يتم تخزين الفئة الفرعية والدقة الإجمالية في ملف JSON باسم results_<model_name>_code_augmented.json . يوجد JSON هذا في مجلد results .
تم دعم هذا البحث من قبل برنامج البحوث الداخلية التابع للمعاهد الوطنية للصحة، والمكتبة الوطنية للطب. بالإضافة إلى ذلك، تم إجراء المساهمات التي قدمها سورين دن باستخدام موارد دلتا للحوسبة والبيانات المتقدمة التي تدعمها المؤسسة الوطنية للعلوم (جائزة هاتف OAC: 2005572) وولاية إلينوي. دلتا هو جهد مشترك بين جامعة إلينوي أوربانا شامبين (UIUC) والمركز الوطني لتطبيقات الحوسبة الفائقة (NCSA).
لتنظيم ملاحظات المريض في MedCalc-Bench، نستخدم فقط ملاحظات المرضى المتاحة للجمهور من مقالات تقارير الحالة المنشورة في PubMed Central والمقالات القصيرة للمرضى المجهولين التي أنشأها الأطباء. وعلى هذا النحو، لم يتم الكشف عن أي معلومات صحية شخصية محددة في هذه الدراسة. في حين أن MedCalc-Bench مصمم لتقييم قدرات الحساب الطبي لحاملي شهادة LLM، تجدر الإشارة إلى أن مجموعة البيانات ليست مخصصة للاستخدام التشخيصي المباشر أو اتخاذ القرارات الطبية دون مراجعة ومراقبة من قبل أخصائي سريري. لا ينبغي للأفراد تغيير سلوكهم الصحي على أساس دراستنا فقط.
كما هو موضح في القسم 1، تُستخدم الآلات الحاسبة الطبية بشكل شائع في البيئة السريرية. مع الاهتمام المتزايد بسرعة باستخدام LLMs للتطبيقات الخاصة بالمجال، قد يقوم ممارسون الرعاية الصحية مباشرة بمطالبة برامج الدردشة مثل ChatGPT لأداء مهام الحساب الطبي. ومع ذلك، فإن قدرات LLMs في هذه المهام غير معروفة حاليًا. نظرًا لأن الرعاية الصحية مجال عالي المخاطر والحسابات الطبية الخاطئة يمكن أن تؤدي إلى عواقب وخيمة، بما في ذلك التشخيص الخاطئ وخطط العلاج غير المناسبة والضرر المحتمل للمرضى، فمن الضروري إجراء تقييم شامل لأداء LLMs في الحسابات الطبية. من المثير للدهشة أن نتائج التقييم في مجموعة بيانات MedCalc-Bench الخاصة بنا تظهر أن جميع طلاب ماجستير القانون الذين تمت دراستهم يعانون في مهام الحساب الطبي. يحقق الطراز GPT-4 الأكثر قدرة دقة تصل إلى 50% فقط من خلال التعلم بلقطة واحدة وتحفيز سلسلة الأفكار. على هذا النحو، تشير دراستنا إلى أن حاملي شهادات الماجستير الحاليين ليسوا جاهزين بعد لاستخدامهم في الحسابات الطبية. تجدر الإشارة إلى أنه في حين أن الدرجات العالية في MedCalc-Bench لا تضمن التميز في مهام الحساب الطبي، فإن الفشل في مجموعة البيانات هذه يشير إلى أنه لا يجب أخذ النماذج في الاعتبار لمثل هذه الأغراض على الإطلاق. بمعنى آخر، نعتقد أن اجتياز MedCalc-Bench يجب أن يكون شرطًا ضروريًا (لكنه غير كافٍ) لاستخدام النموذج في الحساب الطبي
بالنسبة لأية تغييرات في مجموعة البيانات هذه (أي إضافة ملاحظات أو آلات حاسبة جديدة)، سنقوم بتحديث تعليمات README وtest_set.csv وtrain_set.csv. سنستمر في الاحتفاظ بالإصدارات القديمة من مجموعات البيانات هذه في archive/ مجلد. سنقوم أيضًا بتحديث مجموعات التدريب والاختبار لـ HuggingFace أيضًا.
تعرض هذه الأداة نتائج الأبحاث التي أجريت في فرع علم الأحياء الحسابي، NCBI/NLM. المعلومات الواردة في هذا الموقع ليست مخصصة للاستخدام التشخيصي المباشر أو اتخاذ القرارات الطبية دون مراجعة ومراقبة من قبل أخصائي سريري. لا ينبغي للأفراد تغيير سلوكهم الصحي على أساس المعلومات الواردة في هذا الموقع فقط. لا تتحقق المعاهد الوطنية للصحة بشكل مستقل من صحة أو فائدة المعلومات التي تنتجها هذه الأداة. إذا كانت لديك أسئلة حول المعلومات الواردة في هذا الموقع، يرجى مراجعة أخصائي الرعاية الصحية. يتوفر المزيد من المعلومات حول سياسة إخلاء المسؤولية الخاصة بـ NCBI.
اعتمادًا على الآلة الحاسبة، تتكون مجموعة البيانات الخاصة بنا من ملاحظات تم تصميمها إما من وظائف قائمة على القوالب تم تنفيذها في لغة Python، أو مكتوبة بخط اليد من قبل الأطباء، أو مأخوذة من مجموعة البيانات الخاصة بنا، Open-Patients.
Open-Patients عبارة عن مجموعة بيانات مجمعة تضم 180 ألف ملاحظة للمرضى تأتي من ثلاثة مصادر مختلفة. لدينا إذن لاستخدام مجموعة البيانات من المصادر الثلاثة. المصدر الأول هو أسئلة USMLE من MedQA والتي تم إصدارها بموجب ترخيص MIT. المصدر الثاني لمجموعة البيانات الخاصة بنا هو Trec Clinical Decision Support وTrec Clinical Trial المتاحين لإعادة التوزيع لأنهما مجموعتا بيانات مملوكتان للحكومة وتم إصدارهما للعامة. أخيرًا، تم إصدار PMC-Patients بموجب ترخيص CC-BY-SA 4.0 ولذلك لدينا إذن لدمج PMC-Patients داخل Open-Patients وMedCalc-Bench، ولكن يجب إصدار مجموعة البيانات بموجب نفس الترخيص. ومن ثم، فإن مصدر ملاحظاتنا، Open-Patients، ومجموعة البيانات المنسقة منه، MedCalc-Bench، تم إصدارهما بموجب ترخيص CC-BY-SA 4.0.
استنادًا إلى مبررات قواعد الترخيص، يتوافق كل من Open-Patients وMedCalc-Bench مع ترخيص CC-BY-SA 4.0، لكن مؤلفي هذه الورقة سيتحملون المسؤولية الكاملة في حالة انتهاك الحقوق.
@misc { khandekar2024medcalcbench ,
title = { MedCalc-Bench: Evaluating Large Language Models for Medical Calculations } ,
author = { Nikhil Khandekar and Qiao Jin and Guangzhi Xiong and Soren Dunn and Serina S Applebaum and Zain Anwar and Maame Sarfo-Gyamfi and Conrad W Safranek and Abid A Anwar and Andrew Zhang and Aidan Gilson and Maxwell B Singer and Amisha Dave and Andrew Taylor and Aidong Zhang and Qingyu Chen and Zhiyong Lu } ,
year = { 2024 } ,
eprint = { 2406.12036 } ,
archivePrefix = { arXiv } ,
primaryClass = { id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.' }
}

