gpt neox
GPT-NeoX 2.0
يسجل هذا المستودع مكتبة EleutherAI لتدريب نماذج لغوية واسعة النطاق على وحدات معالجة الرسومات. يعتمد إطار عملنا الحالي على نموذج لغة Megatron من NVIDIA وقد تم تعزيزه بتقنيات من DeepSpeed بالإضافة إلى بعض التحسينات الجديدة. نحن نهدف إلى جعل هذا الريبو مكانًا مركزيًا وسهل الوصول إليه لجمع التقنيات اللازمة لتدريب نماذج لغة الانحدار الذاتي واسعة النطاق، وتسريع البحث في التدريب على نطاق واسع. يتم استخدام هذه المكتبة على نطاق واسع في المختبرات الأكاديمية والصناعية والحكومية، بما في ذلك من قبل الباحثين في مختبر أوك ريدج الوطني، وCarperAI، وStability AI، وTogether.ai، وجامعة كوريا، وجامعة كارنيجي ميلون، وجامعة طوكيو وغيرها. بشكل فريد من بين المكتبات المماثلة، تدعم GPT-NeoX مجموعة واسعة من الأنظمة والأجهزة، بما في ذلك الإطلاق عبر Slurm، وMPI، وIBM Job Step Manager، وتم تشغيلها على نطاق واسع على AWS، وCoreWeave، وORNL Summit، وORNL Frontier، وLUMI، و آحرون.
إذا كنت لا تتطلع إلى تدريب النماذج باستخدام مليارات المعلمات من البداية، فمن المحتمل أن تكون هذه هي المكتبة الخاطئة التي يجب استخدامها. بالنسبة لاحتياجات الاستدلال العامة، نوصيك باستخدام مكتبة Hugging Face transformers بدلاً من ذلك والتي تدعم نماذج GPT-NeoX.
تستفيد GPT-NeoX من العديد من الميزات والتقنيات نفسها التي تتمتع بها مكتبة Megatron-DeepSpeed الشهيرة، ولكن مع زيادة كبيرة في سهولة الاستخدام وتحسينات جديدة. تشمل الميزات الرئيسية ما يلي:
[9/9/2024] نحن ندعم الآن تعلم التفضيلات عبر DPO وKTO ونمذجة المكافآت
[9/9/2024] نحن ندعم الآن التكامل مع Comet ML، وهي منصة لمراقبة التعلم الآلي
[21/05/2024] نحن ندعم الآن RWKV بتوازي خطوط الأنابيب!. راجع العلاقات العامة لخط أنابيب RWKV وRWKV+
[21/03/2024] نحن ندعم الآن خليط الخبراء (MoE)
[17/3/2024] نحن ندعم الآن وحدات معالجة الرسومات AMD MI250X
[15/03/2024] نحن الآن ندعم لعبة مامبا بالتوازي الموتر! انظر العلاقات العامة
[8/10/2023] نحن ندعم الآن عملية التحقق باستخدام AWS S3! التنشيط باستخدام خيار التكوين s3_path (لمزيد من التفاصيل، راجع العلاقات العامة)
[20/09/2023] اعتبارًا من رقم 1035، قمنا بإيقاف Flash Attention 0.x و1.x، وقمنا بترحيل الدعم إلى Flash Attention 2.x. لا نعتقد أن هذا سيسبب مشاكل، ولكن إذا كانت لديك حالة استخدام محددة تتطلب دعم الفلاش القديم باستخدام أحدث إصدار من GPT-NeoX، فيرجى إثارة مشكلة.
[8/10/2023] لدينا دعم تجريبي لـ LLaMA 2 وFlash Attention v2 مدعوم في مشروع math-lm الخاص بنا والذي سيتم نشره في وقت لاحق من هذا الشهر.
[2023/05/17] بعد إصلاح بعض الأخطاء المتنوعة، أصبحنا ندعم الآن الإصدار bf16 بشكل كامل.
[4/11/2023] لقد قمنا بترقية تطبيق Flash Attention الخاص بنا ليدعم الآن التضمينات الموضعية لـ Alibi.
[3/9/2023] لقد أصدرنا GPT-NeoX 2.0.0، وهو إصدار مطور مبني على أحدث DeepSpeed والذي ستتم مزامنته بانتظام مع المضي قدمًا.
قبل 9/3/2023، اعتمدت GPT-NeoX على DeeperSpeed، والتي كانت مبنية على نسخة قديمة من DeepSpeed (0.3.15). من أجل الانتقال إلى أحدث إصدار من DeepSpeed مع السماح للمستخدمين بالوصول إلى الإصدارات القديمة من GPT-NeoX وDeeperSpeed، قدمنا إصدارين لكلتا المكتبتين:
تم تطوير واختبار قاعدة التعليمات البرمجية هذه بشكل أساسي لـ Python 3.8-3.10 وPyTorch 1.8-2.0. وهذا ليس مطلبًا صارمًا، وقد تعمل الإصدارات والمجموعات الأخرى من المكتبات.
لتثبيت التبعيات الأساسية المتبقية، قم بتشغيل:
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # optional, if logging using WandB
pip install -r requirements/requirements-tensorboard.txt # optional, if logging via tensorboard
pip install -r requirements/requirements-comet.txt # optional, if logging via Cometمن جذر المستودع.
تحذير
تعتمد قاعدة التعليمات البرمجية الخاصة بنا على DeeperSpeed، وهو فرعنا لمكتبة DeepSpeed مع بعض التغييرات المضافة. نوصي بشدة باستخدام Anaconda، أو جهاز افتراضي، أو أي شكل آخر من أشكال عزل البيئة قبل المتابعة. قد يؤدي الفشل في القيام بذلك إلى تعطل المستودعات الأخرى التي تعتمد على DeepSpeed.
نحن ندعم الآن وحدات معالجة الرسومات AMD (MI100، MI250X) من خلال تجميع النواة المندمجة JIT. سيتم بناء النوى المندمجة وتحميلها حسب الحاجة. لتجنب الانتظار أثناء بدء المهمة، يمكنك أيضًا القيام بما يلي للإنشاء المسبق اليدوي:
python
from megatron . fused_kernels import load
load () سيؤدي هذا تلقائيًا إلى تكييف عملية البناء عبر بائعي وحدات معالجة الرسومات المختلفين (AMD وNVIDIA) دون إجراء تغييرات على التعليمات البرمجية الخاصة بالنظام الأساسي. لمزيد من اختبار النوى المندمجة باستخدام pytest ، استخدم pytest tests/model/test_fused_kernels.py
لاستخدام Flash-Attention، قم بتثبيت التبعيات الإضافية في ./requirements/requirements-flashattention.txt وقم بتعيين نوع الانتباه في التكوين الخاص بك وفقًا لذلك (راجع التكوينات). يمكن أن يوفر هذا عمليات تسريع كبيرة مقارنة بالاهتمام المنتظم في بعض بنيات وحدة معالجة الرسومات، بما في ذلك وحدات معالجة الرسومات Ampere (مثل A100s)؛ راجع المستودع لمزيد من التفاصيل.
تدريب دعم NeoX وDeep(er)Speed على عدة عقد مختلفة ولديك خيار استخدام مجموعة متنوعة من قاذفات مختلفة لتنسيق المهام متعددة العقد.
بشكل عام، يجب أن يكون هناك "ملف مضيف" يمكن الوصول إليه في مكان ما بالتنسيق:
node1_ip slots=8
node2_ip slots=8 حيث يحتوي العمود الأول على عنوان IP لكل عقدة في الإعداد الخاص بك وعدد الفتحات هو عدد وحدات معالجة الرسومات التي يمكن للعقدة الوصول إليها. في التكوين الخاص بك، يجب عليك تمرير المسار إلى ملف المضيف باستخدام "hostfile": "/path/to/hostfile" . وبدلاً من ذلك، يمكن أن يكون المسار إلى ملف المضيف في متغير البيئة DLTS_HOSTFILE .
pdsh هو المشغل الافتراضي، وإذا كنت تستخدم pdsh ، فكل ما يجب عليك فعله (إلى جانب التأكد من تثبيت pdsh في بيئتك) هو تعيين {"launcher": "pdsh"} في ملفات التكوين الخاصة بك.
إذا كنت تستخدم MPI، فيجب عليك تحديد مكتبة MPI (يدعم DeepSpeed/GPT-NeoX حاليًا mvapich و openmpi و mpich و impi ، على الرغم من أن openmpi هو الأكثر استخدامًا واختبارًا) بالإضافة إلى تمرير علامة deepspeed_mpi في ملف التكوين الخاص بك:
{
"launcher" : " openmpi " ,
"deepspeed_mpi" : true
} بعد إعداد بيئتك بشكل صحيح وملفات التكوين الصحيحة، يمكنك استخدام deepy.py مثل برنامج python النصي العادي وبدء (على سبيل المثال) مهمة تدريبية باستخدام:
python3 deepy.py train.py /path/to/configs/my_model.yml
يمكن أن يكون استخدام Slurm أكثر تعقيدًا قليلاً. كما هو الحال مع MPI، يجب عليك إضافة ما يلي إلى التكوين الخاص بك:
{
"launcher" : " slurm " ,
"deepspeed_slurm" : true
} إذا لم يكن لديك وصول ssh إلى عقد الحوسبة في مجموعة Slurm الخاصة بك، فأنت بحاجة إلى إضافة {"no_ssh_check": true}
هناك العديد من الحالات التي لا تكون فيها خيارات التشغيل الافتراضية المذكورة أعلاه كافية
في هذه الحالات، ستحتاج إلى تعديل الأداة المساعدة DeepSpeed multinode runner لدعم حالة الاستخدام الخاصة بك. وبشكل عام، تندرج هذه التحسينات ضمن فئتين:
في هذه الحالة، يجب عليك إضافة فئة تشغيل متعددة العقد جديدة إلى deepspeed/launcher/multinode_runner.py وإظهارها كخيار تكوين في GPT-NeoX. توجد أمثلة على كيفية قيامنا بذلك لـ Summit JSRun في التزام DeeperSpeed والتزام GPT-NeoX، على التوالي.
لقد واجهنا العديد من الحالات التي نرغب فيها في تعديل أمر تشغيل MPI/Slurm من أجل التحسين أو التصحيح (على سبيل المثال، تعديل ربط وحدة المعالجة المركزية Slurm srun أو وضع علامة على سجلات MPI بالرتبة). في هذه الحالة، يجب عليك تعديل أمر تشغيل فئة المشغل متعدد العقد ضمن أسلوب get_cmd الخاص به (على سبيل المثال، mpirun_cmd لـ OpenMPI). توجد أمثلة حول كيفية قيامنا بذلك لتوفير أوامر تشغيل مُحسّنة ومُصنفة باستخدام Slurm وOpenMPI لمجموعة Stability في فرع DeeperSpeed هذا
بشكل عام، لن تتمكن من الحصول على ملف مضيف ثابت واحد، لذلك تحتاج إلى برنامج نصي لإنشاء ملف ديناميكي عندما تبدأ مهمتك. مثال على البرنامج النصي لإنشاء ملف مضيف ديناميكيًا باستخدام Slurm و8 وحدات معالجة رسومات لكل عقدة هو:
#! /bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# need to add the current slurm jobid to hostfile name so that we don't add to previous hostfile
hostfile=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# be extra sure we aren't appending to a previous hostfile
rm $hostfile & > /dev/null
# loop over the node names
for i in ` scontrol show hostnames $SLURM_NODELIST `
do
# add a line to the hostfile
echo $i slots= $GPUS_PER_NODE >> $hostfile
done $SLURM_JOBID و $SLURM_NODELIST هما متغيرات البيئة التي سيقوم Slurm بإنشائها لك. راجع الوثائق المجمعة للحصول على قائمة كاملة بمتغيرات بيئة Slurm المتوفرة والتي تم تعيينها في وقت إنشاء الوظيفة.
بعد ذلك، يمكنك إنشاء برنامج نصي متقطع لبدء مهمة GPT-NeoX الخاصة بك. سيبدو البرنامج النصي البسيط على مجموعة قائمة على Slurm مع 8 وحدات معالجة رسوميات لكل عقدة كما يلي:
#! /bin/bash
# SBATCH --job-name="neox"
# SBATCH --partition=your-partition
# SBATCH --nodes=1
# SBATCH --ntasks-per-node=8
# SBATCH --gres=gpu:8
# Some potentially useful distributed environment variables
export HOSTNAMES= ` scontrol show hostnames " $SLURM_JOB_NODELIST " `
export MASTER_ADDR= $( scontrol show hostnames " $SLURM_JOB_NODELIST " | head -n 1 )
export MASTER_PORT=12802
export COUNT_NODE= ` scontrol show hostnames " $SLURM_JOB_NODELIST " | wc -l `
# Your hostfile creation script from above
./write_hostfile.sh
# Tell DeepSpeed where to find our generated hostfile via DLTS_HOSTFILE
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# Launch training
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
يمكنك بعد ذلك بدء التدريب باستخدام sbatch my_sbatch_script.sh
نوفر أيضًا تكوين Dockerfile وdocker-compose إذا كنت تفضل تشغيل NeoX في حاوية.
متطلبات تشغيل الحاوية هي أن يكون لديك برامج تشغيل GPU مناسبة، وتثبيت محدث لـ Docker، ومجموعة أدوات nvidia-container-toolkit. لاختبار ما إذا كان التثبيت جيدًا أم لا، يمكنك استخدام "نموذج عبء العمل" الخاص بهم، وهو:
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
بشرط تشغيل ذلك، ستحتاج إلى تصدير NEOX_DATA_PATH وNEOX_CHECKPOINT_PATH في بيئتك لتحديد دليل البيانات ودليل لتخزين وتحميل نقاط التفتيش:
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 #or wherever your data is stored on your system
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
وبعد ذلك، من دليل gpt-neox، يمكنك إنشاء الصورة وتشغيل الصدفة في حاوية بها
docker compose run gpt-neox bash
بعد الإنشاء، يجب أن تكون قادرًا على القيام بذلك:
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
للحصول على وظيفة طويلة الأمد، يجب عليك الركض
docker compose up -d
لتشغيل الحاوية في الوضع المنفصل، ثم تشغيلها في جلسة طرفية منفصلة
docker compose exec gpt-neox bash
يمكنك بعد ذلك تشغيل أي مهمة تريدها من داخل الحاوية.
تشمل المخاوف عند التشغيل لفترة طويلة أو في الوضع المنفصل
إذا كنت تفضل تشغيل صورة الحاوية المعدة مسبقًا من dockerhub، فيمكنك تشغيل أوامر docker compose باستخدام -f docker-compose-dockerhub.yml بدلاً من ذلك، على سبيل المثال،
docker compose run -f docker-compose-dockerhub.yml gpt-neox bash
يجب تشغيل جميع الوظائف باستخدام deepy.py ، وهو عبارة عن غلاف حول مشغل deepspeed .
نقدم حاليًا ثلاث وظائف رئيسية:
train.py للتدريب وضبط النماذج.eval.py لتقييم نموذج مُدرب باستخدام أداة تقييم نموذج اللغة.generate.py لأخذ عينات من النص من نموذج مُدرب.والتي يمكن إطلاقها مع:
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]على سبيل المثال، لبدء التدريب، يمكنك تشغيل
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.ymlلمزيد من التفاصيل حول كل نقطة دخول، راجع التدريب والضبط والاستدلال والتقييم على التوالي.
يتم تعريف معلمات GPT-NeoX في ملف تكوين YAML الذي يتم تمريره إلى مشغل Deepy.py. لقد قدمنا بعض الأمثلة على ملفات .yml في التكوينات، والتي تعرض مجموعة متنوعة من الميزات وأحجام النماذج.
هذه الملفات كاملة بشكل عام، ولكنها غير مثالية. على سبيل المثال، اعتمادًا على تكوين وحدة معالجة الرسومات الخاصة بك، قد تحتاج إلى تغيير بعض الإعدادات مثل pipe-parallel-size أو model-parallel-size لزيادة أو تقليل درجة التوازي أو train_micro_batch_size_per_gpu أو gradient-accumulation-steps لتعديل حجم الدفعة الإعدادات ذات الصلة، أو أمر zero_optimization لتعديل كيفية توازي حالات المحسن عبر العمال.
للحصول على دليل أكثر تفصيلاً حول الميزات المتاحة وكيفية تكوينها، راجع ملف التكوين README، وللحصول على توثيق لكل وسيطة محتملة، راجع configs/neox_arguments.md.
يتضمن GPT-NeoX تطبيقات متخصصة متعددة لوزارة التربية والتعليم. للاختيار بينهما، حدد moe_type of megablocks (افتراضي) أو deepspeed .
ويعتمد كلاهما على إطار التوازي DeepSpeed MoE، الذي يدعم توازي بيانات الخبراء والموترين. كلاهما يسمح لك بالتبديل بين إسقاط الرمز المميز وعدم إسقاطه (افتراضي، وهذا هو ما تم تصميم Megablocks من أجله). توجيه Sinkhorn سيأتي قريبًا!
للحصول على مثال للتكوين الأساسي الكامل، راجع configs/125M-dmoe.yml (لـ Megablocks Dropless) أو configs/125M-moe.yml.
معظم وسيطات التكوين المتعلقة بـ MoE تكون مسبوقة بـ moe . بعض معلمات التكوين الشائعة وإعداداتها الافتراضية هي كما يلي:
moe_type: megablocks
moe_num_experts: 1 # 1 disables MoE. 8 is a reasonable value.
moe_loss_coeff: 0.1
expert_interval: 2 # See details below
enable_expert_tensor_parallelism: false # See details below
moe_expert_parallel_size: 1 # See details below
moe_token_dropping: false
يمكن تكوين DeepSpeed بشكل أكبر باستخدام ما يلي:
moe_top_k: 1
moe_min_capacity: 4
moe_train_capacity_factor: 1.0 # Setting to 1.0
moe_eval_capacity_factor: 1.0 # Setting to 1.0
توجد طبقة MoE واحدة في كل طبقات محولات expert_interval بما في ذلك الطبقة الأولى، بحيث يبلغ إجمالي 12 طبقة:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
سيكون الخبراء في هذه الطبقات:
0, 2, 4, 6, 8, 10
افتراضيًا، نستخدم توازي بيانات الخبراء، لذلك سيتم استخدام أي توازي موتر متاح ( model_parallel_size ) للتوجيه الخبير. على سبيل المثال، في ضوء ما يلي:
expert_parallel_size: 4
model_parallel_size: 2 # aka tensor parallelism
مع 32 وحدة معالجة رسوميات، سيكون السلوك كما يلي:
expert_parallel_size == model_parallel_size . يؤدي إعداد enable_expert_tensor_parallelism إلى تمكين توازي بيانات الموتر الخبير (TED). وبالتالي فإن طريقة تفسير ما سبق هي:
expert_parallel_size == 1 أو model_parallel_size == 1 .لذا لاحظ أن DP يجب أن يكون قابلاً للقسمة على (MP * EP). لمزيد من التفاصيل، راجع ورقة TED.
لم يتم دعم توازي خطوط الأنابيب حتى الآن - قريبًا!
تتوفر العديد من مجموعات البيانات التي تم تكوينها مسبقًا، بما في ذلك معظم المكونات من Pile، بالإضافة إلى مجموعة Pile Train نفسها، من أجل الترميز المباشر باستخدام نقطة إدخال prepare_data.py .
على سبيل المثال، لتنزيل مجموعة بيانات enwik8 وترميزها باستخدام GPT2 Tokenizer، وحفظها في ./data يمكنك تشغيلها:
python prepare_data.py -d ./data
أو قطعة واحدة من الكومة ( pile_subset ) باستخدام الرمز المميز GPT-NeoX-20B (بافتراض أنك قمت بحفظها في ./20B_checkpoints/20B_tokenizer.json ):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
سيتم حفظ البيانات المميزة في ملفين: [data-dir]/[dataset-name]/[dataset-name]_text_document.bin و [data-dir]/[dataset-name]/[dataset-name]_text_document.idx . ستحتاج إلى إضافة البادئة التي يشاركها كلا الملفين إلى ملف تكوين التدريب الخاص بك ضمن حقل data-path . على سبيل المثال:
" data-path " : " ./data/enwik8/enwik8_text_document " , لإعداد مجموعة البيانات الخاصة بك للتدريب باستخدام البيانات المخصصة، قم بتنسيقها كملف كبير بتنسيق jsonl بحيث يكون كل عنصر في قائمة القواميس مستندًا منفصلاً. يجب تجميع نص المستند تحت مفتاح JSON واحد، أي "text" . لن يتم استخدام أي بيانات مساعدة مخزنة في حقول أخرى.
تأكد بعد ذلك من تنزيل مصطلح GPT2 tokenizer، ودمج الملفات من الروابط التالية:
أو استخدم رمز 20B (الذي يتطلب ملف Vocab واحدًا فقط):
(بدلاً من ذلك، يمكنك توفير أي ملف رمز مميز يمكن تحميله بواسطة مكتبة الرموز المميزة الخاصة بـ Hugging Face باستخدام أمر Tokenizer.from_pretrained() )
يمكنك الآن إنشاء ترميز مسبق لبياناتك باستخدام tools/datasets/preprocess_data.py ، والوسائط الخاصة بها مفصلة أدناه:
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
optional arguments:
-h, --help show this help message and exit
input data:
--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
space separate listed of keys to extract from jsonl. Default: text
--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.
tokenizer:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
What type of tokenizer to use.
--vocab-file VOCAB_FILE
Path to the vocab file
--merge-file MERGE_FILE
Path to the BPE merge file (if necessary).
--append-eod Append an <eod> token to the end of a document.
--ftfy Use ftfy to clean text
output data:
--output-prefix OUTPUT_PREFIX
Path to binary output file without suffix
--dataset-impl {lazy,cached,mmap}
Dataset implementation to use. Default: mmap
runtime:
--workers WORKERS Number of worker processes to launch
--log-interval LOG_INTERVAL
Interval between progress updates
على سبيل المثال:
python tools/datasets/preprocess_data.py
--input ./data/mydataset.jsonl.zst
--output-prefix ./data/mydataset
--vocab ./data/gpt2-vocab.json
--merge-file gpt2-merges.txt
--dataset-impl mmap
--tokenizer-type GPT2BPETokenizer
--append-eodيمكنك بعد ذلك تشغيل التدريب مع إضافة الإعدادات التالية إلى ملف التكوين الخاص بك:
" data-path " : " data/mydataset_text_document " , يتم إطلاق التدريب باستخدام deepy.py ، وهو غلاف حول مشغل DeepSpeed، والذي يطلق نفس البرنامج النصي بالتوازي عبر العديد من وحدات معالجة الرسومات/العقد.
نمط الاستخدام العام هو:
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...يمكنك تمرير عدد عشوائي من التكوينات التي سيتم دمجها جميعًا في وقت التشغيل.
يمكنك أيضًا اختياريًا تمرير بادئة التكوين، والتي ستفترض أن جميع التكوينات الخاصة بك موجودة في نفس المجلد وإلحاق تلك البادئة بمسارها.
على سبيل المثال:
python ./deepy.py train.py -d configs 125M.yml local_setup.yml سيؤدي هذا إلى نشر البرنامج النصي train.py على جميع العقد بعملية واحدة لكل وحدة معالجة رسومات. يتم تحديد العقد العاملة وعدد وحدات معالجة الرسومات في ملف /job/hostfile (راجع وثائق المعلمات)، أو يمكن ببساطة تمريرها كـ num_gpus arg إذا كانت تعمل على إعداد عقدة واحدة.
على الرغم من أن هذا ليس ضروريًا تمامًا، إلا أننا نجد أنه من المفيد تحديد معلمات النموذج في ملف تكوين واحد (على سبيل المثال، configs/125M.yml ) ومعلمات مسار البيانات في ملف آخر (على سبيل المثال، configs/local_setup.yml ).
GPT-NeoX-20B هو نموذج لغة انحدار ذاتي مكون من 20 مليار معلمة تم تدريبه على Pile. يمكن العثور على التفاصيل الفنية حول GPT-NeoX-20B في الورقة المرتبطة. يتوفر ملف التكوين لهذا النموذج على ./configs/20B.yml ومدرج في روابط التنزيل أدناه.
أوزان رفيعة - (لا توجد حالات محسّنة، للاستدلال أو الضبط الدقيق، 39 جيجابايت)
للتنزيل من سطر الأوامر إلى مجلد باسم 20B_checkpoints ، استخدم الأمر التالي:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpointsالأوزان الكاملة - (بما في ذلك حالات المُحسِّن، 268 جيجابايت)
للتنزيل من سطر الأوامر إلى مجلد باسم 20B_checkpoints ، استخدم الأمر التالي:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpointsيمكن بدلاً من ذلك تنزيل الأوزان باستخدام عميل BitTorrent. يمكن تنزيل ملفات التورنت من هنا: أوزان ضئيلة، أوزان كاملة.
لدينا أيضًا 150 نقطة تفتيش محفوظة أثناء التدريب، نقطة واحدة كل 1000 خطوة. نحن نعمل على اكتشاف أفضل السبل لخدمة هذه النقاط على نطاق واسع، ولكن في الوقت نفسه، يمكن للأشخاص المهتمين بالعمل مع نقاط التفتيش المدربة جزئيًا مراسلتنا عبر البريد الإلكتروني على [email protected] لترتيب الوصول.
إن Pythia Scaling Suite عبارة عن مجموعة من النماذج تتراوح من 70 مليون معلمة إلى 12 مليار معلمة تم تدريبها على Pile بهدف تعزيز البحث حول قابلية التفسير وديناميكيات التدريب لنماذج اللغات الكبيرة. يمكن العثور على مزيد من التفاصيل حول المشروع وروابط النماذج في المقالة وعلى GitHub الخاص بالمشروع.
يعد مشروع Polyglot بمثابة جهد لتدريب نماذج قوية من اللغات غير الإنجليزية المدربة مسبقًا لتعزيز إمكانية الوصول إلى هذه التكنولوجيا للباحثين خارج القوى المهيمنة في التعلم الآلي. قامت EleutherAI بتدريب وإصدار نماذج اللغة الكورية ذات المعلمات 1.3B و3.8B و5.8B، والتي يتفوق أكبرها على جميع نماذج اللغة الأخرى المتاحة للجمهور في مهام اللغة الكورية. يمكن العثور على مزيد من التفاصيل حول المشروع وروابط النماذج هنا.
بالنسبة لمعظم الاستخدامات، نوصي بنشر النماذج التي تم تدريبها باستخدام مكتبة GPT-NeoX عبر مكتبة Hugging Face Transformers التي تم تحسينها بشكل أفضل للاستدلال.
نحن ندعم ثلاثة أنواع من التوليد من نموذج تم تدريبه مسبقًا:
يمكن إطلاق جميع الأنواع الثلاثة لإنشاء النص عبر python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.yml مع تعيين القيم المناسبة في configs/text_generation.yml .
يدعم GPT-NeoX التقييم في المهام النهائية من خلال أداة تقييم نموذج اللغة.
لتقييم نموذج مُدرب على أداة التقييم، ما عليك سوى تشغيل:
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... taskn حيث --eval_tasks عبارة عن قائمة بمهام التقييم متبوعة بمسافات، على سبيل المثال --eval_tasks lambada hellaswag piqa sciq . للحصول على تفاصيل حول جميع المهام المتاحة، راجع lm-evaluation-harness repo.
تم تحسين GPT-NeoX بشكل كبير للتدريب فقط، كما أن نقاط التحقق لنموذج GPT-NeoX غير متوافقة مع مكتبات التعلم العميق الأخرى. لجعل النماذج قابلة للتحميل والمشاركة بسهولة مع المستخدمين النهائيين، ولمزيد من التصدير إلى أطر عمل أخرى مختلفة، يدعم GPT-NeoX تحويل نقاط التفتيش إلى تنسيق Hugging Face Transformers.
على الرغم من أن NeoX يدعم عددًا من التكوينات المعمارية المختلفة، بما في ذلك التضمينات الموضعية لـ AliBi، إلا أنه لا يتم تعيين كل هذه التكوينات بشكل واضح على التكوينات المدعومة داخل Hugging Face Transformers.
يدعم NeoX تصدير النماذج المتوافقة إلى البنى التالية:
سيتطلب تدريب نموذج لا يتناسب مع أحد بنيات Hugging Face Transformers بشكل نظيف كتابة كود النمذجة المخصص للنموذج الذي تم تصديره.
لتحويل نقطة تفتيش مكتبة GPT-NeoX إلى تنسيق Hugging Face-loadable، قم بتشغيل:
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}ثم لتحميل نموذج إلى Hugging Face Hub، قم بتشغيل:
huggingface-cli login
python ./tools/ckpts/upload.pyوأدخل المعلومات المطلوبة، بما في ذلك رمز مستخدم محور التردد العالي.
توفر NeoX العديد من الأدوات المساعدة لتحويل نقطة تفتيش نموذجية مُدربة مسبقًا إلى تنسيق يمكن تدريبه داخل المكتبة.
يمكن تحميل النماذج أو عائلات النماذج التالية في GPT-NeoX:
نحن نقدم أداتين مساعدتين للتحويل من تنسيقين مختلفين لنقاط التفتيش إلى تنسيق متوافق مع GPT-NeoX.
لتحويل نقطة تفتيش Llama 1 أو Llama 2 الموزعة بواسطة Meta AI من تنسيق الملف الأصلي (يمكن تنزيله هنا أو هنا) إلى مكتبة GPT-NeoX، قم بتشغيل
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
للتحويل من نموذج Hugging Face إلى نموذج NeoX قابل للتحميل، قم بتشغيل tools/ckpts/convert_hf_to_sequential.py . راجع الوثائق داخل هذا الملف لمزيد من الخيارات.
بالإضافة إلى تخزين السجلات محليًا، فإننا نقدم دعمًا مدمجًا لاثنين من إطارات مراقبة التجارب الشائعة: Weights & Biases، وTensorBoard، وComet
الأوزان والتحيزات لتسجيل تجاربنا عبارة عن منصة لمراقبة التعلم الآلي. لاستخدام Wandb لمراقبة تجارب gpt-neox الخاصة بك:
wandb login - سيتم تسجيل عمليات التشغيل الخاصة بك تلقائيًا../requirements/requirements-wandb.txt . يتوفر مثال للتكوين في ./configs/local_setup_wandb.yml .wandb_group بتسمية مجموعة التشغيل ويتيح لك wandb_team تعيين عمليات التشغيل لحساب مؤسسة أو فريق. يتوفر مثال للتكوين في ./configs/local_setup_wandb.yml . نحن ندعم استخدام TensorBoard عبر حقل tensorboard-dir . يمكن العثور على التبعيات المطلوبة لمراقبة TensorBoard وتثبيتها من ./requirements/requirements-tensorboard.txt .
Comet عبارة عن منصة لمراقبة التعلم الآلي. لاستخدام المذنب لمراقبة تجارب gpt-neox الخاصة بك:
comet login أو تمرير export COMET_API_KEY=<your-key-here>comet_ml وأي مكتبات تبعية عبر pip install -r requirements/requirements-comet.txtuse_comet: True . يمكنك أيضًا تخصيص مكان تسجيل البيانات باستخدام comet_workspace و comet_project . يتوفر مثال كامل للتكوين مع تمكين Comet في configs/local_setup_comet.yml . إذا كنت بحاجة إلى توفير ملف مضيف للاستخدام مع مشغل DeepSpeed المستند إلى MPI، فيمكنك تعيين متغير البيئة DLTS_HOSTFILE للإشارة إلى ملف المضيف.
نحن ندعم إنشاء ملفات التعريف باستخدام أنظمة Nsight، وPyTorch Profiler، وPyTorch Memory Profiling.
لاستخدام ملف تعريف Nsight Systems، قم بتعيين profile خيارات التكوين، profile_step_start ، و profile_step_stop (انظر هنا لاستخدام الوسيطة، وهنا للحصول على نموذج تكوين).
لملء مقاييس nsys، ابدأ التدريب باستخدام:
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py
$TRAIN_PATH/train.py --conf_dir configs <config files>
يمكن بعد ذلك عرض ملف الإخراج الذي تم إنشاؤه باستخدام واجهة المستخدم الرسومية لـ Nsight Systems:
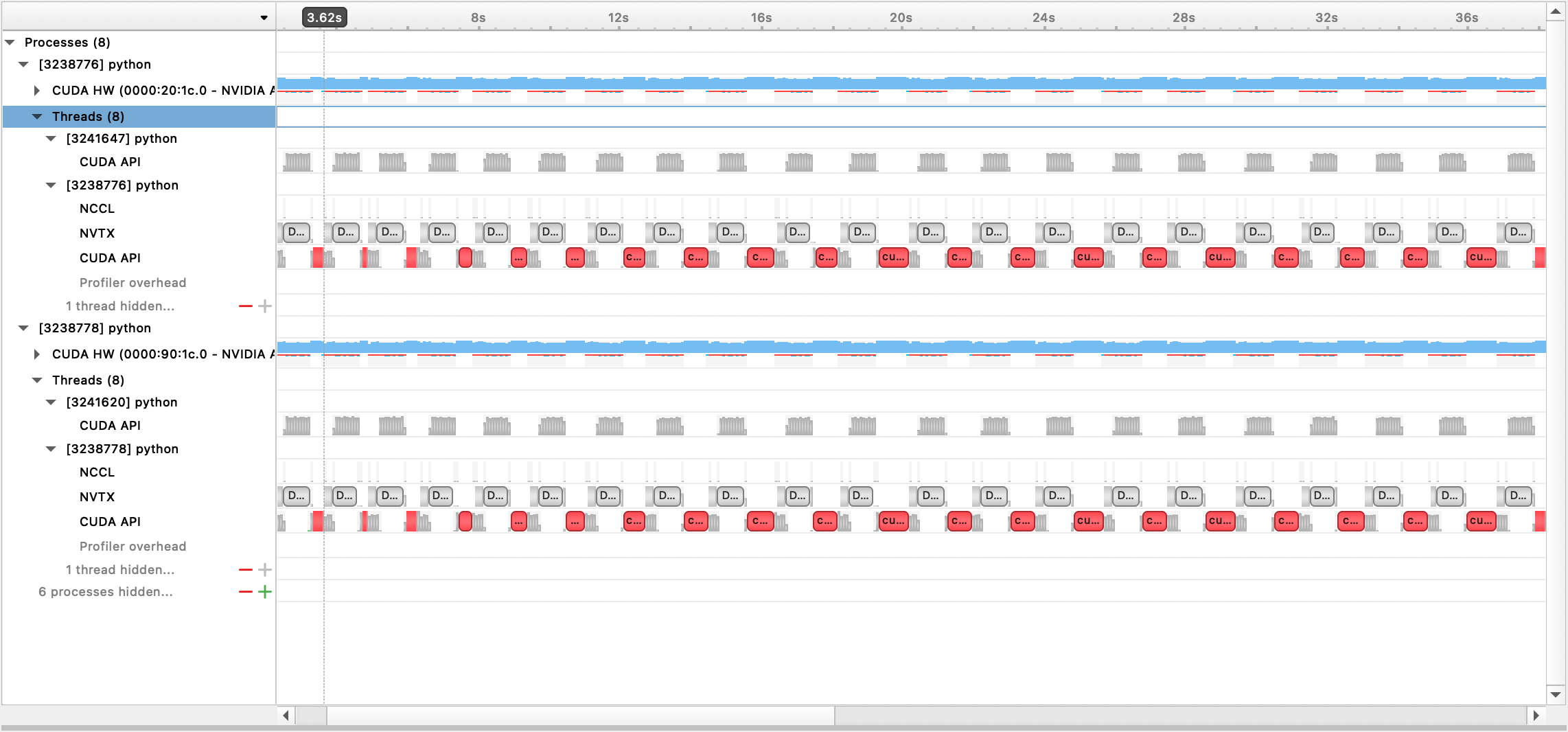
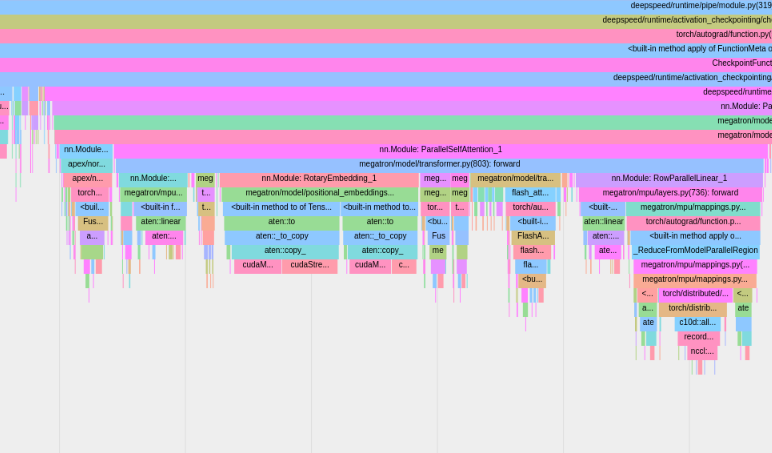
لاستخدام ملف تعريف PyTorch المدمج، قم بتعيين profile خيارات التكوين، profile_step_start ، و profile_step_stop (انظر هنا لاستخدام الوسيطة، وهنا للحصول على نموذج تكوين).
سيقوم ملف تعريف PyTorch بحفظ الآثار في دليل سجل tensorboard الخاص بك. يمكنك عرض هذه الآثار داخل TensorBoard باتباع الخطوات الواردة هنا.
لاستخدام ملف تعريف الذاكرة PyTorch، قم بتعيين خيارات التكوين memory_profiling و memory_profiling_path (انظر هنا لاستخدام الوسيطة، وهنا للحصول على نموذج التكوين).
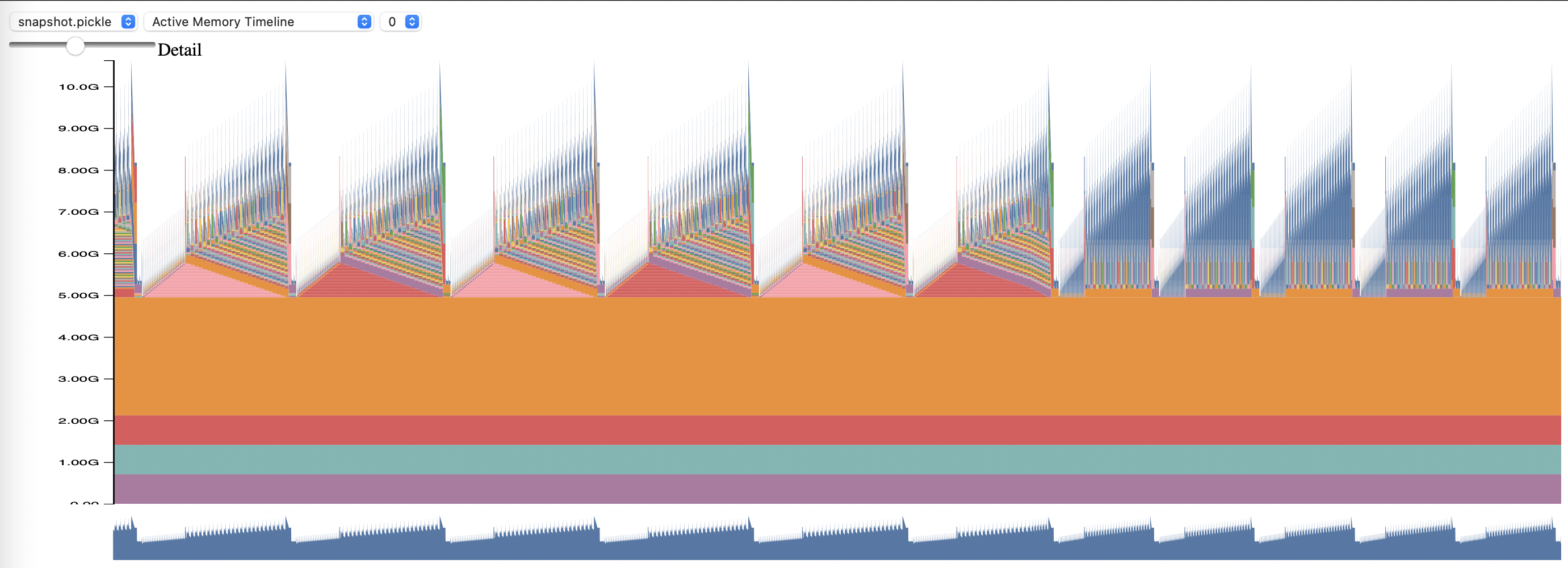
اعرض ملف التعريف الذي تم إنشاؤه باستخدام البرنامج النصي Memory_viz.py. تشغيل مع:
python _memory_viz.py trace_plot <generated_profile> -o trace.html
تم اعتماد مكتبة GPT-NeoX على نطاق واسع من قبل الباحثين الأكاديميين والصناعيين وتم نقلها إلى العديد من أنظمة HPC.
إذا وجدت هذه المكتبة مفيدة في بحثك، فيرجى التواصل معنا وإعلامنا بذلك! نود أن نضيفك إلى قوائمنا.
لقد استخدمها EleutherAI والمتعاونون معنا في المنشورات التالية:
المنشورات التالية الصادرة عن مجموعات بحثية أخرى تستخدم هذه المكتبة:


