visual chatgpt
1.0.0
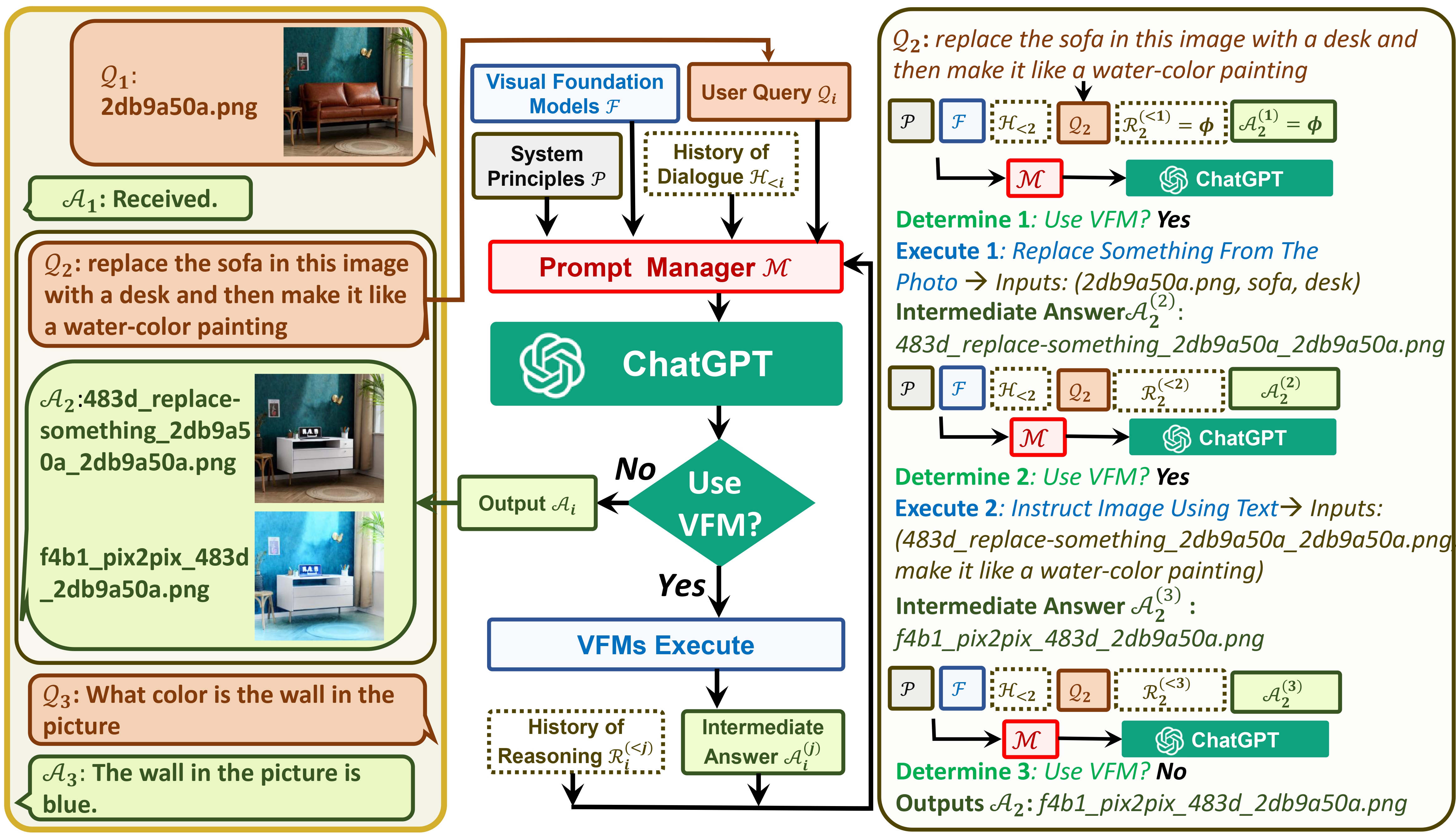
يقوم Visual ChatGPT بتوصيل ChatGPT وسلسلة من نماذج Visual Foundation لتمكين إرسال واستقبال الصور أثناء الدردشة.
راجع مقالتنا: Visual ChatGPT: التحدث والرسم والتحرير باستخدام نماذج الأساس المرئي
من ناحية، يعمل ChatGPT (أو LLMs) كواجهة عامة توفر فهمًا واسعًا ومتنوعًا لمجموعة واسعة من المواضيع. من ناحية أخرى، تعمل مؤسسة Foundation Models كخبراء في المجال من خلال توفير المعرفة العميقة في مجالات محددة. من خلال الاستفادة من المعرفة العامة والعميقة ، نهدف إلى بناء ذكاء اصطناعي قادر على التعامل مع مجموعة متنوعة من المهام.

# clone the repo
git clone https://github.com/microsoft/visual-chatgpt.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start Visual ChatGPT !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are sperated by underline '_', the different models are seperated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,ImageEditing_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
Image2Seg_cpu,SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
ندرج هنا استخدام ذاكرة وحدة معالجة الرسومات لكل نموذج أساسي مرئي، ويمكنك تحديد النموذج الذي تفضله:
| نموذج الأساس | ذاكرة وحدة معالجة الرسومات (ميجابايت) |
|---|---|
| تحرير الصور | 3981 |
| InstructPix2Pix | 2827 |
| Text2Image | 3385 |
| تسمية توضيحية للصورة | 1209 |
| Image2Canny | 0 |
| CannyText2Image | 3531 |
| Image2Line | 0 |
| LineText2Image | 3529 |
| Image2Hed | 0 |
| HedText2Image | 3529 |
| Image2Scribble | 0 |
| ScribbleText2Image | 3531 |
| Image2Pose | 0 |
| PoseText2Image | 3529 |
| Image2Seg | 919 |
| SegText2Image | 3529 |
| Image2Depth | 0 |
| DepthText2Image | 3531 |
| Image2عادي | 0 |
| NormalText2Image | 3529 |
| إجابة الأسئلة المرئية | 1495 |
نحن نقدر المصدر المفتوح للمشاريع التالية:
معانقة الوجه LangChain التحكم في الانتشار المستقرNet InstructPix2Pix CLIPSeg BLIP
للحصول على مساعدة أو مشكلات في استخدام Visual ChatGPT، يرجى إرسال مشكلة GitHub.
بالنسبة إلى الاتصالات الأخرى، يرجى الاتصال بـ Chenfei WU ([email protected]) أو Nan DUAN ([email protected]).


