Awesome Attention Heads
vey on LLM attention heads
مهم
حول هذا الريبو. هذه منصة للحصول على أحدث الأبحاث حول أنواع مختلفة من رؤوس الانتباه في LLM. كما أصدرنا استطلاعًا بناءً على هذه الأعمال الرائعة.
إذا كنت تريد الاستشهاد بعملنا ، فإليك مدخلنا bibtex: CITATION.bib.
إذا كنت تريد فقط رؤية قائمة الأوراق ذات الصلة، فيرجى الانتقال مباشرة إلى هنا.
إذا كنت ترغب في المساهمة في هذا الريبو، راجع هنا.
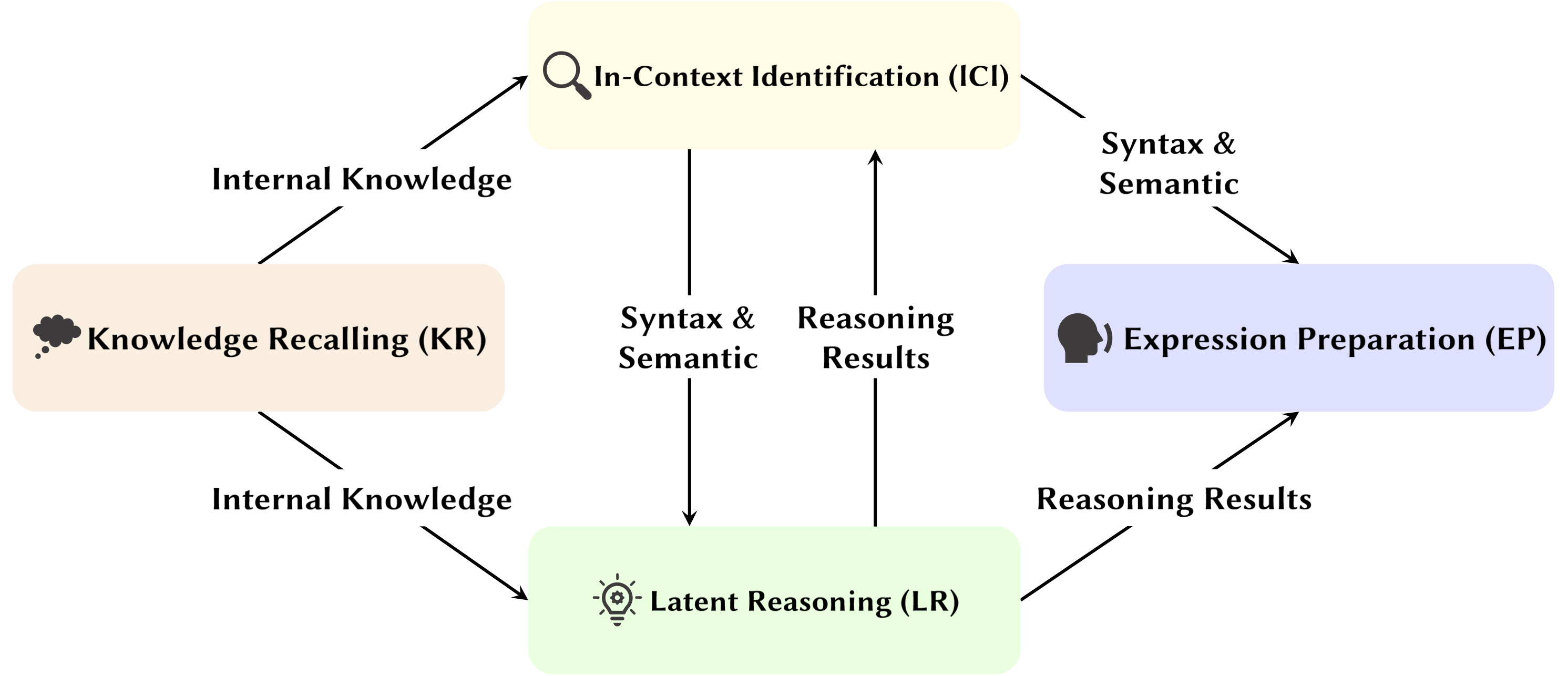
مع تطور نموذج اللغة الكبير (LLMs)، تمت دراسة بنية الشبكة الأساسية الخاصة بهم، المحول، على نطاق واسع. يساعدنا البحث في بنية المحول على تعزيز فهمنا لهذا "الصندوق الأسود" وتحسين إمكانية تفسير النموذج. في الآونة الأخيرة، كانت هناك مجموعة متزايدة من الأعمال التي تشير إلى أن النموذج يحتوي على قسمين متميزين: آليات الانتباه المستخدمة للسلوك والاستدلال والتحليل، وشبكات التغذية الأمامية (FFN) لتخزين المعرفة. يعد الأول أمرًا بالغ الأهمية للكشف عن القدرات الوظيفية للنموذج، مما يؤدي إلى سلسلة من الدراسات التي تستكشف الوظائف المختلفة ضمن آليات الانتباه، والتي أطلقنا عليها اسم "Attention Head Mining" .
في هذا الاستطلاع، نتعمق في الآليات المحتملة لكيفية مساهمة رؤوس الانتباه في LLMs في عملية التفكير.
أبرز النقاط:
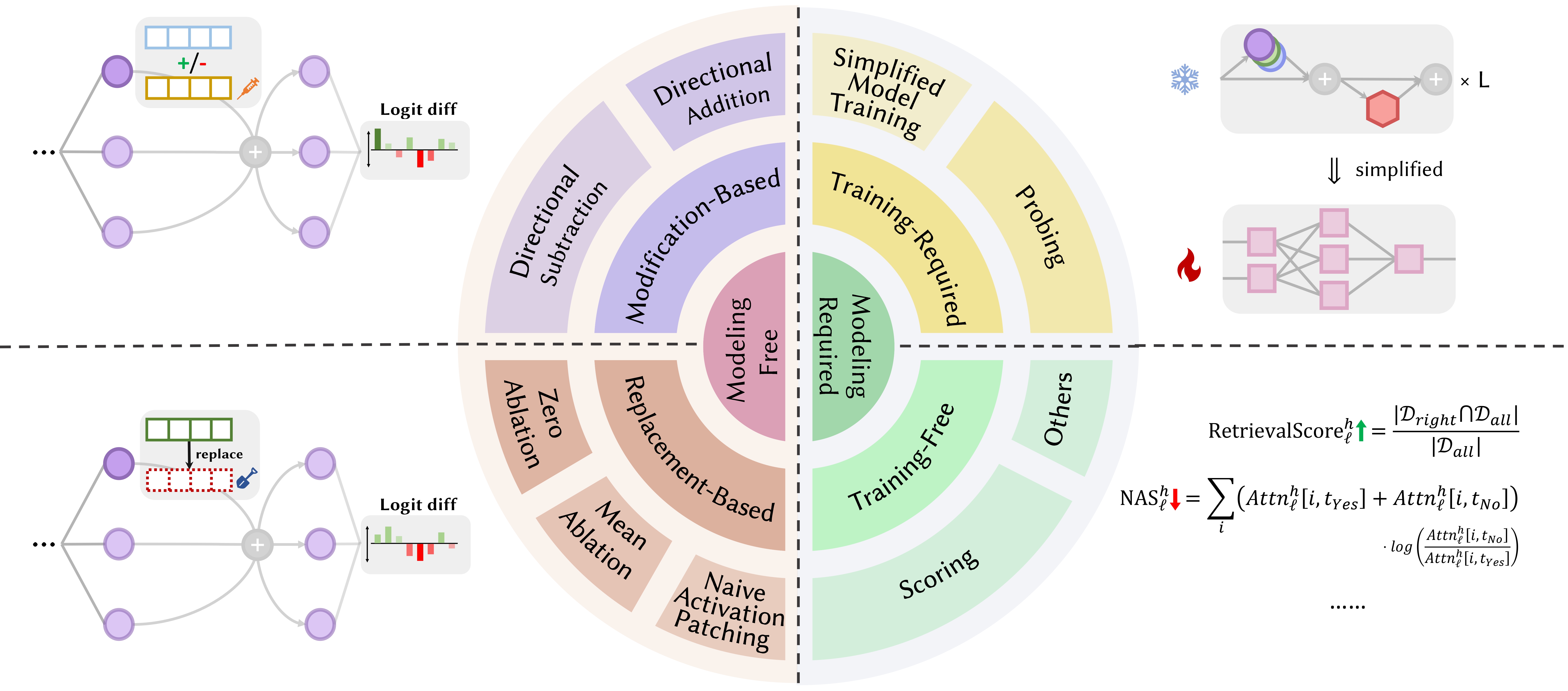
الأوراق أدناه مرتبة حسب تاريخ النشر :
سنة 2024
| تاريخ | ورقة وملخص | العلامات | روابط |
| 2024-11-15 | SEEKR: الاحتفاظ بالمعرفة الانتقائية الموجهة للانتباه من أجل التعلم المستمر لنماذج اللغات الكبيرة | ||
| • يقترح SEEKR، وهي طريقة انتقائية للاحتفاظ بالمعرفة موجهة نحو الاهتمام للتعلم المستمر في LLMs، مع التركيز على رؤوس الاهتمام الرئيسية للتقطير الفعال. • تقييمها على معايير التعلم المستمر TRACE وSuperNI. • حقق SEEKR أداءً مشابهًا أو أفضل بنسبة 1% فقط من بيانات إعادة التشغيل مقارنة بالطرق الأخرى. | |||
| 2024-11-06 | كيف تحل المحولات مشاكل المنطق المقترح: تحليل ميكانيكي | ||
| • يحدد دوائر الاهتمام المحددة في المحولات التي تحل مشاكل المنطق المقترح، مع التركيز على آليات "التخطيط" و"الاستدلال". • تحليل المحولات الصغيرة وMistral-7B، باستخدام تصحيح التنشيط للكشف عن مسارات التفكير. • العثور على رؤوس اهتمام متميزة متخصصة في تحديد موقع القواعد، ومعالجة الحقائق، واتخاذ القرار في الاستدلال المنطقي. | |||
| 2024-11-01 | تعقب الانتباه: الكشف عن هجمات الحقن الفورية في LLMs | ||
| • مُتعقب الانتباه المقترح، وهو عبارة عن حارس بسيط ولكنه فعال بدون تدريب ويكتشف هجمات الحقن السريعة بناءً على الرؤوس المهمة المحددة. • تحديد الرؤساء المهمين باستخدام مجرد مجموعة صغيرة من الجمل العشوائية التي تم إنشاؤها بواسطة LLM بالإضافة إلى هجوم التجاهل الساذج. • يعتبر Attention Tracker فعالاً على كل من LMs الصغيرة والكبيرة، مما يعالج القيود الكبيرة التي كانت موجودة في طرق الكشف السابقة الخالية من التدريب. | |||
| 2024-10-28 | الحساب بدون خوارزميات: نماذج اللغة تحل الرياضيات باستخدام حقيبة من الاستدلالات | ||
| • التعرف على مجموعة فرعية من النموذج (الدائرة) التي تشرح معظم سلوك النموذج للمنطق الحسابي الأساسي وفحص وظائفه. • تحليل أنماط الانتباه باستخدام المطالبات الحسابية ذات المعاملين مع الأرقام العربية والعوامل الأساسية الأربعة (+، −، ×، ÷). • بالنسبة للجمع والطرح والقسمة، فإن 6 رؤوس انتباه تعطي دقة عالية (97% في المتوسط)، في حين أن الضرب يتطلب 20 رأسًا لتتجاوز دقة 90%. | |||
| 2024-10-21 | تقييم لغوي نفسي لحساسية النماذج اللغوية لأدوار الحجة | ||
| • تمت ملاحظة رأس الموضوع في بيئة أكثر عمومية. • تحليل أنماط الاهتمام في ظل حالة وسيطة المبادلة واستبدال الوسيطة. • على الرغم من القدرة على التمييز بين الأدوار، قد تواجه النماذج صعوبة في استخدام معلومات دور الوسيطة بشكل صحيح، حيث تكمن المشكلة في كيفية ترميز هذه المعلومات في تمثيلات فعلية، مما يؤدي إلى ضعف حساسية الدور. | |||
| 2024-10-17 | رؤوس الانتباه النشطة الخاملة: إزالة الغموض عن الظواهر الرمزية المتطرفة في ماجستير إدارة الأعمال (LLM) ميكانيكيًا | ||
| • أثبت أن الظواهر المميزة للغاية تنشأ من آلية نشطة خاملة في رؤوس الانتباه، مقترنة بآلية التعزيز المتبادل أثناء التدريب المسبق. • استخدام محولات بسيطة تم تدريبها على مهمة Biggram-Backcopy (BB) لتحليل ظواهر الرموز المميزة وتوسيع نطاقها لتشمل حاملي شهادات الماجستير المدربين مسبقًا. • العديد من الخصائص الثابتة والديناميكية للظواهر المميزة للغاية التي تنبأت بها مهمة BB تتماشى مع الملاحظات في LLMs المدربة مسبقًا. | |||
| 2024-10-17 | حول دور رؤوس الانتباه في سلامة النماذج اللغوية الكبيرة | ||
| • اقترح مقياسًا جديدًا تم تصميمه خصيصًا لاهتمام العديد من الرؤساء، وهو درجة أهمية رأس السلامة (السفن)، لتقييم مساهمات الرؤساء الفرديين في سلامة النماذج. • إجراء تحليلات حول وظائف هذه الرؤوس المعنية بالسلامة، واستكشاف خصائصها وآلياتها. • تعتبر بعض رؤوس الانتباه ضرورية للسلامة، حيث تتداخل رؤوس الأمان عبر النماذج المضبوطة بدقة، كما أن إزالة هذه الرؤوس يؤثر إلى الحد الأدنى على المساعدة. | |||
| 2024-10-14 | DuoAttention: استنتاج LLM فعال وطويل السياق مع رؤوس الاسترجاع والتدفق | ||
| • تقديم DuoAttention، وهو إطار عمل يقلل من فك تشفير LLM وملء الذاكرة مسبقًا وزمن الوصول دون المساس بقدراته على السياق الطويل، استنادًا إلى اكتشاف رؤوس الاسترجاع ورؤوس التدفق داخل LLM. • اختبار تأثير الإطار على أداء LLM في كل من المهام ذات السياق القصير والسياق الطويل، بالإضافة إلى كفاءة الاستدلال. • من خلال تطبيق ذاكرة تخزين مؤقت KV كاملة على رؤوس الاسترجاع فقط، يقلل DuoAttention بشكل كبير من استخدام الذاكرة وزمن الوصول لكل من فك التشفير والتعبئة المسبقة لتطبيقات السياق الطويل. | |||
| 2024-10-14 | تأمين سلامة LLMs Finetuned | ||
| • تقديم SafetyLock، وهي طريقة جديدة وفعالة للحفاظ على سلامة نماذج اللغات الكبيرة المضبوطة بدقة عبر مختلف مستويات المخاطر وسيناريوهات الهجوم، استنادًا إلى اكتشاف رؤوس السلامة داخل LLM. • تقييم فعالية SafetyLock في تعزيز سلامة النموذج وكفاءة الاستدلال. • من خلال تطبيق متجهات التدخل على رؤوس الأمان، يمكن لـ SafetyLock تعديل عمليات التنشيط الداخلية للنموذج نحو عدم الإيذاء أثناء الاستدلال، مما يحقق توافقًا دقيقًا للسلامة مع الحد الأدنى من التأثير على الاستجابة. | |||
| 2024-10-11 | نفس الشيء ولكن مختلف: أوجه التشابه والاختلاف الهيكلية في نمذجة اللغات متعددة اللغات | ||
| • إجراء دراسة متعمقة للمكونات المحددة التي تعتمد عليها النماذج متعددة اللغات عند أداء المهام التي تتطلب عمليات مورفولوجية خاصة باللغة. • التحقيق في الاختلافات الوظيفية لمكونات النموذج الداخلي عند أداء المهام باللغتين الإنجليزية والصينية. • رأس النسخ له تردد تنشيط مرتفع مماثل في كلتا اللغتين بينما يتم تنشيط رأس الفعل الماضي بشكل متكرر فقط باللغة الإنجليزية. | |||
| 2024-10-08 | جولة وجولة نذهب! ما الذي يجعل الترميزات الموضعية الدوارة مفيدة؟ | ||
| • تقديم تحليل متعمق للأجزاء الداخلية لنموذج Gemma 7B المدرب لفهم كيفية استخدام RoPE على المستوى الميكانيكي. • فهم استخدام الترددات المختلفة في الاستعلامات والمفاتيح. • وجد أن الترددات الأعلى في RoPE تستخدم بذكاء بواسطة Gemma 7B لبناء رؤوس انتباه "موضعية" خاصة (رؤوس قطرية، رأس رمزي سابق)، بينما يتم استخدام الترددات المنخفضة بواسطة رأس الفاصلة العليا. | |||
| 2024-10-06 | إعادة النظر في دائرة استدلال التعلم في السياق في نماذج اللغات الكبيرة | ||
| • تم اقتراح دائرة استدلال شاملة مكونة من 3 خطوات لوصف عملية الاستدلال لـ ICL. • تقسيم ICL إلى ثلاث مراحل: التلخيص، ودمج الدلالات، واسترجاع الميزات ونسخها، وتحليل الدور الذي تلعبه كل مرحلة في ICL وآليتها التشغيلية. • وجدت أنه قبل الرؤوس التعريفية، يقوم Forerunner Token Heads أولاً بدمج تمثيلات نص العرض التوضيحي من الرمز المميز للمنتج السابق في رموز التسمية المقابلة لها، بشكل انتقائي استنادًا إلى التوافق بين دلالات العرض التوضيحي والتسمية. | |||
| 2024-10-01 | تطبيق تحليل الانتباه المتناثر على تتبع الدوائر | ||
| • يقدم تحليل الانتباه المتفرق، باستخدام SVD على مصفوفات رأس الانتباه لتتبع مسارات الاتصال في نماذج GPT-2. • يتم تطبيقه على تتبع الدوائر في GPT-2 الصغيرة لمهمة التعرف على الكائنات غير المباشرة (IOI). • تحديد إشارات اتصال متفرقة وذات أهمية وظيفية بين رؤوس الانتباه، مما يحسن إمكانية التفسير. | |||
| 2024-09-09 | الكشف عن الرؤوس التعريفية: ديناميكيات التدريب التي يمكن إثباتها وتعلم الميزات في المحولات | ||
| • تقدم هذه الورقة آلية رأس الحث المعممة، موضحة كيفية تعاون مكونات المحولات لأداء التعلم في السياق (ICL) على سلاسل ماركوف n-gram. • يقوم بتحليل محول ثنائي الطبقة مع تدفق متدرج للتنبؤ بالرموز المميزة في سلاسل ماركوف. • يتقارب التدفق المتدرج، مما يتيح ICL من خلال آلية الرأس التعريفي المستندة إلى الميزات المكتسبة. | |||
| 2024-08-16 | تفسير ميكانيكي للاستدلال القياسى في نماذج اللغة التراجعية التلقائية | ||
| • تقدم الدراسة تفسيرًا ميكانيكيًا للاستدلال القياسي في LMs، وتحديد دوائر الاستدلال المستقلة عن المحتوى. • اكتشاف الدوائر للاستدلال والتحقيق في تلوث التحيز الاعتقادي في رؤوس الانتباه. • تحديد دائرة تفكير ضرورية قابلة للتحويل عبر المخططات القياسيّة، ولكنها عرضة للتلوث من خلال المعرفة العالمية المدربة مسبقًا. | |||
| 2024-08-01 | تعزيز الاتساق الدلالي لنماذج اللغات الكبيرة من خلال تحرير النماذج: نهج موجه نحو التفسير | ||
| • يقدم أسلوب تحرير نموذجي فعال من حيث التكلفة يركز على رؤوس الاهتمام لتعزيز الاتساق الدلالي في LLMs دون تغييرات واسعة النطاق في المعلمات. • تحليل رؤوس الاهتمام، والتحيزات المحقونة، واختبارها على مجموعات بيانات NLU وNLG. • تحقيق تحسينات ملحوظة في الاتساق الدلالي وأداء المهام، مع تعميم قوي عبر مهام إضافية. | |||
| 2024-07-31 | تصحيح التحيز السلبي في نماذج اللغة الكبيرة من خلال محاذاة درجات الانتباه السلبي | ||
| • تقديم نقاط الانتباه السلبي (NAS) لقياس التحيز السلبي وتصحيحه في نماذج اللغة. • تحديد رؤوس الاهتمام المتحيزة سلبًا واقتراح محاذاة نقاط الانتباه السلبية (NASA) من أجل الضبط الدقيق. • قامت وكالة ناسا بتقليص فجوة الدقة في الاستدعاء بشكل فعال مع الحفاظ على التعميم في مهام اتخاذ القرار الثنائية. | |||
| 2024-07-29 | اكتشاف وفهم نقاط الضعف في نماذج اللغة من خلال إمكانية التفسير الآلي | ||
| • يقدم طريقة تستخدم التفسير الميكانيكي (MI) لاكتشاف وفهم نقاط الضعف في LLMs، وخاصة هجمات الخصومة. • تحليل GPT-2 Small بحثًا عن نقاط الضعف في التنبؤ بالمختصرات المكونة من 3 أحرف. • تحديد وشرح نقاط الضعف المحددة في النموذج المتعلق بالمهمة بنجاح. | |||
| 2024-07-22 | انتبه: ضغط ذاكرة التخزين المؤقت KV الفعال من خلال رؤوس الاسترجاع | ||
| • تقديم RazorAttention، وهي تقنية ضغط ذاكرة تخزين مؤقت KV بدون تدريب باستخدام رؤوس الاسترجاع ورموز التعويض للحفاظ على معلومات الرموز المميزة. • تقييم RazorAttention على نماذج اللغات الكبيرة (LLMs) لتحقيق الكفاءة. • تم تقليل حجم ذاكرة التخزين المؤقت بنسبة تزيد عن 70% دون أي تأثير ملحوظ على الأداء. | |||
| 2024-07-21 | الإجابة، التجميع، الآس: فهم كيفية إجابة المحولات على أسئلة الاختيار من متعدد | ||
| • تقدم الورقة إسقاط المفردات وتصحيح التنشيط لتحديد الحالات المخفية التي تتنبأ بإجابات MCQA الصحيحة. • تحديد رؤساء الاهتمام الرئيسي والطبقات المسؤولة عن اختيار الإجابة في المحولات. • تعتبر رؤوس الانتباه ذات الطبقة الوسطى ضرورية للتنبؤ الدقيق بالإجابات، حيث تلعب مجموعة متفرقة من الرؤوس أدوارًا فريدة. | |||
| 2024-07-09 | الرؤوس التعريفية كآلية أساسية لمطابقة الأنماط في التعلم داخل السياق | ||
| • تحدد المقالة الرؤوس التعريفية باعتبارها ضرورية لمطابقة الأنماط في التعلم داخل السياق (ICL). • تقييم Llama-3-8B وInternLM2-20B فيما يتعلق بالتعرف على الأنماط المجردة ومهام البرمجة اللغوية العصبية. • يؤدي استئصال الرؤوس الحثية إلى تقليل أداء ICL بنسبة تصل إلى 32% تقريبًا، مما يجعله أقرب إلى العشوائية للتعرف على الأنماط. | |||
| 2024-07-02 | تفسير الآلية الحسابية في النماذج اللغوية الكبيرة من خلال تحليل الخلايا العصبية المقارن | ||
| • يقدم تحليل الخلايا العصبية المقارن (CNA) لرسم خريطة للآليات الحسابية في رؤوس الانتباه لنماذج اللغة الكبيرة. • تحليل القدرة الحسابية، وتشذيب النماذج للمهام الحسابية، وتحرير النماذج للحد من التحيز بين الجنسين. • تحديد الخلايا العصبية المحددة المسؤولة عن العمليات الحسابية، مما يتيح تحسين الأداء وتخفيف التحيز من خلال التلاعب بالخلايا العصبية المستهدفة. | |||
| 2024-07-01 | توجيه نماذج اللغات الكبيرة لاسترجاع المعلومات عبر اللغات | ||
| • يقدم التنشيط الموجه متعدد اللغات (ASMR)، وذلك باستخدام تنشيط التوجيه لتوجيه ماجستير إدارة الأعمال لتحسين استرجاع المعلومات عبر اللغات. • تحديد رؤساء الاهتمام في LLMs التي تؤثر على الدقة وتماسك اللغة، وتنشيط التوجيه التطبيقي. • حقق ASMR أداءً متطورًا وفقًا لمعايير CLIR مثل XOR-TyDi QA وMKQA. | |||
| 2024-06-25 | كيف تتعلم المحولات البنية السببية من خلال النسب المتدرج | ||
| • تقديم شرح لكيفية تعلم المحولات للهياكل السببية من خلال خوارزميات التدريب القائمة على التدرج. • تحليل أداء المحولات ذات الطبقتين في مهمة تسمى التسلسلات العشوائية ذات البنية السببية. • نزول التدرج على محول مبسط من طبقتين يتعلم حل هذه المهمة عن طريق ترميز الرسم البياني السببي الكامن في طبقة الانتباه الأولى. في حالة خاصة، عندما يتم إنشاء تسلسلات من سلاسل ماركوف في السياق، تتعلم المحولات تطوير رأس تحريضي. | |||
| 2024-06-21 | MoA: مزيج من الاهتمام المتناثر للضغط التلقائي لنموذج اللغة الكبير | ||
| • يقدم البحث مزيجًا من الاهتمام (MoA)، الذي يصمم تكوينات انتباه متفرقة متميزة لرؤوس وطبقات مختلفة، مما يؤدي إلى تحسين الذاكرة والإنتاجية ومقايضات الدقة وزمن الوصول. • نماذج ملفات تعريف وزارة الزراعة، واستكشاف تكوينات الاهتمام، وتحسين ضغط LLM. • تعمل MoA على زيادة طول السياق الفعال بمقدار 3.9×، مع تقليل استخدام ذاكرة وحدة معالجة الرسومات بمقدار 1.2-1.4×. | |||
| 2024-06-19 | حول صعوبة التفكير المنطقي لسلسلة الأفكار في النماذج اللغوية الكبيرة | ||
| • تقديم إستراتيجيات جديدة للتعلم في السياق، والضبط الدقيق، وتحرير التنشيط لتحسين الإخلاص المنطقي لتسلسل الأفكار (CoT) في ماجستير إدارة الأعمال. • اختبار هذه الاستراتيجيات عبر معايير متعددة لتقييم فعاليتها. • لم يتم العثور إلا على نجاح محدود في تعزيز الإخلاص في CoT، مما يسلط الضوء على التحدي المتمثل في تحقيق الاستدلال الأمين حقًا في ماجستير إدارة الأعمال. | |||
| 2024-06-04 | رأس التكرار: دراسة آلية لسلسلة الفكر | ||
| • يقدم "رؤوس التكرار"، وهي رؤوس اهتمام متخصصة تمكن من التفكير التكراري في المحولات الخاصة بمهام سلسلة الفكر (CoT). • تحليل آليات الاهتمام، وتتبع ظهور CoT، واختبار قابلية نقل مهارات CoT بين المهام. • تدعم رؤوس التكرار بشكل فعال استدلال CoT، مما يعمل على تحسين إمكانية تفسير النموذج وأداء المهام. | |||
| 2024-06-03 | LoFiT: الضبط الدقيق المحلي لتمثيلات LLM | ||
| • يقدم الضبط الدقيق لتمثيلات LLM (LoFiT)، وهو إطار عمل مكون من خطوتين لتحديد رؤوس الاهتمام المهمة لمهمة معينة وتعلم متجهات الإزاحة الخاصة بالمهمة للتدخل في تمثيلات الرؤوس المحددة. • تحديد مجموعات متفرقة من رؤوس الاهتمام المهمة لتحسين الدقة النهائية فيما يتعلق بالصدق والاستدلال. • تفوقت LoFiT على أساليب التدخل التمثيلية الأخرى وحققت أداءً مشابهًا لأساليب PEFT في TruthfulQA وCLUTRR وMQuAKE، على الرغم من تدخلها في 10% فقط من إجمالي رؤوس الاهتمام في LLMs. | |||
| 2024-05-28 | دوائر المعرفة في المحولات المدربة مسبقا | ||
| • تقديم "دوائر المعرفة" في المحولات، مما يكشف عن كيفية تشفير المعرفة المحددة من خلال التفاعل بين رؤوس الانتباه، ورؤساء العلاقات، وMLPs. • تحليل GPT-2 وTinyLLAMA لتحديد دوائر المعرفة. تقييم تقنيات تحرير المعرفة. • أوضح كيف تساهم دوائر المعرفة في السلوكيات النموذجية مثل الهلوسة والتعلم في السياق. | |||
| 2024-05-23 | ربط التعلم في السياق في المحولات بالذاكرة العرضية البشرية | ||
| • ربط التعلم في السياق في نماذج المحولات بالذاكرة العرضية البشرية، وتسليط الضوء على أوجه التشابه بين الرؤوس التعريفية ونموذج الصيانة والاسترجاع السياقي (CMR). • تحليل LLMs القائم على المحولات لإثبات السلوك المشابه لـ CMR في رؤوس الانتباه. • تظهر الرؤوس الشبيهة بـ CMR في طبقات متوسطة، مما يعكس تحيزات الذاكرة البشرية. | |||
| 2024-05-07 | كيف يتنبأ GPT-2 بالمختصرات؟ استخراج وفهم الدائرة عبر التفسير الميكانيكي | ||
| • أول دراسة تفسيرية آلية على GPT-2 للتنبؤ بالمختصرات متعددة الرموز باستخدام رؤوس الانتباه. • تحديد وتفسير دائرة مكونة من 8 رؤوس انتباه مسؤولة عن التنبؤ بالاختصارات. • أثبت أن هذه الرؤوس الثمانية (حوالي 5% من الإجمالي) تركز على وظيفة التنبؤ بالاختصارات. | |||
| 2024-05-02 | تفسير وتحسين نماذج اللغة الكبيرة في الحساب الحسابي | ||
| • يقدم تحقيقًا تفصيليًا للآليات الداخلية لـ LLMs من خلال المهام الرياضية، بعد خط أنابيب "التحديد والتحليل والدقة". • تحليل قدرة النموذج على أداء المهام الحسابية التي تنطوي على معاملين، مثل الجمع والطرح والضرب والقسمة. • وجدت أن LLMs تتضمن في كثير من الأحيان جزءًا صغيرًا (<5%) من رؤوس الانتباه، والتي تلعب دورًا محوريًا في التركيز على المعاملات والعوامل أثناء عمليات الحساب. | |||
| 2024-05-02 | ما الذي يجب أن يسير بشكل صحيح للحصول على رأس تحريضي؟ دراسة آلية لدوائر التعلم في السياق وتكوينها | ||
| • تقديم إطار سببي مستوحى من علم البصريات الوراثي لدراسة تكوين الرأس التحريضي (IH) في المحولات. • تحليل ظهور IH في المحولات باستخدام البيانات الاصطناعية وتحديد ثلاث دوائر فرعية أساسية مسؤولة عن تكوين IH. • اكتشف أن هذه الدوائر الفرعية تتفاعل لتحفيز تكوين IH، بالتزامن مع تغير الطور في فقدان النموذج. | |||
| 2024-04-24 | رأس الاسترجاع يشرح ميكانيكيًا حقيقة السياق الطويل | ||
| • تحديد "رؤوس الاسترجاع" في نماذج المحولات المسؤولة عن استرجاع المعلومات عبر سياقات طويلة. • التحقيق المنهجي لرؤساء الاسترجاع عبر نماذج مختلفة، بما في ذلك تحليل دورهم في التفكير المنطقي التسلسلي. • تقليم الرؤوس الاسترجاعية يؤدي إلى الهلوسة، أما تقليم الرؤوس غير الاسترجاعية فلا يؤثر على القدرة على الاسترجاع. | |||
| 2024-03-27 | التدخل الزمني للاستدلال غير الخطي: تحسين صدق LLM | ||
| • تقديم التدخل الزمني للاستدلال غير الخطي (NL-ITI)، مما يعزز مصداقية LLM من خلال التحقيق والتدخل متعدد الرموز بدون ضبط دقيق. • تقييم NL-ITI على مجموعات بيانات متعددة الاختيارات، بما في ذلك TruthfulQA. • تم تحقيق تحسن نسبي بنسبة 16% في دقة MC1 في TruthfulQA مقارنة بـ ITI الأساسي. | |||
| 2024-02-28 | كيف تفكر خطوة بخطوة: الفهم الآلي لسلسلة التفكير | ||
| • تقديم تحليل متعمق للاستدلال بوساطة CoT في LLMs من حيث المكونات الوظيفية العصبية. • تشريح المنطق القائم على CoT على التفكير الخيالي كتركيبة لعدد ثابت من المهام الفرعية التي تتطلب اتخاذ القرار، والنسخ، والتفكير الاستقرائي، وتحليل آليتها بشكل منفصل. • وجد أن رؤوس الانتباه تؤدي حركة المعلومات بين الرموز المميزة المرتبطة وجوديًا (أو ذات الصلة سلبًا)، مما يؤدي إلى تمثيلات يمكن التعرف عليها بوضوح لهذه الأزواج المميزة. | |||
| 2024-02-28 | قطع الرأس ينهي الصراع: آلية لتفسير وتخفيف الصراعات المعرفية في النماذج اللغوية | ||
| • يقدم طريقة PH3 لتهذيب رؤوس الانتباه المتضاربة، وتخفيف تضارب المعرفة في نماذج اللغة دون تحديثات المعلمات. • تطبيق PH3 للتحكم في اعتماد LMs على الذاكرة الداخلية مقابل السياق الخارجي واختبار فعاليته في مهام ضمان الجودة ذات المجال المفتوح. • قام PH3 بتحسين استخدام الذاكرة الداخلية بنسبة 44.0% واستخدام السياق الخارجي بنسبة 38.5%. | |||
| 2024-02-27 | مسارات تدفق المعلومات: تفسير نماذج اللغة تلقائيًا على نطاق واسع | ||
| • يقدم "مسارات تدفق المعلومات" باستخدام الإسناد للتفسير القائم على الرسم البياني لنماذج اللغة، وتجنب تصحيح التنشيط. • تجارب مع اللاما 2، لتحديد رؤوس الاهتمام الرئيسية وأنماط السلوك عبر المجالات والمهام المختلفة. • الكشف عن مكونات النموذج المتخصصة. تحديد الأدوار المتسقة لرؤوس الانتباه، مثل التعامل مع الرموز المميزة لنفس الجزء من الكلام. | |||
| 2024-02-20 | تحديد رؤوس الاستقراء الدلالي لفهم التعلم في السياق | ||
| • يحدد ويدرس "رؤساء التعريفي الدلالي" في نماذج اللغة الكبيرة (LLMs) التي ترتبط بقدرات التعلم في السياق. • تحليل رؤوس الاهتمام لترميز التبعيات النحوية وعلاقات الرسم البياني المعرفي. • تعمل بعض رؤوس الاهتمام على تعزيز لوجستيات المخرجات من خلال استدعاء الرموز المميزة ذات الصلة، وهو أمر بالغ الأهمية لفهم التعلم في السياق في LLMs. | |||
| 2024-02-16 | تطور رؤوس الاستقراء الإحصائي: سلاسل ماركوف للتعلم في السياق | ||
| • يقدم مهمة نمذجة تسلسل سلسلة ماركوف لتحليل كيفية ظهور قدرات التعلم في السياق (ICL) في المحولات، وتشكيل "رؤوس الحث الإحصائي". • التحقيق العملي والنظري للتدريب متعدد المراحل في المحولات على مهام سلسلة ماركوف. • يوضح التحولات الطورية من تنبؤات unigram إلى bigram، متأثرة بتفاعلات طبقة المحولات. | |||
| 2024-02-11 | تلخيص الحقائق: الآليات الإضافية وراء استرجاع الحقائق في ماجستير إدارة الأعمال | ||
| • يحدد ويشرح "الحافز الإضافي" في استدعاء الحقائق، حيث يستخدم LLM آليات مستقلة متعددة تتدخل بشكل بناء في تذكر الحقائق. • توسيع الإسناد المنطقي المباشر لتحليل رؤوس الانتباه وتفكيك سلوك الرؤوس المختلطة. • أثبت أن الاستدعاء الفعلي في LLMs ينتج عن مجموع المساهمات المتعددة وغير الكافية بشكل مستقل. | |||
| 2024-02-05 | كيف تتعلم نماذج اللغات الكبيرة في السياق؟ الاستعلام والمصفوفات الرئيسية للرؤوس في السياق هما برجان للتعلم المتري | ||
| • يقدم مفهوم أن الاستعلام والمصفوفات الرئيسية في الرؤوس الموجودة في السياق تعمل بمثابة "برجين" للتعلم المتري، مما يسهل حساب التشابه بين ميزات التسمية. • تحليل آليات التعلم في السياق. حددت رؤساء اهتمام محددين حاسمين لـ ICL. • تم تقليل دقة ICL من 87.6% إلى 24.4% عن طريق التدخل في 1% فقط من هذه الرؤوس. | |||
| 2024-01-23 | تعلم اللغة في السياق: البنى والخوارزميات | ||
| • تقديم "رؤوس n-gram"، وهي رؤوس انتباه محولة متخصصة، مما يعزز تعلم اللغة في السياق (ICLL) من خلال التنبؤ الرمزي المشروط بالمدخلات. • تقييم النماذج العصبية على اللغات العادية من أتمتة عشوائية محدودة. • أدت رؤوس n-gram ذات الأسلاك الصلبة إلى تحسين مستوى الحيرة بنسبة 6.7% في مجموعة بيانات SlimPajama. | |||
| 2024-01-16 | الأساس الآلي للاعتماد على البيانات والتعلم المفاجئ في مهمة التصنيف في السياق | ||
| • تمثل هذه الورقة الأساس الآلي للتعلم في السياق (ICL) من خلال التشكيل المفاجئ للرؤوس التعريفية في شبكات الاهتمام فقط. • محاكاة مهام ICL باستخدام بيانات الإدخال المبسطة وشبكة تعتمد على الاهتمام من طبقتين. • يؤدي تكوين الرأس التعريفي إلى الانتقال المفاجئ إلى ICL، والذي يتم تتبعه من خلال اللاخطيات المتداخلة. | |||
| 2024-01-16 | إعادة استخدام مكونات الدائرة عبر المهام في نماذج لغة المحولات | ||
| • يوضح البحث أن دوائر محددة في GPT-2 يمكن تعميمها عبر مهام مختلفة، مما يتحدى فكرة أن هذه الدوائر مخصصة لمهمة محددة. • يفحص إعادة استخدام الدوائر من مهمة التعرف على الكائنات غير المباشرة (IOI) في مهمة الكائنات الملونة. • يؤدي ضبط رؤوس الانتباه الأربعة إلى زيادة الدقة من 49.6% إلى 93.7% في مهمة الكائنات الملونة. | |||
| 2024-01-16 | الرؤوس اللاحقة: رؤوس الاهتمام المتكررة والقابلة للتفسير في البرية | ||
| • تقدم الورقة "الرؤوس اللاحقة"، وهي رؤوس الانتباه في LLMs التي تزيد من الرموز المميزة حسب الترتيب الطبيعي، مثل الأيام أو الأرقام. • يقوم بتحليل تكوين الرؤوس اللاحقة عبر مختلف أحجام النماذج والبنيات، مثل GPT-2 وLlama-2. • تم العثور على الرؤوس اللاحقة في نماذج تتراوح من 31M إلى 12B من المعلمات، مما يكشف عن تمثيلات رقمية مجردة ومتكررة. | |||
| 2024-01-16 | المتجهات الوظيفية في نماذج اللغات الكبيرة | ||
| • يقدم المقال "متجهات الوظائف (FVs)،" تمثيلات سببية مدمجة للمهام ضمن نماذج محولات الانحدار الذاتي. • تم اختبار FVs عبر مهام ونماذج وطبقات التعلم في السياق (ICL). • يمكن تلخيص FVs لإنشاء ناقلات تؤدي إلى مهام جديدة ومعقدة، مما يدل على تكوين المتجهات الداخلية. | |||
| تاريخ | ورقة وملخص | العلامات | روابط |
| 2023-12-23 | تقصي الحقائق: محاولة إجراء هندسة عكسية لاسترجاع الحقائق على مستوى الخلايا العصبية | ||
| • التحقيق في كيفية تشفير طبقات MLP المبكرة في Pythia 2.8B للاسترجاع الفعلي باستخدام الدوائر الموزعة، مع التركيز على التراكب والتضمينات متعددة الرموز. • استكشاف البحث الواقعي في طبقات MLP، واختبار الفرضيات حول آليات إزالة الرموز والتجزئة. • وظائف استدعاء الحقائق مثل جدول البحث الموزع بدون آليات داخلية يمكن تفسيرها بسهولة. | |||
| 2023-11-07 | نحو استمرار التسلسل القابل للتفسير: تحليل الدوائر المشتركة في نماذج اللغات الكبيرة | ||
| • إثبات وجود دوائر مشتركة لمهام استمرار التسلسل المماثلة. • تحليل ومقارنة الدوائر لمهام استمرار التسلسل المماثلة، والتي تشمل زيادة تسلسل الأرقام العربية، وكلمات الأرقام، والأشهر. • تعتمد التسلسلات ذات الصلة الدلالية على الرسوم البيانية الفرعية للدوائر المشتركة ذات الأدوار المماثلة وإيجاد دوائر فرعية مماثلة عبر النماذج ذات الوظائف المماثلة. | |||
| 2023-10-23 | التمثيل الخطي للمشاعر في نماذج اللغة الكبيرة | ||
| • تحدد الورقة الاتجاه الخطي في مساحة التنشيط الذي يلتقط تمثيل المشاعر في نماذج اللغات الكبيرة (LLMs). • قاموا بعزل اتجاه المشاعر هذا واختباره في مهام من بينها Stanford Sentiment Treebank. • يؤدي تقليص هذا الاتجاه إلى انخفاض دقة التصنيف بنسبة 76%، مما يسلط الضوء على أهميته. | |||
| 2023-10-06 | قمع النسخ: فهم شامل لرأس الانتباه | ||
| • يقدم البحث مفهوم منع النسخ في رأس الانتباه الصغير GPT-2 (L10H7)، مما يقلل من نسخ الرموز المميزة، ويعزز معايرة النموذج. • يبحث البحث ويشرح آلية قمع النسخ ودوره في الإصلاح الذاتي . • تم شرح 76.9% من تأثير L10H7 في GPT-2 Small، مما يجعله الوصف الأكثر شمولاً لدور رئيس الاهتمام. | |||
| 2023-09-22 | التدخل في وقت الاستدلال: استخلاص الإجابات الصادقة من نموذج اللغة | ||
| • تقديم تدخل وقت الاستدلال (ITI) لتعزيز مصداقية LLM عن طريق ضبط تنشيط النموذج في رؤوس انتباه مختارة. • تحسين أداء نموذج LLaMA وفقًا لمعيار TruthfulQA. • قامت ITI بزيادة صدق نموذج Alpaca من 32.5% إلى 65.1%. | |||
| 2023-09-22 | ولادة محول: وجهة نظر الذاكرة | ||
| • تعرض الورقة منظورًا قائمًا على الذاكرة حول المحولات، مع تسليط الضوء على الذكريات الترابطية في مصفوفات الوزن وتعلمها القائم على التدرج. • التحليل التجريبي لديناميات التدريب على نموذج محول مبسط مع البيانات الاصطناعية. • اكتشاف التعلم العالمي السريع للبيغرامات والظهور البطيء لـ "الرأس التعريفي" للبيغرامات الموجودة في السياق. | |||
| 13-09-2023 | الانخفاض المفاجئ في الخسارة: اكتساب بناء الجملة، وانتقالات المرحلة، وانحياز البساطة في الامتيازات والرهونات البحرية | ||
| • يحدد بنية الاهتمام النحوي (SAS) كخاصية ناشئة بشكل طبيعي في نماذج اللغة المقنعة (الامتيازات والرهون البحرية) ودورها في اكتساب بناء الجملة. • تحليل SAS أثناء التدريب ومعالجته لدراسة تأثيره السببي على القدرات النحوية. • يعد SAS ضروريًا للتطوير النحوي، ولكن إيقافه لفترة وجيزة يؤدي إلى تحسين أداء النموذج. | |||
| 2023-07-18 | هل مقياس تفسير تحليل الدوائر؟ الأدلة من قدرات الاختيار المتعدد في شينشيلا | ||
| • تحليل الدوائر القابلة للتطوير المطبق على نموذج لغة شينشيلا 70B لفهم الإجابة على أسئلة الاختيار من متعدد. • إسناد السجل، وتصور نمط الاهتمام، وتصحيح التنشيط لتحديد وتصنيف رؤوس الاهتمام الرئيسية. • تم تحديد ميزة "العنصر رقم N في التعداد" في رؤوس الانتباه، على الرغم من أنها مجرد تفسير جزئي. | |||
| 2023-02-02 | قابلية التفسير في البرية: دائرة للتعرف غير المباشر على الكائنات في GPT-2 الصغيرة | ||
| • يقدم البحث شرحاً مفصلاً لكيفية قيام GPT-2 الصغير بالتعرف غير المباشر على الأشياء (IOI) باستخدام دائرة كبيرة تتضمن 28 رأس انتباه مجمعة في 7 فئات. • قاموا بإجراء هندسة عكسية لمهمة IOI في GPT-2 الصغيرة باستخدام التدخلات والتوقعات السببية. • توضح الدراسة أن إمكانية التفسير الآلي لنماذج اللغة الكبيرة أمر ممكن. | |||
| تاريخ | ورقة وملخص | العلامات | روابط |
| 2022-03-08 | رؤساء التعلم والتوجيه في السياق | ||
| • تحدد الورقة "الرؤوس التعريفية" في نماذج المحولات، والتي تتيح التعلم في السياق من خلال التعرف على الأنماط ونسخها بالتسلسل. • تحليل أنماط الاهتمام ورؤساء التعريفي عبر طبقات مختلفة في نماذج محولات مختلفة. • وجدت أن الرؤوس التعريفية ضرورية لتمكين المحولات من تعميم وتنفيذ مهام التعلم في السياق بشكل فعال. | |||
| 2021-12-22 | إطار رياضي لدوائر المحولات | ||
| • يقدم إطارًا رياضيًا لإجراء هندسة عكسية للمحولات الصغيرة التي تركز على الانتباه فقط، مع التركيز على فهم رؤوس الانتباه كمكونات مستقلة ومضافة. • تحليل المحولات الصفرية والواحدة والثنائية للتعرف على دور رؤوس الانتباه في حركة المعلومات وتركيبها. • تم اكتشاف "رؤوس الحث"، وهي ضرورية للتعلم في السياق في المحولات ذات الطبقتين. | |||
| 2021-05-18 | فرضية الرؤوس: نهج إحصائي موحد نحو فهم الاهتمام متعدد الرؤوس في BERT | ||
| • تقترح الورقة طريقة جديدة تسمى "الانتباه المتناثر" والتي تقلل من التعقيد الحسابي لآليات الانتباه من خلال التركيز بشكل انتقائي على الرموز المهمة. • تم تقييم الطريقة على مهام الترجمة الآلية وتصنيف النصوص. • يحقق نموذج الاهتمام المتفرق دقة مماثلة للانتباه المكثف مع تقليل التكلفة الحسابية بشكل كبير. | |||
| 2021-04-01 | هل تعلم الرؤساء في BERT قواعد الدائرة الانتخابية؟ | ||
| • تقدم الدراسة طريقة المسافة النحوية لتحليل القواعد النحوية للدوائر الانتخابية في رؤساء الاهتمام BERT وRoBERTA. • تم استخراج القواعد النحوية للدوائر الانتخابية وتحليلها قبل وبعد الضبط الدقيق لمهام الرسائل القصيرة وNLI. • تعمل مهام NLI على زيادة القدرة على تحفيز القواعد النحوية للدائرة الانتخابية، في حين تعمل مهام الرسائل القصيرة على تقليلها في الطبقات العليا. | |||
| 2019-11-27 | هل يقوم رؤساء الانتباه في BERT بتتبع التبعيات النحوية؟ | ||
| • يبحث البحث في ما إذا كانت رؤوس الانتباه الفردية في BERT تلتقط التبعيات النحوية، وذلك باستخدام أوزان الانتباه لاستخراج علاقات التبعية. • تحليل رؤوس انتباه بيرت باستخدام أقصى أوزان الانتباه والحد الأقصى من الأشجار الممتدة، ومقارنتها بأشجار التبعية العالمية. • بعض رؤوس الانتباه تتبع تبعيات تجمزية محددة أفضل من خطوط الأساس ، ولكن لا يوجد رأس يؤدي تحليلًا شاملًا بشكل أفضل. | |||
| 2019-11-01 | محولات متناثرة على التكيف | ||
| • أدخل المحول المتفرق على التكيف باستخدام alpha-entmax للسماح بتفوق مرن يعتمد على السياق في رؤوس الانتباه. • تم تطبيقه على مجموعات بيانات الترجمة الآلية لتقييم القابلية للتفسير وتنوع الرأس. • حقق توزيعات الاهتمام المتنوعة وتحسين القابلية للتفسير دون المساس بالدقة. | |||
| 2019-08-01 | ماذا ينظر بيرت؟ تحليل لانتباه بيرت | ||
| • تقدم الورقة طرقًا لتحليل آليات انتباه بيرت ، وكشف أنماطًا تتماشى مع الهياكل اللغوية مثل بناء الجملة والمواد الأساسية. • تحليل رؤساء الانتباه ، وتحديد الأنماط النحوية والأساسية ، وتطوير مصنف تحقيق يستند إلى الاهتمام. • يلتقط رؤساء انتباه بيرت معلومات نحوية كبيرة ، وخاصة في مهام مثل تحديد الكائنات المباشرة والمؤتمر الأساسي. | |||
| 2019-07-01 | تحليل الاهتمام الذاتي متعدد الرأس: رؤساء متخصصون يقومون بالرفع الثقيل ، يمكن تقليم الباقي | ||
| • تقدم الورقة طريقة تشذيب جديدة للاعتداء الذاتي متعدد الرأس والتي تزيل بشكل انتقائي رؤوس أقل أهمية دون فقدان الأداء الرئيسي. • تحليل رؤساء الانتباه الفردي ، وتحديد أدوارهم المتخصصة ، وتطبيق طريقة التقليم على نموذج المحول. • التقليم 38 من أصل 48 رأسًا في التشفير أدى إلى انخفاض درجة 0.15 Bleu فقط. | |||
| 2018-11-01 | تحليل لتمثيل التشفير في الترجمة الآلية القائمة على المحولات | ||
| • تحلل هذه الورقة التمثيلات الداخلية لطبقات تشفير المحولات ، مع التركيز على المعلومات النحوية والدلالية التي تعلمتها رؤساء الاهتمام الذاتي. • تحقيق المهام ، واستخراج علاقة التبعية ، وسيناريو التعلم النقل. • تلتقط الطبقات المنخفضة بناء جملة ، بينما تقوم الطبقات العليا بتشفير معلومات أكثر دلالية. | |||
| 2016-03-21 | دمج آلية النسخ في تعلم التسلسل إلى التسلسل | ||
| • يقدم آلية نسخ في نماذج تسلسل إلى تسلسل للسماح بالنسخ المباشر لرموز المدخلات ، وتحسين معالجة الكلمات النادرة. • المطبق على مهام الترجمة الآلية والتلخيص. • حققت تحسينات كبيرة في دقة الترجمة ، وخاصة على ترجمة الكلمات النادرة ، مقارنة بنماذج التسلسل القياسية إلى التسلسل. | |||
قالب القضية:
Title: [paper's title]
Head: [head name1] (, [head name2] ...)
Published: [arXiv / ACL / ICLR / NIPS / ...]
Summary:
- Innovation:
- Tasks:
- Significant Result:


