BabyGPT Build_GPT_From_Scratch
1.0.0
Baby GPT هو مشروع استكشافي مصمم لبناء نموذج لغة يشبه GPT بشكل تدريجي. يبدأ المشروع بنموذج Bigram بسيط ويدمج تدريجيًا مفاهيم متقدمة من بنية نموذج Transformer.
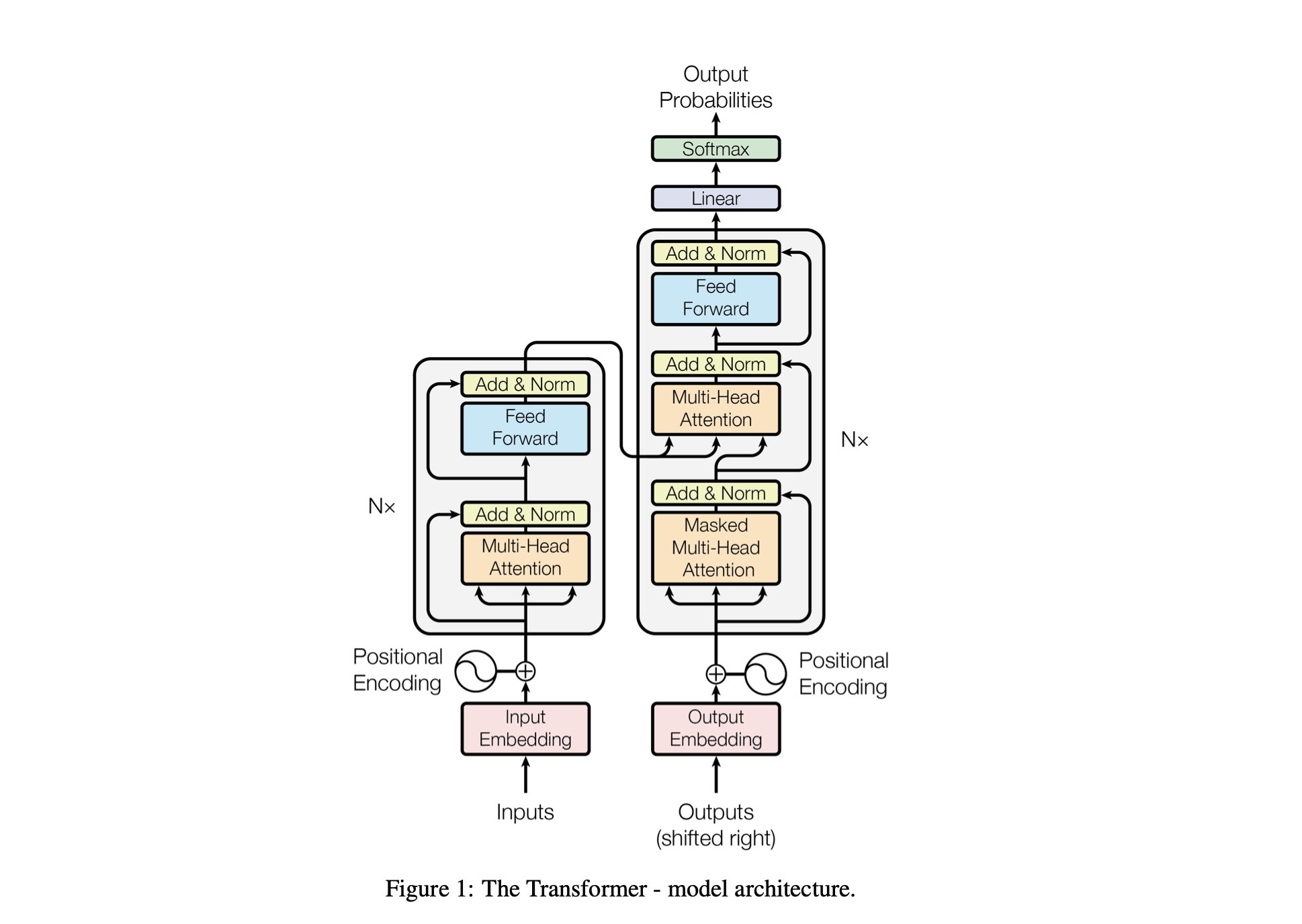
يتم ضبط أداء النموذج باستخدام المعلمات الفائقة التالية:
batch_size : عدد التسلسلات التي تمت معالجتها بالتوازي أثناء التدريبblock_size : طول التسلسلات التي تتم معالجتها بواسطة النموذجd_model : عدد الميزات في النموذج (حجم التضمينات)d_k : عدد الميزات لكل رأس انتباه.num_iter : العدد الإجمالي لتكرارات التدريب التي سيتم تشغيلها في النموذجNx : عدد كتل أو طبقات المحولات في النموذج.eval_interval : الفاصل الزمني الذي يتم فيه حساب خسارة النموذج وتقييمهاlr_rate : معدل التعلم لمحسن Adamdevice : يتم تعيينه تلقائيًا على 'cuda' في حالة توفر وحدة معالجة رسومات متوافقة، وإلا فسيتم تعيينه افتراضيًا على 'cpu' .eval_iters : عدد التكرارات التي يتم من خلالها حساب متوسط خسارة التقييمh : عدد رؤوس الانتباه في آلية الانتباه متعدد الرؤوسdropout_rate : معدل التسرب المستخدم أثناء التدريب لمنع التجهيز الزائدتم اختيار هذه المعلمات الفائقة بعناية لموازنة قدرة النموذج على التعلم من البيانات دون الإفراط في التجهيز وإدارة الموارد الحسابية بشكل فعال.
| المعلمة المفرطة | نموذج وحدة المعالجة المركزية | نموذج GPU |
|---|---|---|
device | "وحدة المعالجة المركزية" | "كودا" إذا كان متاحًا، وإلا "وحدة المعالجة المركزية" |
batch_size | 16 | 64 |
block_size | 8 | 256 |
num_iter | 10000 | 10000 |
eval_interval | 500 | 500 |
eval_iters | 100 | 200 |
d_model | 16 | 512 |
d_k | 4 | 16 |
Nx | 2 | 6 |
dropout_rate | 0.2 | 0.2 |
lr_rate | 0.005 (5e-3) | 0.001 (1e-3) |
h | 2 | 6 |
open('./GPT Series/input.txt', 'r', encoding = 'utf-8')chars_to_int و int_to_chars .encode والعودة مرة أخرى باستخدام وظيفة decode .train_data ) ومجموعات التحقق ( valid_data ).get_batch بإعداد البيانات على دفعات صغيرة للتدريب.BigramLM .التجميع المصغر هو أسلوب في التعلم الآلي حيث يتم تقسيم بيانات التدريب إلى دفعات صغيرة. تتم معالجة كل دفعة صغيرة بشكل منفصل أثناء تدريب النموذج. ويساعد هذا النهج في:
# Function to create mini-batches for training or validation.
def get_batch ( split ):
# Select data based on training or validation split.
data = train_data if split == "train" else valid_data
# Generate random start indices for data blocks, ensuring space for 'block_size' elements.
ix = torch . randint ( len ( data ) - block_size , ( batch_size ,))
# Create input (x) and target (y) sequences from data blocks.
x = torch . stack ([ data [ i : i + block_size ] for i in ix ])
y = torch . stack ([ data [ i + 1 : i + block_size + 1 ] for i in ix ])
# Move data to GPU if available for faster processing.
x , y = x . to ( device ), y . to ( device )
return x , y | عامل | حجم الدفعة الصغيرة | حجم الدفعة الكبيرة |
|---|---|---|
| الضوضاء المتدرجة | أعلى (مزيد من التباين في التحديثات) | أقل (تحديثات أكثر اتساقًا) |
| التقارب | يميل إلى استكشاف المزيد من الحلول، بما في ذلك الحد الأدنى المسطح | في كثير من الأحيان يتقارب إلى الحد الأدنى الأكثر وضوحا |
| تعميم | يحتمل أن يكون أفضل (بسبب الحد الأدنى المسطح) | من المحتمل أن يكون أسوأ (بسبب الحد الأدنى الأكثر وضوحًا) |
| تحيز | أقل (أقل احتمالية للتناسب الزائد مع أنماط بيانات التدريب) | أعلى (قد يتناسب مع أنماط بيانات التدريب) |
| التباين | أعلى (بسبب المزيد من الاستكشاف في مساحة الحل) | أقل (بسبب قلة الاستكشاف في مساحة الحل) |
| التكلفة الحسابية | أعلى لكل عصر (مزيد من التحديثات) | أقل لكل عصر (تحديثات أقل) |
| استخدام الذاكرة | أدنى | أعلى |
تحسب وظيفة estimate_loss متوسط الخسارة للنموذج عبر عدد محدد من التكرارات (eval_iters). يتم استخدامه لتقييم أداء النموذج دون التأثير على معلماته. تم ضبط النموذج على وضع التقييم لتعطيل طبقات معينة مثل التسرب لحساب الخسارة بشكل متسق. بعد حساب متوسط الخسارة لكل من بيانات التدريب والتحقق من الصحة، يتم إرجاع النموذج إلى وضع التدريب. هذه الوظيفة ضرورية لمراقبة عملية التدريب وإجراء التعديلات إذا لزم الأمر.
@ torch . no_grad () # Disables gradient calculation to save memory and computations
def estimate_loss ():
result = {} # Dictionary to store the results
model . eval () # Puts the model in evaluation mode
# Iterates over the data splits (training and validation)
for split in [ 'train' , 'valid_date' ]:
# Initializes a tensor to store the losses for each iteration
losses = torch . zeros ( eval_iters )
# Loops over the number of iterations to calculate the average loss
for e in range ( eval_iters ):
X , Y = get_batch ( split ) # Fetches a batch of data
logits , loss = model ( X , Y ) # Gets the model outputs and computes the loss
losses [ e ] = loss . item () # Records the loss for this iteration
# Stores the mean loss for the current split in the result dictionary
result [ split ] = losses . mean ()
model . train () # Sets the model back to training mode
return result # Returns the dictionary with the computed losses التشفير الموضعي : إضافة معلومات موضعية إلى النموذج باستخدام جدول positional_encodings_table في فئة BigramLM . نضيف الترميزات الموضعية إلى تضمينات شخصياتنا كما هو الحال في بنية المحولات.
قمنا هنا بإعداد واستخدام مُحسِّن AdamW لتدريب نموذج الشبكة العصبية في PyTorch. يُفضل مُحسِّن Adam في العديد من سيناريوهات التعلم العميق لأنه يجمع بين مزايا ملحقين آخرين من أصل التدرج العشوائي: AdaGrad وRMSProp. يحسب آدم معدلات التعلم التكيفي لكل معلمة. بالإضافة إلى تخزين متوسط متدهور بشكل كبير للتدرجات التربيعية السابقة مثل RMSProp، يحتفظ آدم أيضًا بمتوسط متدهور بشكل كبير للتدرجات السابقة، على غرار الزخم. يتيح ذلك للمُحسِّن ضبط معدل التعلم لكل وزن من الشبكة العصبية، مما قد يؤدي إلى تدريب أكثر فعالية على مجموعات البيانات والبنيات المعقدة.
يعدل AdamW الطريقة التي يتم بها دمج تناقص الوزن في عملية التحسين، مما يعالج مشكلة في مُحسِّن Adam الأصلي حيث لا يتم فصل تناقص الوزن بشكل جيد عن تحديثات التدرج، مما يؤدي إلى تطبيق دون المستوى الأمثل للتنظيم. يمكن أن يؤدي استخدام AdamW في بعض الأحيان إلى تحسين أداء التدريب وتعميم البيانات غير المرئية. لقد اخترنا AdamW لقدرته على التعامل مع تناقص الوزن بشكل أكثر فعالية من مُحسِّن Adam القياسي، مما قد يؤدي إلى تحسين التدريب على النماذج والتعميم.
optimizer = torch . optim . AdamW ( model . parameters (), lr = lr_rate )
for iter in range ( num_iter ):
# estimating the loss for per X interval
if iter % eval_interval == 0 :
losses = estimate_loss ()
print ( f"step { iter } : train loss is { losses [ 'train' ]:.5f } and validation loss is { losses [ 'valid_date' ]:.5f } " )
# sampling a mini batch of data
xb , yb = get_batch ( "train" )
# Forward Pass
logits , loss = model ( xb , yb )
# Zeroing Gradients: Before computing the gradients, existing gradients are reset to zero. This is necessary because gradients accumulate by default in PyTorch.
optimizer . zero_grad ( set_to_none = True )
# Backward Pass or Backpropogation: Computing Gradients
loss . backward ()
# Updating the Model Parameters
optimizer . step ()الانتباه الذاتي هو آلية تسمح للنموذج بتقييم أهمية الأجزاء المختلفة من بيانات الإدخال بشكل مختلف. وهو مكون رئيسي في بنية المحولات، مما يمكّن النموذج من التركيز على الأجزاء ذات الصلة من تسلسل الإدخال لإجراء التنبؤات.
انتباه المنتج النقطي : آلية انتباه بسيطة تحسب مجموعًا مرجحًا من القيم استنادًا إلى المنتج النقطي بين الاستعلامات والمفاتيح.
الاهتمام بمنتجات النقاط المقيسة : تحسين على الاهتمام بمنتجات النقاط الذي يعمل على تقليص منتجات النقاط حسب أبعاد المفاتيح، مما يمنع التدرجات من أن تصبح صغيرة جدًا أثناء التدريب.
OneHeadSelfAttention : تنفيذ آلية الاهتمام الذاتي ذات الرأس الواحد التي تسمح للنموذج بالاهتمام بمواضع مختلفة من تسلسل الإدخال. تعرض فئة SelfAttention الحدس الكامن وراء آلية الانتباه ونسختها المتدرجة.
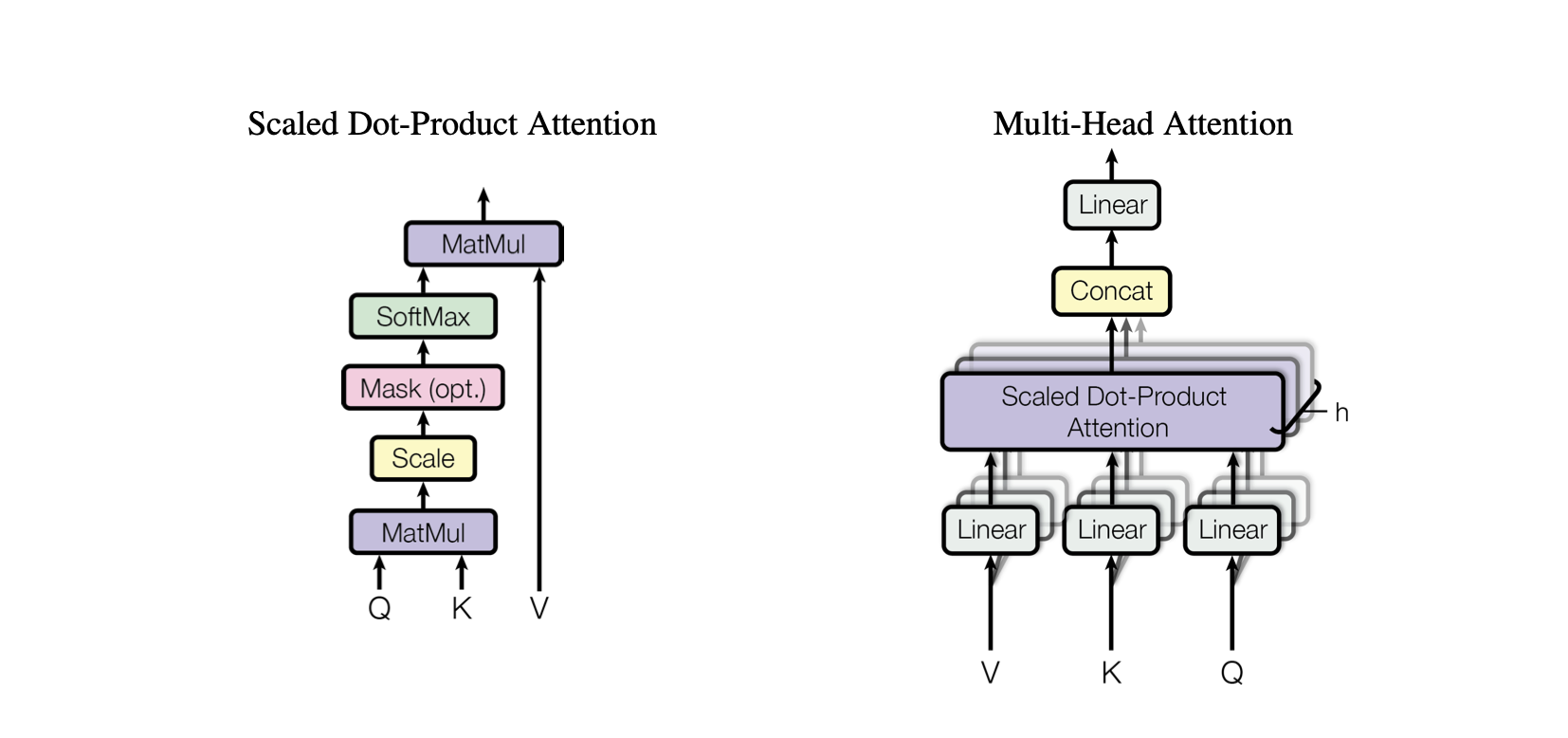
يعتمد كل نموذج مناظر في مشروع Baby GPT تدريجيًا على النموذج السابق، بدءًا من الحدس وراء آلية الاهتمام الذاتي، متبوعًا بالتطبيقات العملية لمنتج النقاط والاهتمامات المتدرجة للمنتج النقطي، وتبلغ ذروتها في تكامل نموذج واحد. وحدة الاهتمام الذاتي للرأس.
class SelfAttention ( nn . Module ):
"""Self Attention (One Head)"""
""" d_k = C """
def __init__ ( self , d_k ):
super (). __init__ () #superclass initialization for proper torch functionality
# keys
self . keys = nn . Linear ( d_model , d_k , bias = False )
# queries
self . queries = nn . Linear ( d_model , d_k , bias = False )
# values
self . values = nn . Linear ( d_model , d_k , bias = False )
# buffer for the model
self . register_buffer ( 'tril' , torch . tril ( torch . ones ( block_size , block_size )))
def forward ( self , X ):
"""Computing Attention Matrix"""
B , T , C = X . shape
# Keys matrix K
K = self . keys ( X ) # (B, T, C)
# Query matrix Q
Q = self . queries ( X ) # (B, T, C)
# Scaled Dot Product
scaled_dot_product = Q @ K . transpose ( - 2 , - 1 ) * 1 / math . sqrt ( C ) # (B, T, T)
# Masking upper triangle
scaled_dot_product_masked = scaled_dot_product . masked_fill ( self . tril [: T , : T ] == 0 , float ( '-inf' ))
# SoftMax transformation
attention_matrix = F . softmax ( scaled_dot_product_masked , dim = - 1 ) # (B, T, T)
# Weighted Aggregation
V = self . values ( X ) # (B, T, C)
output = attention_matrix @ V # (B, T, C)
retur تمثل فئة SelfAttention لبنة أساسية في نموذج Transformer، حيث تغلف آلية الانتباه الذاتي برأس واحد. فيما يلي نظرة ثاقبة على مكوناته وعملياته:
التهيئة : يقوم المنشئ __init__(self, d_k) بتهيئة الطبقات الخطية للمفاتيح والاستعلامات والقيم، وكلها ذات أبعاد d_k . تقوم هذه التحويلات الخطية بإسقاط المدخلات على مساحات فرعية مختلفة لحسابات الانتباه اللاحقة.
المخازن المؤقتة : self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size))) تسجل مصفوفة مثلثية سفلية كمخزن مؤقت مستمر لا يعتبر معلمة نموذج. تُستخدم هذه المصفوفة لإخفاء آلية الانتباه لمنع أخذ المواقف المستقبلية في الاعتبار في كل خطوة حسابية (مفيدة في الانتباه الذاتي لوحدة فك التشفير).
التمرير الأمامي : تحدد الطريقة forward(self, X) الحساب الذي يتم إجراؤه عند كل استدعاء لوحدة الانتباه الذاتي
MultiHeadAttention : الجمع بين المخرجات من رؤوس SelfAttention المتعددة في فئة MultiHeadAttention . تعد فئة MultiHeadAttention بمثابة تطبيق موسع لآلية الانتباه الذاتي برأس واحد من الخطوة السابقة، ولكن الآن تعمل رؤوس الانتباه المتعددة بالتوازي، يركز كل منها على أجزاء مختلفة من المدخلات.
class MultiHeadAttention ( nn . Module ):
"""Multi Head Self Attention"""
"""h: #heads"""
def __init__ ( self , h , d_k ):
super (). __init__ ()
# initializing the heads, we want h times attention heads wit size d_k
self . heads = nn . ModuleList ([ SelfAttention ( d_k ) for _ in range ( h )])
# adding linear layer to project the concatenated heads to the original dimension
self . projections = nn . Linear ( h * d_k , d_model )
# adding dropout layer
self . droupout = nn . Dropout ( dropout_rate )
def forward ( self , X ):
# running multiple self attention heads in parallel and concatinate them at channel dimension
combined_attentions = torch . cat ([ h ( X ) for h in self . heads ], dim = - 1 )
# projecting the concatenated heads to the original dimension
combined_attentions = self . projections ( combined_attentions )
# applying dropout
combined_attentions = self . droupout ( combined_attentions )
return combined_attentions
FeedForward : تنفيذ الشبكة العصبية ذات التغذية الأمامية مع تنشيط ReLU ضمن فئة FeedForward . لإضافة هذا التغذية الأمامية المتصلة بالكامل إلى نموذجنا كما هو الحال في نموذج المحول الأصلي.
class FeedForward ( nn . Module ):
"""FeedForward Layer with ReLU activation function"""
def __init__ ( self , d_model ):
super (). __init__ ()
self . net = nn . Sequential (
# 2 linear layers with ReLU activation function
nn . Linear ( d_model , 4 * d_model ),
nn . ReLU (),
nn . Linear ( 4 * d_model , d_model ),
nn . Dropout ( dropout_rate )
)
def forward ( self , X ):
# applying the feedforward layer
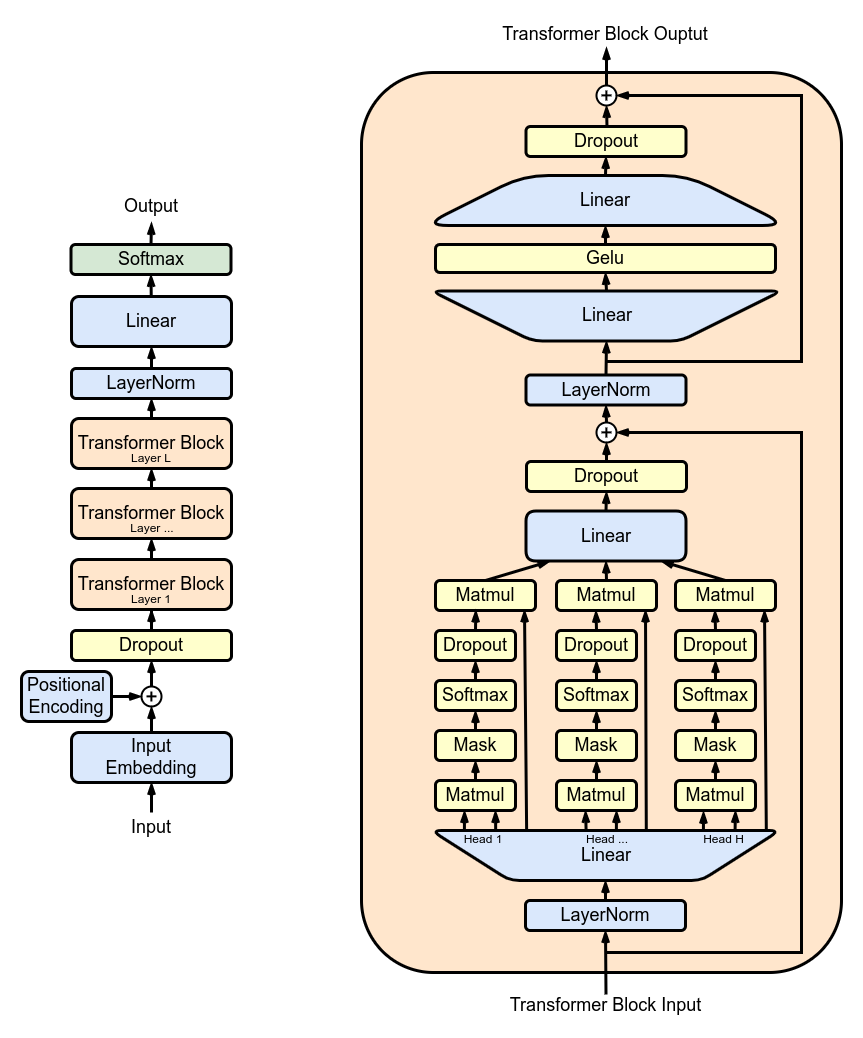
return self . net ( X ) TransformerBlocks : تكديس كتل المحولات باستخدام فئة Block لإنشاء بنية شبكة أعمق. العمق والتعقيد: في الشبكات العصبية، يشير العمق إلى عدد الطبقات التي تتم من خلالها معالجة البيانات. تسمح كل طبقة إضافية (أو كتلة، في حالة المحولات) للشبكة بالتقاط ميزات أكثر تعقيدًا وتجريدًا لبيانات الإدخال.
المعالجة التسلسلية: تقوم كل كتلة محولات بمعالجة مخرجات الكتلة السابقة لها، مما يؤدي تدريجيًا إلى بناء فهم أكثر تعقيدًا للمدخلات. تسمح هذه المعالجة التسلسلية للشبكة بتطوير تمثيل عميق ومتعدد الطبقات للبيانات. مكونات كتلة المحولات
# ---------------------------------- Blocks ----------------------------------#
class Block ( nn . Module ):
"""Multiple Blocks of Transformer"""
def __init__ ( self , d_model , h ):
super (). __init__ ()
d_k = d_model // h
# Layer 4: Adding Attention layer
self . attention_head = MultiHeadAttention ( h , d_k ) # h heads of d_k dimensional self-attention
# Layer 5: Feed Forward layer
self . feedforward = FeedForward ( d_model )
# Layer Normalization 1
self . ln1 = nn . LayerNorm ( d_model )
# Layer Normalization 2
self . ln2 = nn . LayerNorm ( d_model )
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X ResidualConnections : تعزيز فئة Block لتشمل الاتصالات المتبقية، وتحسين كفاءة التعلم. تعد الاتصالات المتبقية، والمعروفة أيضًا باسم الاتصالات التخطيية، ابتكارًا مهمًا في تصميم الشبكات العصبية العميقة، خاصة في نماذج المحولات. إنها تعالج أحد التحديات الأساسية في تدريب الشبكات العميقة: مشكلة التدرج المتلاشي.
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X LayerNorm : إضافة تسوية الطبقة إلى مخرجات طبقة Transformer.Normalizing الخاصة بنا باستخدام nn.LayerNorm(d_model) في فئة Block .
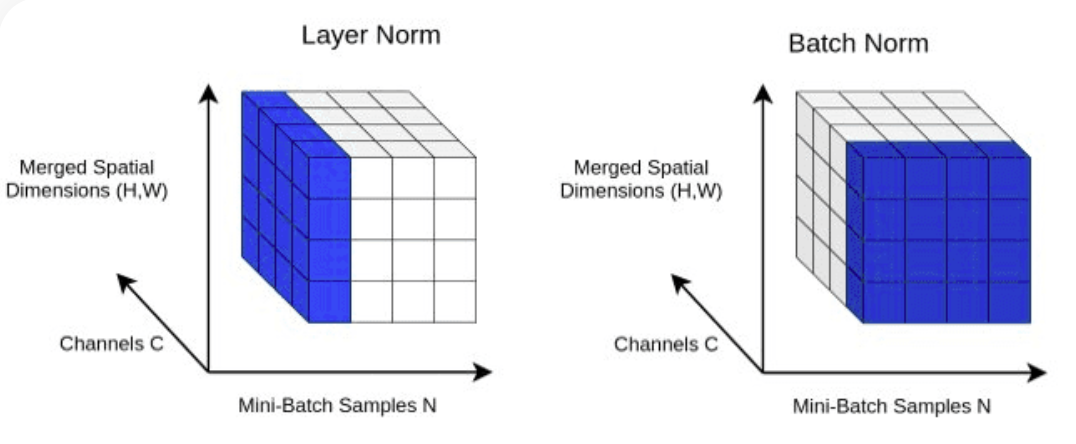
class LayerNorm :
def __init__ ( self , dim , eps = 1e-5 ):
self . eps = eps
self . gamma = torch . ones ( dim )
self . beta = torch . zeros ( dim )
def __call__ ( self , x ):
# orward pass calculaton
xmean = x . mean ( 1 , keepdim = True ) # layer mean
xvar = x . var ( 1 , keepdim = True ) # layer variance
xhat = ( x - xmean ) / torch . sqrt ( xvar + self . eps ) # normalize to unit variance
self . out = self . gamma * xhat + self . beta
return self . out
def parameters ( self ):
return [ self . gamma , self . beta ] التسرب : ليتم إضافتها إلى طبقتي SelfAttention و FeedForward كطريقة تنظيم لمنع التجاوز. نضيف التسرب إلى:
ScaleUp : زيادة تعقيد النموذج من خلال توسيع batch_size و block_size و d_model و d_k و Nx . ستحتاج إلى مجموعة أدوات CUDA بالإضافة إلى جهاز مزود بوحدة معالجة الرسومات NVIDIA لتدريب هذا النموذج الأكبر واختباره.
إذا كنت تريد تجربة CUDA لتسريع GPU، فتأكد من تثبيت الإصدار المناسب من PyTorch الذي يدعم CUDA.
import torch
torch . cuda . is_available ()يمكنك القيام بذلك عن طريق تحديد إصدار CUDA في أمر تثبيت PyTorch، كما هو الحال في سطر الأوامر:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113

