PixArt alpha
1.0.0
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txtسيتم تنزيل جميع النماذج تلقائيًا. يمكنك أيضًا اختيار التنزيل يدويًا من عنوان url هذا.
| نموذج | #بارامس | عنوان URL | تحميل في OpenXLab |
|---|---|---|---|
| T5 | 4.3 ب | T5 | T5 |
| ضريبة القيمة المضافة | 80 م | ضريبة القيمة المضافة | ضريبة القيمة المضافة |
| بيكسارت-α-SAM-256 | 0.6 ب | PixArt-XL-2-SAM-256x256.pth أو إصدار الناشرين | 256-سام |
| بيكسارت-α-256 | 0.6 ب | PixArt-XL-2-256x256.pth أو إصدار الناشرين | 256 |
| بيكس آرت-α-256-MSCOCO-FID7.32 | 0.6 ب | بيكسارت-XL-2-256x256.pth | 256 |
| بيكسارت-α-512 | 0.6 ب | PixArt-XL-2-512x512.pth أو إصدار الناشرين | 512 |
| بيكسارت-α-1024 | 0.6 ب | PixArt-XL-2-1024-MS.pth أو إصدار الناشرين | 1024 |
| بيكسارت-δ-1024-LCM | 0.6 ب | نسخة الناشرون | |
| ControlNet-HED-التشفير | 30 م | ControlNetHED.pth | |
| بيكس آرت-δ-512-ControlNet | 0.9 ب | PixArt-XL-2-512-ControlNet.pth | 512 |
| بيكس آرت-δ-1024-ControlNet | 0.9 ب | PixArt-XL-2-1024-ControlNet.pth | 1024 |
يمكنك أيضًا العثور على جميع النماذج في OpenXLab_PixArt-alpha
أولاً.
بفضل @kopyl، يمكنك إعادة إنتاج تدفق التدريب الدقيق الكامل على مجموعة بيانات Pokemon من HugginFace باستخدام دفاتر الملاحظات:
ثم لمزيد من التفاصيل.
نحن هنا نأخذ تكوين التدريب على مجموعة بيانات SAM كمثال، ولكن بالطبع، يمكنك أيضًا إعداد مجموعة البيانات الخاصة بك باتباع هذه الطريقة.
ما عليك سوى تغيير ملف التكوين في التكوين ومحمل البيانات في مجموعة البيانات.
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256بنية الدليل لمجموعة بيانات SAM هي:
cd ./data
SA1B
├──images/ (images are saved here)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (corresponding captions are saved here, same name as images)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (all image names are stored txt file where each line is a image name)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (run tools/extract_caption_feature.py to generate caption T5 features, same name as images except .npz extension)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (run tools/extract_img_vae_feature.py to generate image VAE features, same name as images except .npy extension)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
هنا نقوم بإعداد data_toy لفهم أفضل
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toyثم، إليك مثال لملف Partition/part0.txt.
علاوة على ذلك، بالنسبة للتدريب الموجه حول ملف json، إليك ملف json للعبة لفهمه بشكل أفضل.
اتباع الإرشادات التدريبية Pixart + DreamBooth
اتباع إرشادات التدريب الخاصة PixArt + LCM
اتباع الإرشادات التدريبية PixArt + ControlNet
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision= " fp16 "
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column= " text "
--resolution=1024 --random_flip
--train_batch_size=16
--num_train_epochs=200 --checkpointing_steps=100
--learning_rate=1e-06 --lr_scheduler= " constant " --lr_warmup_steps=0
--seed=42
--output_dir= " pixart-pokemon-model "
--validation_prompt= " cute dragon creature " --report_to= " tensorboard "
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5
--rank=16 يتطلب الاستدلال ما لا يقل عن 23GB من ذاكرة وحدة معالجة الرسومات باستخدام هذا الريبو، بينما يستخدم 11GB and 8GB في ؟ الناشرون.
الدعم حاليا:
للبدء، قم أولاً بتثبيت التبعيات المطلوبة. تأكد من أنك قمت بتنزيل النماذج إلى مجلد Output/pretrained_models، ثم قم بتشغيلها على جهازك المحلي:
DEMO_PORT=12345 python app/app.pyوكبديل، يتم توفير نموذج Dockerfile لإنشاء حاوية وقت التشغيل التي تبدأ تطبيق Gradio.
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v < path_to_huggingface_cache > :/root/.cache/huggingface pixartأو استخدم عامل الإرساء. ملاحظة، إذا كنت تريد تغيير السياق من إصدار 1024 إلى 512 أو LCM للتطبيق، فما عليك سوى تغيير متغير البيئة APP_CONTEXT في ملف docker-compose.yml. الافتراضي هو 1024
docker compose build
docker compose up دعونا نلقي نظرة على مثال بسيط باستخدام http://your-server-ip:12345 .
تأكد من حصولك على الإصدارات المحدثة من المكتبات التالية:
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4وثم:
import torch
from diffusers import PixArtAlphaPipeline , ConsistencyDecoderVAE , AutoencoderKL
device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
# You can replace the checkpoint id with "PixArt-alpha/PixArt-XL-2-512x512" too.
pipe = PixArtAlphaPipeline . from_pretrained ( "PixArt-alpha/PixArt-XL-2-1024-MS" , torch_dtype = torch . float16 , use_safetensors = True )
# If use DALL-E 3 Consistency Decoder
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# If use SA-Solver sampler
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# If loading a LoRA model
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# Enable memory optimizations.
# pipe.enable_model_cpu_offload()
pipe . to ( device )
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe ( prompt ). images [ 0 ]
image . save ( "./catcus.png" )راجع الوثائق للحصول على مزيد من المعلومات حول SA-Solver Sampler.
يسمح هذا التكامل بتشغيل المسار بحجم دفعة يبلغ 4 أقل من 11 جيجابايت من GPU VRAM. تحقق من الوثائق لمعرفة المزيد.
PixArtAlphaPipeline في ذاكرة فيديو GPU بسعة أقل من 8 جيجابايتأصبح استهلاك GPU VRAM أقل من 8 جيجابايت مدعومًا الآن، برجاء الرجوع إلى الوثائق لمزيد من المعلومات.
للبدء، قم أولاً بتثبيت التبعيات المطلوبة، ثم قم بتشغيلها على جهازك المحلي:
# diffusers version
DEMO_PORT=12345 python app/app.py دعونا نلقي نظرة على مثال بسيط باستخدام http://your-server-ip:12345 .
يمكنك أيضًا النقر هنا للحصول على نسخة تجريبية مجانية من Google Colab.
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (True if you use PixArtMS else False) --orig_ckpt_path path/to/pth --dump_path path/to/diffusers --only_transformer=True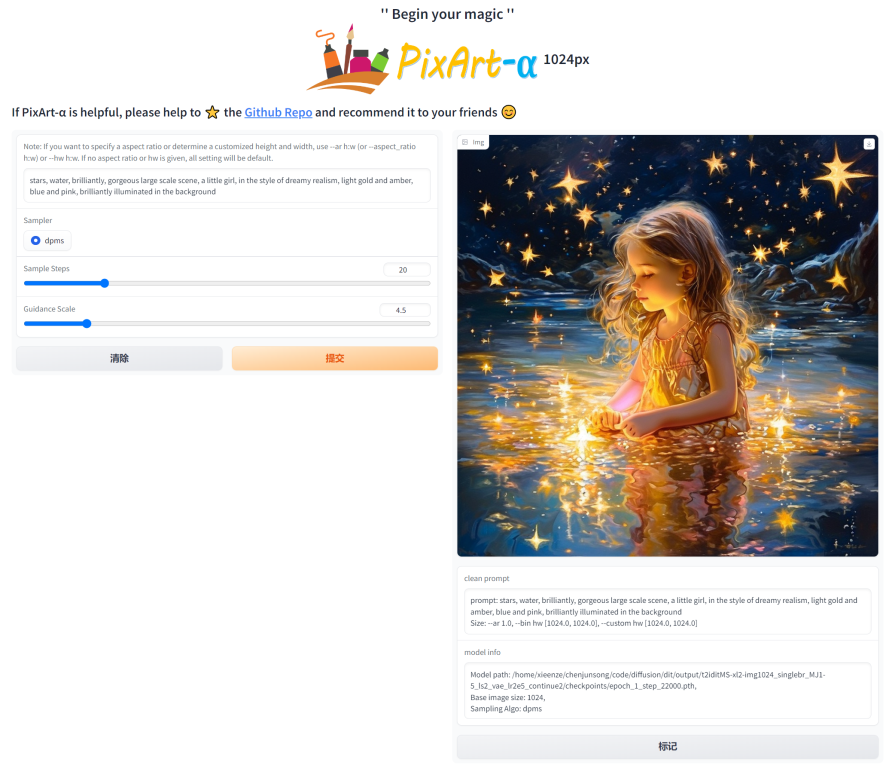
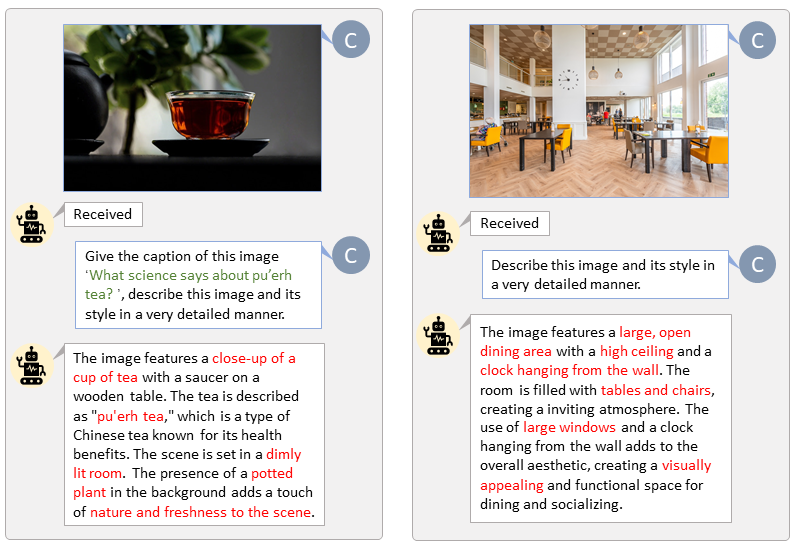
بفضل قاعدة التعليمات البرمجية الخاصة بـ LLaVA-Lightning-MPT، يمكننا تسمية مجموعة بيانات LAION وSAM بكود التشغيل التالي:
python tools/VLM_caption_lightning.py --output output/dir/ --data-root data/root/path --index path/to/data.jsonنقدم وضع العلامات التلقائية مع مطالبات مخصصة لـ LAION (يسار) وSAM (يمين). تمثل الكلمات المميزة باللون الأخضر التسمية التوضيحية الأصلية في LAION، بينما تشير الكلمات المميزة باللون الأحمر إلى التسميات التوضيحية التفصيلية التي تحمل علامة LLaVA.
سيؤدي إعداد ميزة النص T5 وميزة صورة VAE مسبقًا إلى تسريع عملية التدريب وتوفير ذاكرة وحدة معالجة الرسومات.
python tools/extract_features.py --img_size=1024
--json_path " data/data_info.json "
--t5_save_root " data/SA1B/caption_feature_wmask "
--vae_save_root " data/SA1B/img_vae_features "
--pretrained_models_dir " output/pretrained_models "
--dataset_root " data/SA1B/Images/ " لقد قمنا بعمل فيديو يقارن PixArt مع أقوى نماذج تحويل النص إلى صورة الحالية.
@misc{chen2023pixartalpha,
title={PixArt-$alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis},
author={Junsong Chen and Jincheng Yu and Chongjian Ge and Lewei Yao and Enze Xie and Yue Wu and Zhongdao Wang and James Kwok and Ping Luo and Huchuan Lu and Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{delta}: Fast and Controllable Image Generation with Latent Consistency Models},
author={Junsong Chen and Yue Wu and Simian Luo and Enze Xie and Sayak Paul and Ping Luo and Hang Zhao and Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


