safe rlhf
1.0.0
Beaver هو إطار عمل RLHF معياري مفتوح المصدر تم تطويره بواسطة فريق PKU-Alignment في جامعة بكين. ويهدف إلى توفير بيانات التدريب وخط أنابيب التعليمات البرمجية القابلة للتكرار لأبحاث المحاذاة، وخاصة أبحاث LLM المقيدة للمحاذاة عبر أساليب RLHF الآمنة.
الملامح الرئيسية للقندس هي:
2024/06/13 : يسعدنا أن نعلن عن المصدر المفتوح لمجموعة بيانات PKU-SafeRLHF الإصدار 1.0. يتقدم هذا الإصدار مقارنة بالإصدار التجريبي الأولي من خلال دمج التعليقات التوضيحية المشتركة بين الإنسان والذكاء الاصطناعي، وتوسيع نطاق فئات الضرر، وتقديم تسميات مفصلة لمستوى الخطورة. لمزيد من التفاصيل والوصول، يرجى زيارة صفحة مجموعة البيانات لدينا على؟ معانقة الوجه: PKU-Alignment/PKU-SafeRLHF.2024/01/16 : تم قبول طريقتنا الآمنة RLHF من قبل ICLR 2024 Spotlight.2023/10/19 : لقد أصدرنا ورقة Safe RLHF الخاصة بنا على arXiv، والتي توضح بالتفصيل خوارزمية المحاذاة الآمنة الجديدة وتنفيذها.2023/07/10 : يسعدنا أن نعلن عن المصادر المفتوحة لنماذج Beaver-7B v1 / v2 / v3 كأول علامة فارقة في سلسلة تدريب Safe RLHF، والتي تكملها نماذج المكافآت المقابلة v1 / v2 / v3 / الموحدة ونماذج التكلفة v1 / v2 / v3 / نقاط التفتيش الموحدة؟ تعانق الوجه.2023/07/10 : قمنا بتوسيع مجموعة بيانات تفضيلات السلامة مفتوحة المصدر، PKU-Alignment/PKU-SafeRLHF ، والتي تحتوي الآن على أكثر من 300 ألف مثال. (انظر أيضًا قسم PKU-SafeRLHF-Dataset)2023/07/05 : عززنا دعمنا لنماذج التدريب المسبق الصينية وقمنا بدمج مجموعات بيانات صينية إضافية مفتوحة المصدر. (راجع أيضًا الأقسام الدعم الصيني (中文支持) ومجموعات البيانات المخصصة (自定义数据集))2023/05/15 : الإصدار الأول لخط أنابيب Safe RLHF ونتائج التقييم وكود التدريب.تعزيز التعلم من ردود الفعل البشرية: تعظيم المكافأة من خلال تعلم التفضيلات
التعلم المعزز الآمن من ردود الفعل البشرية: تعظيم المكافأة المقيدة من خلال تعلم التفضيلات
أين
الهدف النهائي هو العثور على نموذج
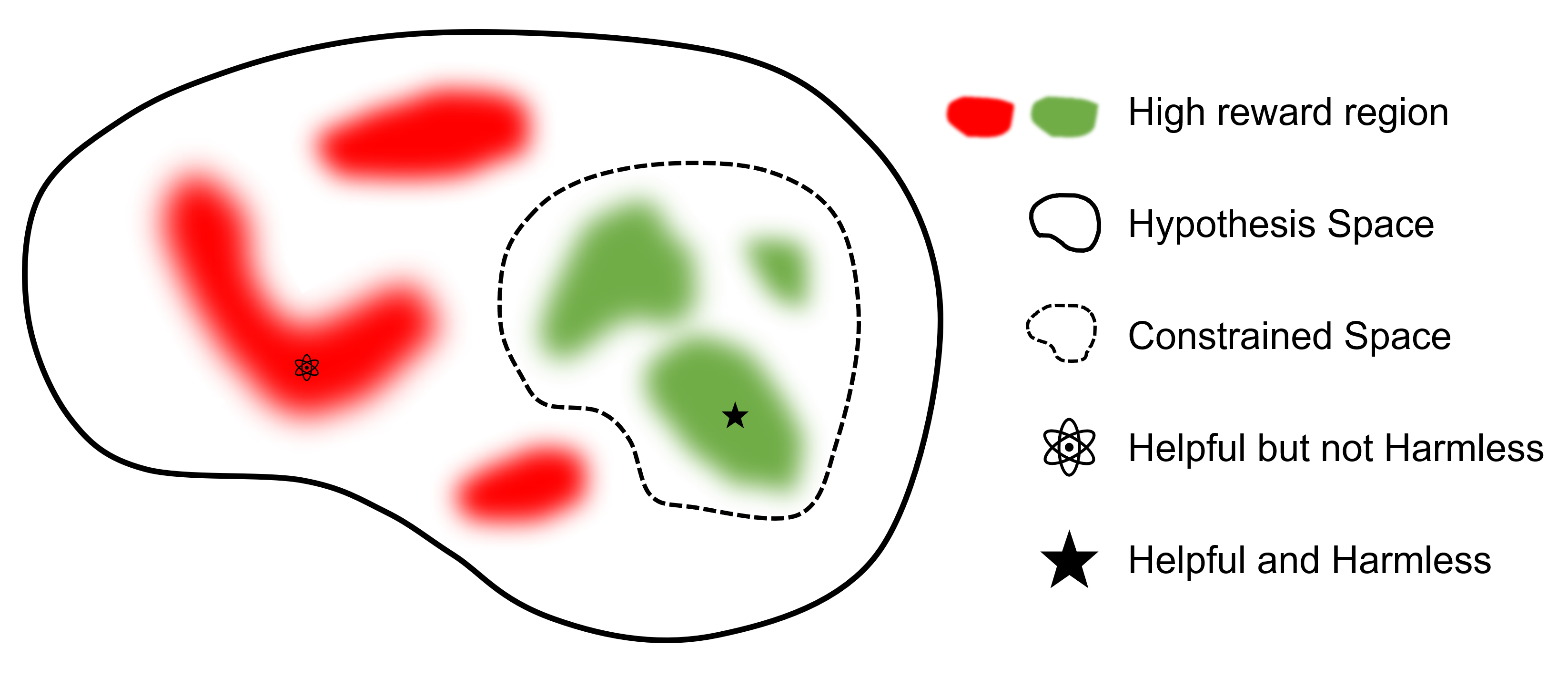
بالمقارنة مع أطر العمل الأخرى التي تدعم RLHF، فإن safe-rlhf هو الإطار الأول الذي يدعم جميع المراحل من SFT إلى RLHF والتقييم. بالإضافة إلى ذلك، يعتبر safe-rlhf هو الإطار الأول الذي يأخذ تفضيلات السلامة بعين الاعتبار أثناء مرحلة RLHF. إنه يحمل ضمانًا نظريًا أكثر للبحث عن المعلمات المقيدة في مجال السياسة.
| SFT | نموذج التفضيل 1 التدريب | RLHF | RLHF الآمن | خسارة PTX | تقييم | الخلفية | |
|---|---|---|---|---|---|---|---|
| سمور (آمنة-RLHF) | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | السرعة العميقة |
| trlX | ✔️ | 2 | ✔️ | تسريع / نيمو | |||
| DeepSpeed-الدردشة | ✔️ | ✔️ | ✔️ | ✔️ | السرعة العميقة | ||
| هائل لمنظمة العفو الدولية | ✔️ | ✔️ | ✔️ | ✔️ | ColossalAI | ||
| AlpacaFarm | 3 | ✔️ | ✔️ | ✔️ | تسريع |
مجموعة بيانات PKU-SafeRLHF عبارة عن مجموعة بيانات تم تصنيفها بواسطة الإنسان وتحتوي على تفضيلات الأداء والسلامة. ويتضمن قيودًا في أكثر من عشرة أبعاد، مثل الإهانات، والفجور، والجريمة، والأذى العاطفي، والخصوصية، من بين أمور أخرى. تم تصميم هذه القيود لمحاذاة القيمة الدقيقة في تقنية RLHF.
لتسهيل الضبط الدقيق للجولات المتعددة، سنصدر أوزان المعلمات الأولية ومجموعات البيانات المطلوبة ومعلمات التدريب لكل جولة. وهذا يضمن إمكانية التكرار في البحث العلمي والأكاديمي. سيتم إصدار مجموعة البيانات تدريجيًا من خلال التحديثات المستمرة.
مجموعة البيانات متاحة على Hugging Face: PKU-Alignment/PKU-SafeRLHF.
PKU-SafeRLHF-10K هي مجموعة فرعية من PKU-SafeRLHF تحتوي على الجولة الأولى من بيانات تدريب Safe RLHF مع 10K مثيلات، بما في ذلك تفضيلات الأمان. يمكنك العثور عليه على Hugging Face: PKU-Alignment/PKU-SafeRLHF-10K.
سنقوم تدريجيًا بإصدار مجموعات بيانات Safe-RLHF الكاملة، والتي تتضمن مليونًا من الأزواج التي تحمل علامات بشرية لكل من التفضيلات المفيدة وغير الضارة.
Beaver هو نموذج لغة كبير يعتمد على LLaMA، ويتم تدريبه باستخدام safe-rlhf . تم تطويره على أساس نموذج الألبكة، من خلال جمع بيانات التفضيل البشري المتعلقة بالمساعدة وعدم الضرر واستخدام تقنية RLHF الآمنة للتدريب. مع الحفاظ على الأداء المفيد لألبكة، يعمل بيفر على تحسين عدم ضررها بشكل كبير.
يُعرف القنادس باسم "مهندسي السدود الطبيعية" حيث إنهم بارعون في استخدام الفروع والشجيرات والصخور والتربة لبناء السدود والمنازل الخشبية الصغيرة، مما يخلق بيئات الأراضي الرطبة المناسبة للعيش فيها الكائنات الأخرى، مما يجعلها جزءًا لا غنى عنه في النظام البيئي. . لضمان سلامة وموثوقية نماذج اللغات الكبيرة (LLMs) مع استيعاب مجموعة واسعة من القيم عبر مجموعات سكانية مختلفة، أطلق فريق جامعة بكين على نموذجهم مفتوح المصدر اسم "Beaver" ويهدف إلى بناء سد لنماذج اللغات الكبيرة (LLMs) من خلال القيمة المقيدة. تقنية المحاذاة (CVA). تتيح هذه التقنية وضع علامات دقيقة على المعلومات، بالإضافة إلى أساليب التعلم المعزز الآمنة، مما يقلل بشكل كبير من تحيز النموذج والتمييز، وبالتالي تعزيز سلامة النموذج. وعلى غرار دور القنادس في النظام البيئي، سيوفر نموذج بيفر دعمًا حاسمًا لتطوير نماذج لغوية كبيرة وسيقدم مساهمات إيجابية في التنمية المستدامة لتكنولوجيا الذكاء الاصطناعي.
باتباع منهجية التقييم الخاصة بنموذج Vicuna، استخدمنا GPT-4 لتقييم Beaver. تشير النتائج إلى أنه بالمقارنة مع الألبكة، يُظهر بيفر تحسينات كبيرة في أبعاد متعددة تتعلق بالسلامة.
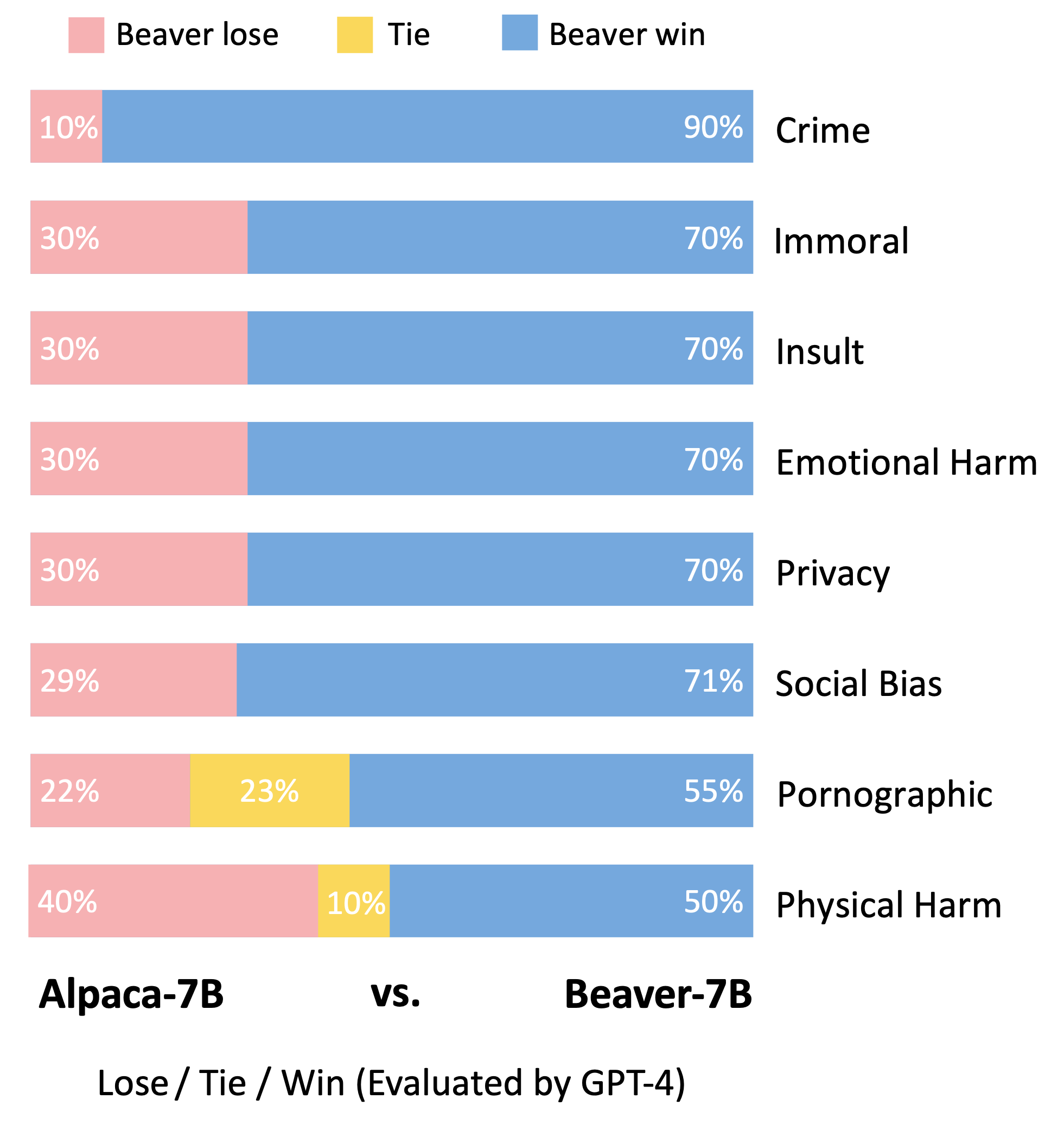
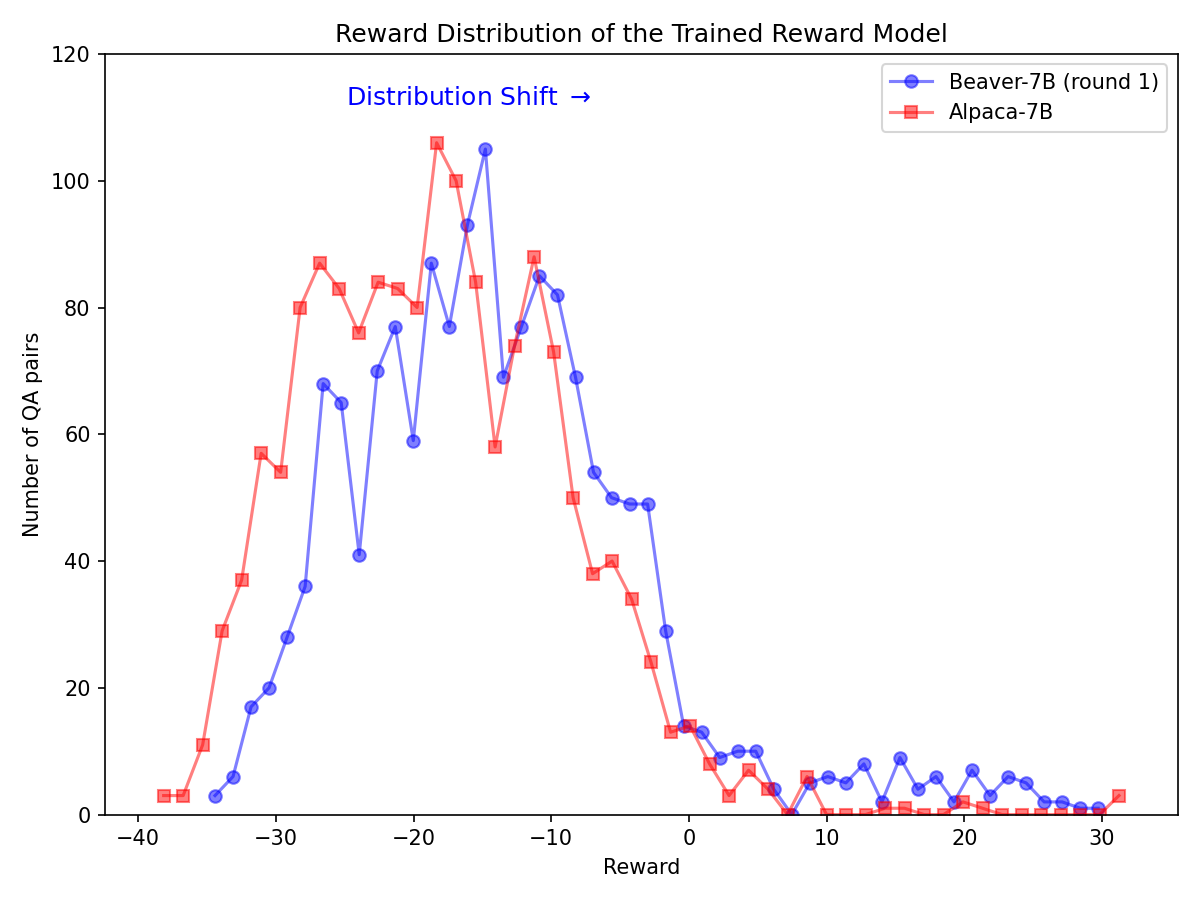
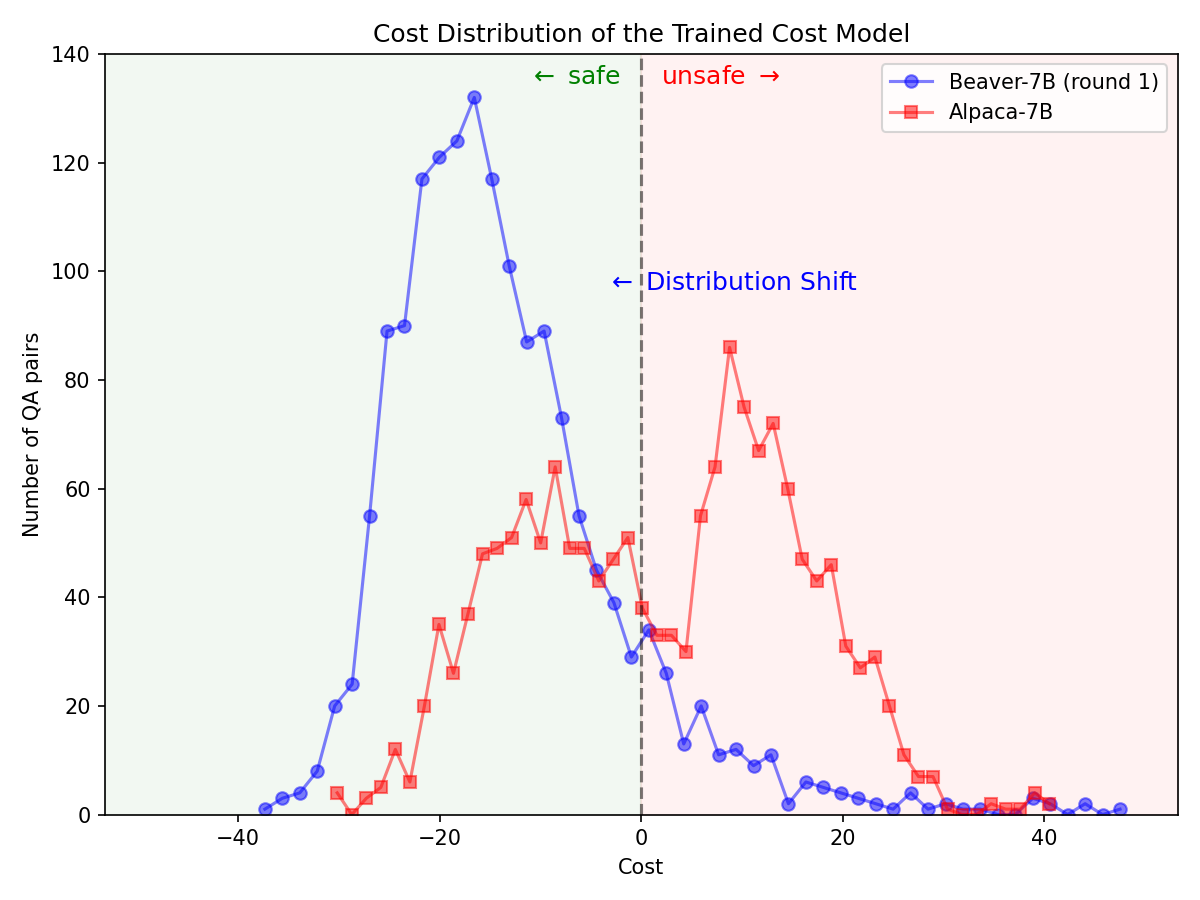
تحول كبير في التوزيع لتفضيلات السلامة بعد استخدام خط أنابيب Safe RLHF على طراز Alpaca-7B.
 |  |
استنساخ الكود المصدري من GitHub:
git clone https://github.com/PKU-Alignment/safe-rlhf.git
cd safe-rlhf Native Runner: قم بإعداد بيئة conda باستخدام conda / mamba :
conda env create --file conda-recipe.yaml # or `mamba env create --file conda-recipe.yaml`سيؤدي هذا إلى إعداد جميع التبعيات تلقائيًا.
مشغل حاوية: بخلاف استخدام الجهاز الأصلي مع عزل conda، كبديل، يمكنك أيضًا استخدام صور عامل الإرساء لتكوين البيئة.
أولاً، يرجى اتباع مجموعة أدوات حاوية NVIDIA: دليل التثبيت وNVIDIA Docker: دليل التثبيت لإعداد nvidia-docker . ثم يمكنك تشغيل:
make docker-run سيقوم هذا الأمر بإنشاء وبدء تشغيل حاوية عامل إرساء مثبتة بالتبعيات المناسبة. سيتم تعيين مسار المضيف / إلى /host وسيتم تعيين دليل العمل الحالي إلى /workspace داخل الحاوية.
يدعم safe-rlhf مسارًا كاملاً بدءًا من الضبط الدقيق الخاضع للإشراف (SFT) وحتى تدريب النماذج المفضلة وحتى تدريب محاذاة RLHF.
conda activate safe-rlhf
export WANDB_API_KEY= " ... " # your W&B API key hereأو
make docker-run
export WANDB_API_KEY= " ... " # your W&B API key herebash scripts/sft.sh
--model_name_or_path < your-model-name-or-checkpoint-path >
--output_dir output/sftملاحظة: قد تحتاج إلى تحديث بعض المعلمات الموجودة في البرنامج النصي وفقًا لإعداد جهازك، مثل عدد وحدات معالجة الرسومات للتدريب وحجم دفعة التدريب وما إلى ذلك.
bash scripts/reward-model.sh
--model_name_or_path output/sft
--output_dir output/rmbash scripts/cost-model.sh
--model_name_or_path output/sft
--output_dir output/cmbash scripts/ppo.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--output_dir output/ppobash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagمثال على أوامر تشغيل المسار بالكامل باستخدام LLaMA-7B:
conda activate safe-rlhf
bash scripts/sft.sh --model_name_or_path ~ /models/llama-7b --output_dir output/sft
bash scripts/reward-model.sh --model_name_or_path output/sft --output_dir output/rm
bash scripts/cost-model.sh --model_name_or_path output/sft --output_dir output/cm
bash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagيتم اختبار جميع عمليات التدريب المذكورة أعلاه باستخدام LLaMA-7B على خادم سحابي مع 8 وحدات معالجة رسوميات NVIDIA A800-80GB.
يمكن للمستخدمين، الذين ليس لديهم ما يكفي من موارد ذاكرة وحدة معالجة الرسومات، تمكين DeepSpeed ZeRO-Offload للتخفيف من ذروة استخدام ذاكرة وحدة معالجة الرسومات.
يمكن لجميع البرامج النصية التدريبية المرور باستخدام خيار إضافي --offload (الإعداد الافتراضي هو none ، أي تعطيل ZeRO-Offload) لإلغاء تحميل الموترات (المعلمات و/أو حالات المحسن) إلى وحدة المعالجة المركزية. على سبيل المثال:
bash scripts/sft.sh
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft
--offload all # or `parameter` or `optimizer`بالنسبة لإعدادات العقد المتعددة، يمكن للمستخدمين الرجوع إلى DeepSpeed: وثائق تكوين الموارد (متعددة العقد) لمزيد من التفاصيل. فيما يلي مثال لبدء عملية التدريب على 4 عقد (تحتوي كل منها على 8 وحدات معالجة رسوميات):
# myhostfile
worker-1 slots=8
worker-2 slots=8
worker-3 slots=8
worker-4 slots=8
ثم قم بتشغيل البرامج النصية التدريبية باستخدام:
bash scripts/sft.sh
--hostfile myhostfile
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft يوفر safe-rlhf فكرة مجردة لإنشاء مجموعات بيانات لجميع مراحل الضبط الدقيق الخاضع للإشراف والتدريب على نموذج التفضيل ومراحل تدريب RL.
class RawSample ( TypedDict , total = False ):
"""Raw sample type.
For SupervisedDataset, should provide (input, answer) or (dialogue).
For PreferenceDataset, should provide (input, answer, other_answer, better).
For SafetyPreferenceDataset, should provide (input, answer, other_answer, safer, is_safe, is_other_safe).
For PromptOnlyDataset, should provide (input).
"""
# Texts
input : NotRequired [ str ] # either `input` or `dialogue` should be provided
"""User input text."""
answer : NotRequired [ str ]
"""Assistant answer text."""
other_answer : NotRequired [ str ]
"""Other assistant answer text via resampling."""
dialogue : NotRequired [ list [ str ]] # either `input` or `dialogue` should be provided
"""Dialogue history."""
# Flags
better : NotRequired [ bool ]
"""Whether ``answer`` is better than ``other_answer``."""
safer : NotRequired [ bool ]
"""Whether ``answer`` is safer than ``other_answer``."""
is_safe : NotRequired [ bool ]
"""Whether ``answer`` is safe."""
is_other_safe : NotRequired [ bool ]
"""Whether ``other_answer`` is safe."""فيما يلي مثال لتنفيذ مجموعة بيانات مخصصة (راجع Safe_rlhf/datasets/raw لمزيد من الأمثلة):
import argparse
from datasets import load_dataset
from safe_rlhf . datasets import RawDataset , RawSample , parse_dataset
class MyRawDataset ( RawDataset ):
NAME = 'my-dataset-name'
def __init__ ( self , path = None ) -> None :
# Load a dataset from Hugging Face
self . data = load_dataset ( path or 'my-organization/my-dataset' )[ 'train' ]
def __getitem__ ( self , index : int ) -> RawSample :
data = self . data [ index ]
# Construct a `RawSample` dictionary from your custom dataset item
return RawSample (
input = data [ 'col1' ],
answer = data [ 'col2' ],
other_answer = data [ 'col3' ],
better = float ( data [ 'col4' ]) > float ( data [ 'col5' ]),
...
)
def __len__ ( self ) -> int :
return len ( self . data ) # dataset size
def parse_arguments ():
parser = argparse . ArgumentParser (...)
parser . add_argument (
'--datasets' ,
type = parse_dataset ,
nargs = '+' ,
metavar = 'DATASET[:PROPORTION[:PATH]]' ,
)
...
return parser . parse_args ()
def main ():
args = parse_arguments ()
...
if __name__ == '__main__' :
main ()ثم يمكنك تمرير مجموعة البيانات هذه إلى البرامج النصية للتدريب على النحو التالي:
python3 train.py --datasets my-dataset-name يمكنك أيضًا تمرير مجموعات بيانات متعددة بنسب مجموعة بيانات إضافية اختياريًا (مفصولة بنقطتين : ). على سبيل المثال:
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5سيستخدم هذا تقسيمًا عشوائيًا بنسبة 75% من مجموعة بيانات Stanford Alpaca و50% من مجموعة البيانات المخصصة الخاصة بك.
بالإضافة إلى ذلك، يمكن أيضًا أن يتبع وسيطة مجموعة البيانات مسار محلي (مفصولاً بنقطتين : ) إذا كنت قد قمت بالفعل باستنساخ مستودع مجموعة البيانات من Hugging Face.
git lfs install
git clone https://huggingface.co/datasets/my-organization/my-dataset ~ /path/to/my-dataset/repository
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5: ~ /path/to/my-dataset/repositoryملاحظة: يجب استيراد فئة مجموعة البيانات قبل أن يبدأ البرنامج النصي للتدريب في تحليل وسيطات سطر الأوامر.
python3 -m safe_rlhf.serve.cli --model_name_or_path output/sft # or output/ppo-lagpython3 -m safe_rlhf.serve.arena --red_corner_model_name_or_path output/sft --blue_corner_model_name_or_path output/ppo-lag
لا يدعم خط أنابيب Safe-RLHF عائلة نماذج LLaMA فحسب، بل يدعم أيضًا النماذج الأخرى المدربة مسبقًا مثل Baichuan وInternLM وما إلى ذلك والتي تقدم دعمًا أفضل للصينيين. كل ما تحتاجه هو تحديث المسار إلى النموذج المُدرب مسبقًا في كود التدريب والاستدلال.
Safe-RLHF 管道不仅仅支持 LLaMA 系列模型،它也支持其他一些对中文支持更好的预训练模型،例如 Baichuan و المتدربLM .
# SFT training
bash scripts/sft.sh --model_name_or_path baichuan-inc/Baichuan-7B --output_dir output/baichuan-sft
# Inference
python3 -m safe_rlhf.serve.cli --model_name_or_path output/baichuan-sft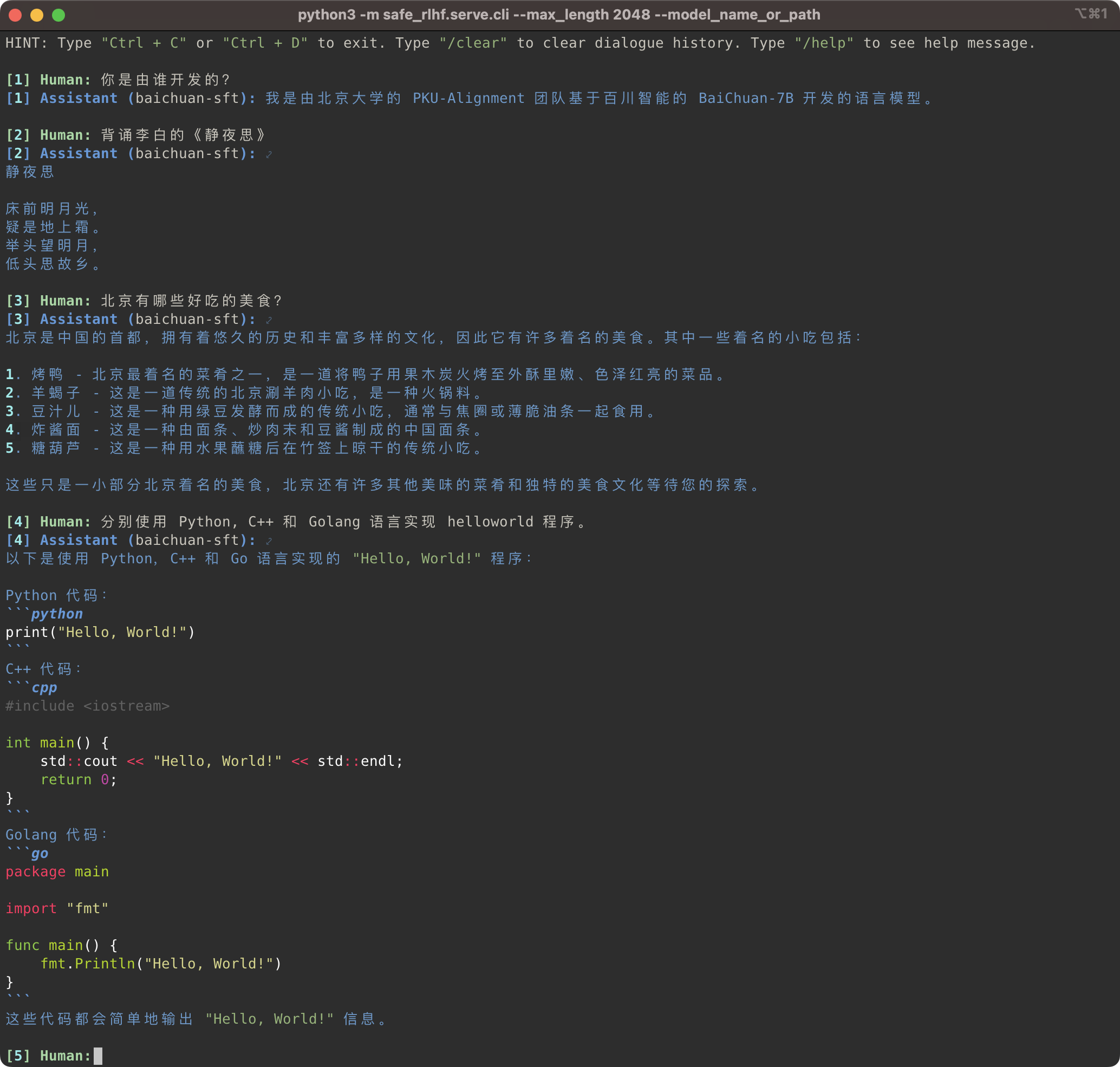
وفي غضون ذلك، أضفنا دعمًا لمجموعات البيانات الصينية مثل سلسلة Firefly وMOSS إلى مجموعات البيانات الأولية لدينا. ما عليك سوى تغيير مسار مجموعة البيانات في كود التدريب لاستخدام مجموعة البيانات المقابلة لضبط نموذج التدريب المسبق الصيني:
تم إنشاء مجموعات البيانات الأولية من خلال استخدام Firefly وMOSS يمكن أن تكون هذه هي المرة الأولى التي يحدث فيها هذا الأمر:
# scripts/sft.sh
- --train_datasets alpaca
+ --train_datasets firefly للحصول على تعليمات حول كيفية إضافة مجموعات بيانات مخصصة، يرجى الرجوع إلى قسم مجموعات البيانات المخصصة.
يمكنك إنشاء مجموعات بيانات مخصصة (تجميع البيانات المخصصة).
scripts/arena-evaluation.sh
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lag
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/arena-evaluation # Install BIG-bench
git clone https://github.com/google/BIG-bench.git
(
cd BIG-bench
python3 setup.py sdist
python3 -m pip install -e .
)
# BIG-bench evaluation
python3 -m safe_rlhf.evaluate.bigbench
--model_name_or_path output/ppo-lag
--task_name < BIG-bench-task-name > # Install OpenAI Python API
pip3 install openai
export OPENAI_API_KEY= " ... " # your OpenAI API key here
# GPT-4 evaluation
python3 -m safe_rlhf.evaluate.gpt4
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lagإذا وجدت Safe-RLHF مفيدًا أو استخدمت Safe-RLHF (النموذج، الكود، مجموعة البيانات، وما إلى ذلك) في بحثك، فيرجى التفكير في الاستشهاد بالعمل التالي في منشوراتك.
@inproceedings { safe-rlhf ,
title = { Safe RLHF: Safe Reinforcement Learning from Human Feedback } ,
author = { Josef Dai and Xuehai Pan and Ruiyang Sun and Jiaming Ji and Xinbo Xu and Mickel Liu and Yizhou Wang and Yaodong Yang } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=TyFrPOKYXw }
}
@inproceedings { beavertails ,
title = { BeaverTails: Towards Improved Safety Alignment of {LLM} via a Human-Preference Dataset } ,
author = { Jiaming Ji and Mickel Liu and Juntao Dai and Xuehai Pan and Chi Zhang and Ce Bian and Boyuan Chen and Ruiyang Sun and Yizhou Wang and Yaodong Yang } ,
booktitle = { Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track } ,
year = { 2023 } ,
url = { https://openreview.net/forum?id=g0QovXbFw3 }
}ساهم جميع الطلاب أدناه بالتساوي ويتم تحديد الترتيب أبجديًا:
كل ذلك نصح به Yizhou Wang و Yaodong Yang. شكر وتقدير: نحن نقدر السيدة Yi Qu لتصميمها شعار Beaver.
يستفيد هذا المستودع من LLaMA وStanford Alpaca وDeepSpeed وDeepSpeed-Chat. شكرًا لأعمالهم الرائعة وجهودهم من أجل إضفاء الطابع الديمقراطي على أبحاث LLM. تم إنشاء Safe-RLHF والأصول المرتبطة به ومفتوحة المصدر بالحب؟❤️.
يتم دعم هذا العمل وتمويله من قبل جامعة بكين.
 |  |
تم إصدار Safe-RLHF بموجب ترخيص Apache 2.0.


