spelltest
v0.0.4
؟ إذا وجدت هذا المشروع مفيدًا، فيرجى التفكير في منحه نجمة! دعمكم يحفزني على الاستمرار في تحسينه! ؟
تعتمد التطبيقات المعتمدة على الذكاء الاصطناعي اليوم إلى حد كبير على نماذج اللغات الكبيرة (LLMs) مثل GPT-4 لتقديم حلول مبتكرة. ومع ذلك، فإن ضمان تقديم استجابات مناسبة ودقيقة في كل موقف يمثل تحديًا. يعالج Spelltest هذه المشكلة من خلال محاكاة استجابات LLM باستخدام شخصيات مستخدم اصطناعية وتقنية تقييم لتقييم هذه الاستجابات تلقائيًا (ولكنها لا تزال تتطلب إشرافًا بشريًا).
spellforge.yaml : project_name : ...
# describe users
users :
...
# describe quality metrics
metrics :
...
# describe prompts of your LLM app
prompts :
...
# finally describe simulations
simulations :
...

يمكنك الآن تجربة هذا المشروع في بيئة تفاعلية على شبكة الإنترنت عبر Google Colab! لا يلزم التثبيت.
ما عليك سوى النقر على الشارة أعلاه للبدء!
الجودة المضمونة : محاكاة تفاعلات المستخدم للحصول على الاستجابات المثلى.
الكفاءة والتوفير : توفير تكاليف الاختبار اليدوي.
التكامل السلس لسير العمل : يتناسب بسلاسة مع عملية التطوير الخاصة بك.
يرجى العلم أن هذه نسخة مبكرة جدًا من Spelltest. وعلى هذا النحو، لم يتم اختباره على نطاق واسع حتى الآن في بيئات وحالات استخدام متنوعة. من خلال اتخاذ قرار باستخدام هذا الإصدار، فإنك تقبل أنك تستخدم إطار عمل Spelltest على مسؤوليتك الخاصة. نحن نشجع المستخدمين بشدة على الإبلاغ عن أي مشكلات أو أخطاء يواجهونها للمساعدة في تحسين المشروع.
فيما يتعلق بالتكاليف التشغيلية، من المهم ملاحظة أن تشغيل عمليات المحاكاة باستخدام Spelltest يفرض رسومًا بناءً على استخدام OpenAI API. لا توجد تقديرات للتكلفة أو حد للميزانية في الوقت الحالي. بالنسبة للسياق، قد يكلف تشغيل مجموعة مكونة من 100 عملية محاكاة ما يقرب من 0.7 دولارًا إلى 1.8 دولارًا (gpt-3.5-turbo)، اعتمادًا على عدة عوامل بما في ذلك ماجستير إدارة الأعمال المحدد وتعقيد عمليات المحاكاة.
ونظرًا لهذه التكاليف، نوصي بشدة بالبدء بعدد أقل من عمليات المحاكاة للحفاظ على انخفاض التكاليف الأولية ومساعدتك في تقدير النفقات المستقبلية بشكل أفضل. عندما تصبح أكثر دراية بإطار العمل وتأثيراته من حيث التكلفة، يمكنك ضبط عدد عمليات المحاكاة وفقًا لميزانيتك واحتياجاتك.
تذكر أن هدف Spelltest هو ضمان استجابات عالية الجودة من LLMs مع الحفاظ على فعالية التكلفة قدر الإمكان في عملية تطوير الذكاء الاصطناعي واختباره.

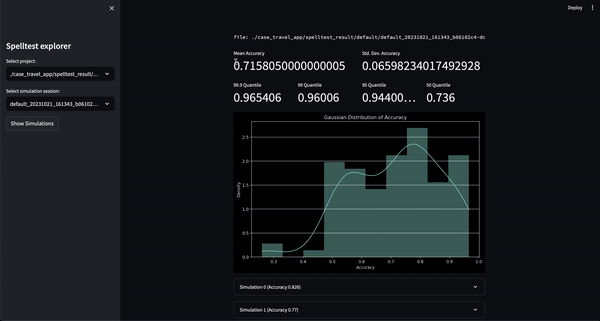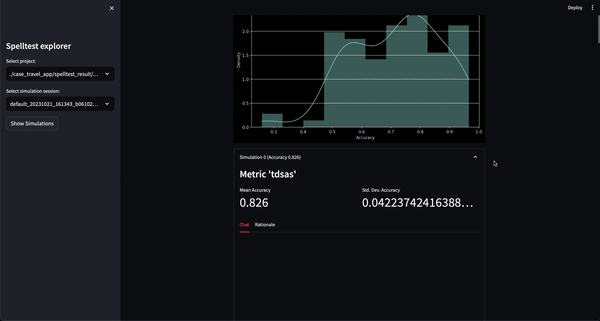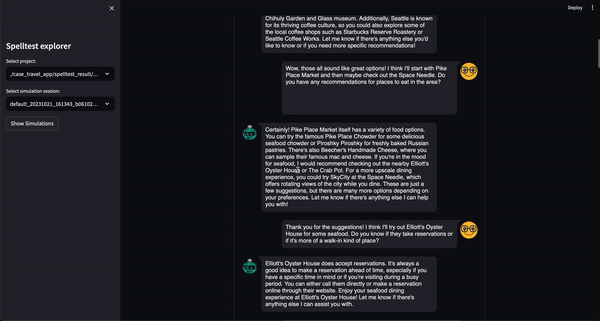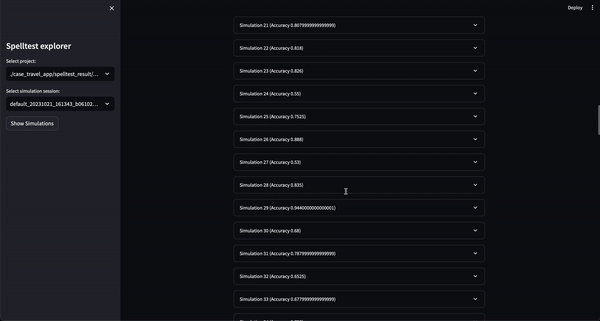
يأخذ Spelltest منهجًا مميزًا لضمان الجودة. باستخدام شخصيات المستخدم الاصطناعية، لا نقوم بمحاكاة التفاعلات فحسب، بل نلتقط أيضًا توقعات المستخدم الفريدة، مما يوفر بيئة غنية بالسياق للاختبار. يتيح لنا عمق السياق هذا تقييم جودة استجابات LLM بطريقة تعكس بشكل وثيق تطبيقات العالم الحقيقي.
النتيجة؟ تتراوح نقاط الجودة من 0.0 إلى 1.0، وتكون بمثابة بروفة شاملة قبل أن يصل تطبيقك إلى مستخدميه الحقيقيين. سواء في وضع الدردشة أو الإكمال، يضمن Spelltest أن استجابات LLM تتوافق بشكل وثيق مع توقعات المستخدم، مما يعزز رضا المستخدم بشكل عام.
تثبيت الإطار باستخدام النقطة:
pip install spelltest يعتبر .spellforge.yaml أساسيًا في Spelltest، حيث يحتوي على ملفات تعريف مستخدمين ومقاييس ومطالبات وعمليات محاكاة. وفيما يلي تفصيل لهيكلها:
يحاكي المستخدمون الاصطناعيون مستخدمي العالم الحقيقي، ولكل منهم خلفية فريدة وتوقعات وفهم للتطبيق. يتضمن التكوين للمستخدمين الاصطناعيين ما يلي:
المطالبات الفرعية : هذه عناصر وصفية توفر سياقًا لملف تعريف المستخدم. وهي تشمل:
description : نبذة عن المستخدم الاصطناعي.expectation : ما يتوقعه المستخدم من التفاعل.user_knowledge_about_app : مستوى الإلمام بالتطبيق.كل مستخدم اصطناعي لديه أيضًا:
name : معرف المستخدم الاصطناعي.llm_name : نماذج LLM المطلوب استخدامها (تم اختبارها على نماذج OpenAI فقط).temperature : ...مثال لتكوين المستخدم الاصطناعي:
...
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
... يتم استخدام المقاييس لتقييم وتسجيل استجابات LLM. يحتوي كل مقياس على description موجه فرعي يوفر سياقًا لما يقيمه المقياس.
مثال على التكوين المتري البسيط:
...
metrics :
accuracy :
description : " Accuracy "
...مثال على تكوين المقياس المعقد/المخصص:
...
metrics :
tpas :
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
... المطالبات هي أسئلة أو مهام يطرحها التطبيق. يتم استخدامها في عمليات المحاكاة لاختبار قدرة LLM على توليد استجابات مناسبة. يتم تعريف كل مطالبة description ونص أو مهمة prompt الفعلية.
...
prompts :
book_flight :
file : book-flight-prompt.txt
... تحدد عمليات المحاكاة سيناريو الاختبار. تتضمن العناصر الأساسية prompt users llm_name temperature size chat_mode وعتبة quality_threshold .
project_name : " Travel schedule app "
# describe users
users :
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
family_weekend :
name : " The Adventurous Family from Chicago "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a family of four (two adults and two children) based in Chicago looking to plan an exciting, yet relaxed weekend getaway outside the city. The objective is to explore a new environment that is kid-friendly and offers a mix of adventure and downtime. "
expectation : " A balanced travel schedule that combines fun activities suitable for children and relaxation opportunities for the entire family, considering travel times and kid-friendly amenities. "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
retired_couple :
name : " Retired Couple Exploring Berlin "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a retired couple from the US, wanting to explore Berlin and soak in its rich history and culture over a 10-day vacation. You’re looking for a mixture of sightseeing, cultural experiences, and leisure activities, with a comfortable pace suitable for your age. "
expectation : " A comprehensive travel plan that provides a relaxed pace, ensuring enough time to explore and enjoy each location, and includes historical and cultural experiences. It should also consider comfort and accessibility. "
user_knowledge_about_app : " The app accepts text input detailing travel requirements (i.e., destination, preferences, duration, and a brief description of travelers) and returns a well-organized travel itinerary tailored to those specifics. "
metrics : __all__
# describe quality metrics
metrics :
tpas : # name of your metric
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
# describe prompts
prompts :
smart-prompt :
file : ./smart-prompt # expected that prompt located in this file
# finally describe simulations
simulations :
test1 :
prompt : smart-prompt
users : __all__
llm_name : gpt-3.5-turbo
temperature : 0.7
size : 5
chat_mode : true # completion mode if `false`
quality_threshold : 80
التكوين الكامل مع الملفات السريعة هنا.
تكاليف OpenAI : يمكن أن يؤدي استخدام إطار العمل هذا إلى عدد كبير من الطلبات إلى OpenAI، خاصة عند إجراء عمليات محاكاة واسعة النطاق. يمكن أن يؤدي ذلك إلى تكاليف كبيرة على حساب OpenAI الخاص بك. تأكد من أنك على دراية بميزانية OpenAI الخاصة بك وفهم نموذج التسعير. أنا لا أتحمل أي مسؤولية عن أي نفقات متكبدة.
الإصدار المبكر : لا يزال هذا الإصدار من Spelltest في مراحله الأولى وليس له أي ضمانات للاستقرار. يرجى استخدامه بحذر ولا تتردد في تقديم تعليقات أو الإبلاغ عن المشكلات.
export OPENAI_API_KEYS= < your api keys >
spelltest --config_file .spellforge.yamlالتحقق من نتائج المحاكاة.
spelltest --analyzeيؤدي دمج Spelltest في مسار الإصدار الخاص بك إلى تحسين إستراتيجية النشر لديك من خلال دمج اختبار تلقائي متسق. تضمن هذه الخطوة الحاسمة أن تحافظ تطبيقاتك المستندة إلى LLM على مستوى عالٍ من الجودة من خلال محاكاة تفاعلات المستخدم وتقييمها بشكل منهجي قبل أي إصدار. يمكن أن توفر هذه الممارسة وقتًا كبيرًا، وتقلل من الأخطاء اليدوية، وتوفر رؤى أساسية حول كيفية تأثير التغييرات أو الميزات الجديدة على تجربة المستخدم.
سيرشدك هذا الدليل خلال عملية إعداد وأتمتة التكامل المستمر لمشاريعك.
قبل البدء، تأكد من توفر المتطلبات الأساسية التالية:
مستودع GitHub يحتوي على مشروعك.
الوصول إلى SpellForge باستخدام مفتاح API. إذا لم يكن لديك واحد، يمكنك الحصول عليه من موقع SpellForge.
مفتاح OpenAI API لاستخدام خدمات OpenAI. إذا لم يكن لديك واحد، يمكنك الحصول عليه من موقع OpenAI.
.spellforge.yaml قم بإنشاء ملف .spellforge.yaml في الدليل الجذر لمشروعك. سيحتوي هذا الملف على تعليمات Spelltest.
قم بإنشاء ملف سير عمل GitHub Actions، على سبيل المثال، .github/workflows/.spelltest.yaml، لأتمتة اختبار SpellForge. أدخل الكود التالي في هذا الملف:
# .spelltest.yaml
name : Spelltest CI
on :
push :
branches : [ "main" ]
env :
SPELLTEST_CONFIG_PATH : ${{ env.SPELLTEST_CONFIG_PATH }}
OPENAI_API_KEY : ${{ secrets.OPENAI_API_KEY }}
jobs :
test :
runs-on : ubuntu-latest
steps :
- uses : actions/checkout@v3
- name : Install SpellTest library
run : pip install spelltest
- name : Run tests
run : spelltest --config_file $SPELLTEST_CONFIG_PATHيتم تشغيل سير العمل هذا عند كل دفعة إلى الفرع الرئيسي وسيتم تشغيل اختبارات SpellForge الخاصة بك.
انتقل إلى مستودع GitHub الخاص بك وانتقل إلى علامة التبويب "الإعدادات".
ضمن "الأسرار" أضف سرين جديدين:
OPENAI_API_KEY : قم بتعيين هذا السر على مفتاح OpenAI API الخاص بك.
أضف متغير بيئة GitHub:
SPELLTEST_CONFIG_PATH : قم بتعيين هذا المتغير على المسار الكامل لملف .spellforge.yaml الخاص بك داخل المستودع الخاص بك.
وهي تحاكي تفاعلات المستخدم الحقيقي بخصائص وتوقعات محددة.
خلفية المستخدم (حقل description في .spellforge.yaml ): موجه فرعي يوفر نظرة عامة حول هوية هذا المستخدم الاصطناعي والمشكلات التي يريد حلها باستخدام التطبيق، على سبيل المثال، مسافر يدير جدوله الزمني.
توقعات المستخدم (حقل expectation ): موجه فرعي يحدد ما يتوقعه المستخدم الاصطناعي كتفاعل أو حل ناجح من استخدام التطبيق.
الوعي البيئي (حقل user_knowledge_about_app ): موجه فرعي يضمن فهم المستخدم الاصطناعي لسياق التطبيق، مما يضمن سيناريوهات اختبار واقعية.
موجه فرعي يمثل المعايير أو المعايير المستخدمة لتقييم وتسجيل الاستجابات الناتجة عن LLM في عمليات المحاكاة. يمكن أن تتراوح المقاييس من القياسات العامة إلى المقاييس المخصصة الأكثر تحديدًا للتطبيق.
أمثلة مترية عامة:
التشابه الدلالي : يقيس مدى قرب الإجابة المقدمة من الإجابة المتوقعة من حيث المعنى.
السمية : يقيم الاستجابة لأي لغة أو محتوى يمكن اعتباره غير مناسب أو ضار.
التشابه الهيكلي : يقارن هيكل وشكل الاستجابة التي تم إنشاؤها بمعيار محدد مسبقًا أو مخرجات متوقعة.
المزيد من أمثلة المقاييس المخصصة:
TPAS (درجة دقة خطة السفر) : "يقيس هذا المقياس دقة الاستجابة الناتجة من خلال تقييم تضمين المخرجات المتوقعة وجودة خطة السفر المقترحة. TPAS هي قيمة عددية تتراوح بين 0 و100، حيث تمثل 100 نتيجة مثالية يتطابق مع المخرجات المتوقعة ويشير 0 إلى نتيجة غير دقيقة."
EES (درجة مشاركة التعاطف) : "تقوم EES بتقييم الصدى التعاطفي لاستجابات LLM. من خلال تقييم الفهم والتحقق والعناصر الداعمة في الرسالة، فإنها تسجل مستوى التعاطف المنقول. وتتراوح EES من 0 إلى 100، حيث تشير 100 إلى أ استجابة متعاطفة للغاية، بينما يشير الرقم 0 إلى عدم وجود مشاركة متعاطفة."
اجعل طلبك المستند إلى LLM أفضل باستخدام Spelltest!


