datablations
1.0.0
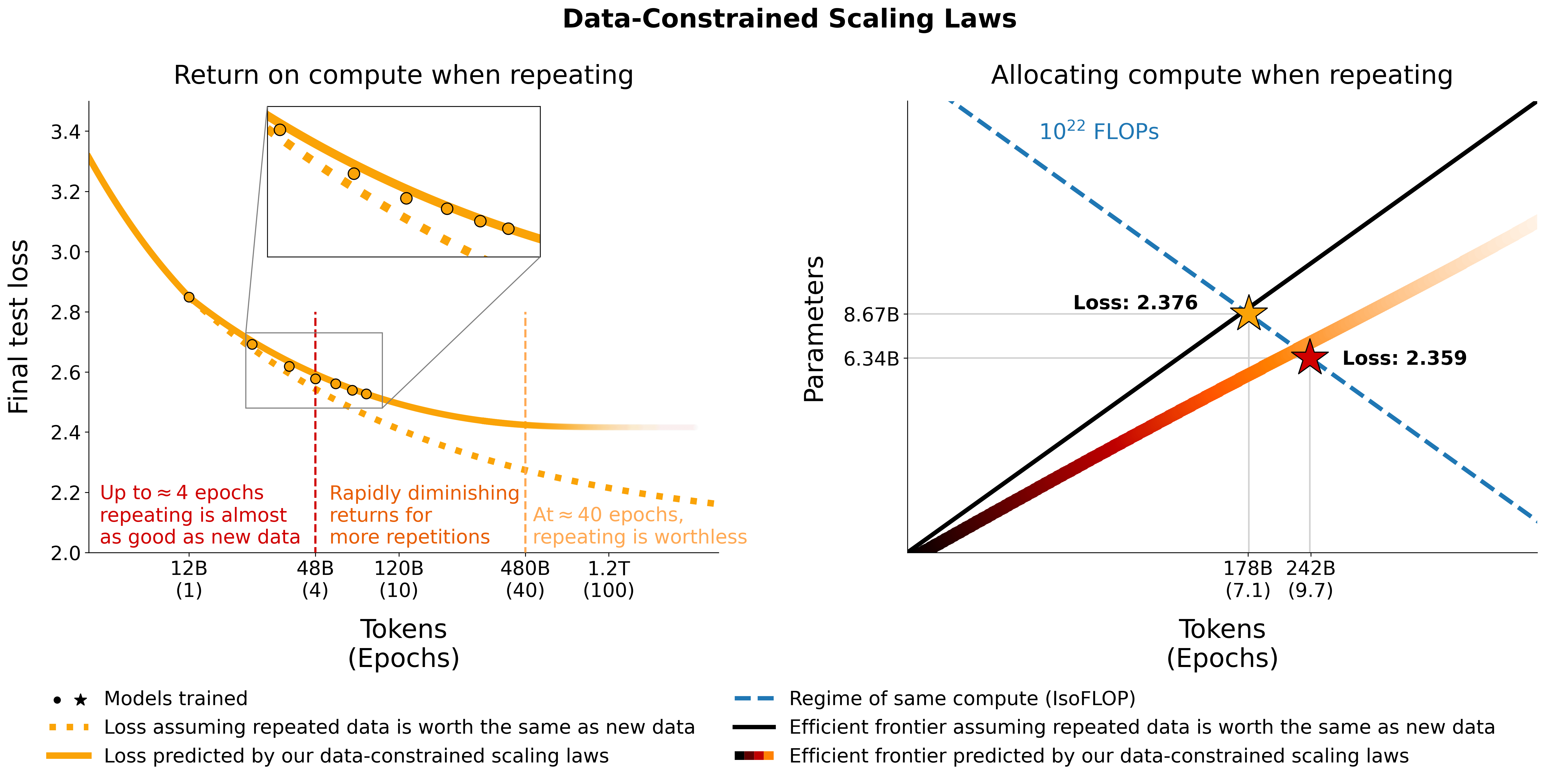
يوفر هذا المستودع نظرة عامة على جميع المكونات من ورقة قياس نماذج اللغة المقيدة بالبيانات. أحاديث على الورق:
نحن نحقق في توسيع نطاق نماذج اللغة في الأنظمة المحدودة البيانات. نحن نجري مجموعة كبيرة من التجارب التي تتنوع في مدى تكرار البيانات وميزانية الحوسبة، والتي تتراوح ما يصل إلى 900 مليار رمز تدريبي و9 مليار نموذج معلمات. استنادًا إلى عمليات التشغيل التي قمنا بها، نقترح ونتحقق من صحة تجريبيًا لقانون القياس من أجل تحسين الحساب الذي يأخذ في الاعتبار القيمة المتناقصة للرموز المميزة المتكررة والمعلمات الزائدة. نقوم أيضًا بتجربة أساليب التخفيف من ندرة البيانات، بما في ذلك زيادة مجموعة بيانات التدريب ببيانات التعليمات البرمجية وتصفية الحيرة وإلغاء البيانات المكررة. النماذج ومجموعات البيانات من دوراتنا التدريبية البالغ عددها 400 متاحة عبر هذا المستودع.
نحن نجرب تكرار البيانات على C4 والتقسيم الإنجليزي غير المكرر لـ OSCAR. بالنسبة لكل مجموعة بيانات، نقوم بتنزيل البيانات وتحويلها إلى ملف jsonl واحد، c4.jsonl و oscar_en.jsonl على التوالي.
ثم نقرر مقدار الرموز الفريدة وعدد العينات التي نحتاجها من مجموعة البيانات. لاحظ أن C4 يحتوي على 478.625834583 رمزًا مميزًا لكل عينة وأن OSCAR يحتوي على 1312.0951072 مع GPT2Tokenizer. تم حساب ذلك عن طريق ترميز مجموعة البيانات بأكملها وتقسيم عدد الرموز المميزة على عدد العينات. نستخدم هذه الأرقام لحساب العينات المطلوبة.
على سبيل المثال، بالنسبة لـ 1.9B من الرموز الفريدة، نحتاج إلى 1.9B / 478.625834583 = 3969697.96178 عينة لـ C4 و 1.9B / 1312.0951072 = 1448065.76107 عينة لـ OSCAR. لترميز البيانات، نحتاج أولاً إلى استنساخ مستودع Megatron-DeepSpeed واتباع دليل الإعداد الخاص به. ثم نختار هذه العينات ونقوم بترميزها على النحو التالي:
ج4:
head -n 3969698 c4.jsonl > c4_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4_1b9.jsonl
--output-prefix gpt2tok_c4_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64أوسكار:
head -n 1448066 oscar_en.jsonl > oscar_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input oscar_1b9.jsonl
--output-prefix gpt2tok_oscar_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64 حيث يشير gpt2 إلى مجلد يحتوي على جميع الملفات من https://huggingface.co/gpt2/tree/main. باستخدام head ، نتأكد من أن المجموعات الفرعية المختلفة سيكون لها عينات متداخلة لتقليل العشوائية.
للتقييم أثناء التدريب والتقييم النهائي، نستخدم مجموعة التحقق من الصحة لـ C4:
from datasets import load_dataset
load_dataset ( "c4" , "en" , split = "validation" ). to_json ( "c4-en-validation.json" )python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4-en-validation.jsonl
--output-prefix gpt2tok_c4validation_rerun
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 2 بالنسبة لـ OSCAR الذي لا يحتوي على مجموعة تحقق رسمية، فإننا نأخذ جزءًا من مجموعة التدريب عن طريق عمل tail -364608 oscar_en.jsonl > oscarvalidation.jsonl ثم نقوم بترميزها على النحو التالي:
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py --input oscarvalidation.jsonl --output-prefix gpt2tok_oscarvalidation --dataset-impl mmap --tokenizer-type PretrainedFromHF --tokenizer-name-or-path gpt2 --append-eod --workers 2لقد قمنا بتحميل العديد من المجموعات الفرعية المُجهزة مسبقًا للاستخدام مع ميجاترون:
كانت بعض ملفات bin كبيرة جدًا بالنسبة إلى git، وبالتالي تم تقسيمها باستخدام، على سبيل المثال split --number=l/40 gpt2tok_c4_en_1B9.bin gpt2tok_c4_en_1B9.bin. split --number=l/40 gpt2tok_oscar_en_1B9.bin gpt2tok_oscar_en_1B9.bin. . لاستخدامها في التدريب، يجب عليك تجميعها معًا مرة أخرى باستخدام cat gpt2tok_c4_en_1B9.bin.* > gpt2tok_c4_en_1B9.bin و cat gpt2tok_oscar_en_1B9.bin.* > gpt2tok_oscar_en_1B9.bin .
لقد قمنا بتجربة خلط التعليمات البرمجية مع بيانات اللغة الطبيعية باستخدام تقسيم Python من the-stack-dedup. نقوم بتنزيل البيانات وتحويلها إلى ملف jsonl واحد ومعالجتها مسبقًا باستخدام نفس الطريقة الموضحة أعلاه.
لقد قمنا بتحميل النسخة المعالجة مسبقًا للاستخدام مع ميجاترون هنا: https://huggingface.co/datasets/datablations/python-megatron. لقد قمنا بتقسيم ملف السلة باستخدام split --number=l/40 gpt2tok_python_content_document.bin gpt2tok_python_content_document.bin. ، لذلك تحتاج إلى جمعهما معًا مرة أخرى باستخدام cat gpt2tok_python_content_document.bin.* > gpt2tok_python_content_document.bin للتدريب.
نقوم بإنشاء إصدارات من C4 وOSCAR مع بيانات تعريف التصفية المرتبطة بالحيرة وإلغاء البيانات المكررة:
لإعادة إنشاء مجموعات بيانات التعريف هذه، توجد تعليمات على filtering/README.md .
نحن نقدم الإصدارات المميزة التي يمكن استخدامها للتدريب مع Megatron على:
تم تقسيم ملفات .bin باستخدام شيء مثل split --number=l/10 gpt2tok_oscar_en_perplexity_25_text_document.bin gpt2tok_oscar_en_perplexity_25_text_document.bin. ، لذلك تحتاج إلى تسلسلها معًا مرة أخرى عبر cat gpt2tok_oscar_en_perplexity_25_text_document.bin. > gpt2tok_oscar_en_perplexity_25_text_document.bin .
لإعادة إنشاء الإصدارات المميزة في ضوء مجموعة بيانات التعريف،
filtering/deduplication/filter_oscar_jsonl.pyلإنشاء النسب المئوية للحيرة، اتبع الإرشادات التالية.
ج4:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-filter" , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity" ], 50 )
p_75 = np . percentile ( ds [ "train" ][ "perplexity" ], 75 )
# 25 - 75th percentile
ds [ "train" ]. filter ( lambda x : p_25 < x [ "perplexity" ] < p_75 , num_proc = 128 ). to_json ( "c4_perplexty2575.jsonl" , num_proc = 128 , force_ascii = False )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_25 , num_proc = 128 ). to_json ( "c4_perplexty25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_50 , num_proc = 128 ). to_json ( "c4_perplexty50.jsonl" , num_proc = 128 , force_ascii = False )أوسكار:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/oscar-filter" , use_auth_token = True , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 50 )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_25 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_50 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity50.jsonl" , num_proc = 128 , force_ascii = False )يمكنك بعد ذلك ترميز ملفات jsonl الناتجة للتدريب باستخدام Megatron كما هو موضح في قسم التكرار.
C4: بالنسبة لـ C4، تحتاج فقط إلى إزالة كافة العينات حيث يتم ملء حقل repetitions ، عبر على سبيل المثال
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-dedup" , use_auth_token = True , streaming = False , num_proc = 128 )
ds . filter ( lambda x : not ( x [ "repetitions" ]). to_json ( 'c4_dedup.jsonl' , num_proc = 128 , force_ascii = False ) OSCAR: بالنسبة إلى OSCAR، نقدم برنامجًا نصيًا على filtering/filter_oscar_jsonl.py لإنشاء مجموعة البيانات المكررة في ضوء مجموعة البيانات مع تصفية البيانات الوصفية.
يمكنك بعد ذلك ترميز ملفات jsonl الناتجة للتدريب باستخدام Megatron كما هو موضح في قسم التكرار.
يمكن تنزيل جميع النماذج على https://huggingface.co/datablations.
تتم تسمية النماذج بشكل عام على النحو التالي: lm1-{parameters}-{tokens}-{unique_tokens} ، ويتم تسمية النماذج الفردية في المجلدات على وجه التحديد على النحو التالي: {parameters}{tokens}{unique_tokens}{optional specifier} ، على سبيل المثال 1b12b8100m سيكون 1.1 مليار بارامز، 2.8 مليار رمز، 100 مليون رمز مميز. تقدم اتفاقية xby ( 1b1 , 2b8 وما إلى ذلك) بعض الغموض فيما إذا كانت الأرقام تنتمي إلى معلمات أو رموز مميزة، ولكن يمكنك دائمًا التحقق من البرنامج النصي العشوائي في المجلد المعني لرؤية المعلمات / الرموز المميزة / الرموز المميزة الدقيقة. إذا كنت تريد تحويل النماذج التي لم يتم تحويلها بعد إلى huggingface/transformers ، فيمكنك اتباع الإرشادات الموجودة في التدريب.
أسهل طريقة لتنزيل نموذج واحد هي على سبيل المثال:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datablations/lm1-misc
cd lm1-misc ; git lfs pull --include 146m14b400m/global_step21553 إذا استغرق ذلك وقتًا طويلاً، فيمكنك أيضًا استخدام wget لتنزيل الملفات الفردية مباشرة من المجلد، على سبيل المثال:
wget https://huggingface.co/datablations/lm1-misc/resolve/main/146m14b400m/global_step21553/bf16_zero_pp_rank_0_mp_rank_00_optim_states.ptللحصول على النماذج المقابلة للتجارب في الورقة، راجع المستودعات التالية:
lm1-misc/*dedup* لمقارنة إلغاء البيانات المكررة على 100 مليون رمز فريد في الملحقنماذج أخرى لم يتم تحليلها في الورقة:
نقوم بتدريب النماذج باستخدام شوكة Megatron-DeepSpeed التي تعمل مع وحدات معالجة الرسومات AMD (عبر ROCm): https://github.com/TurkuNLP/Megatron-DeepSpeed إذا كنت ترغب في استخدام وحدات معالجة الرسومات NVIDIA (عبر cuda)، يمكنك استخدام المكتبة الأصلية: https://github.com/bigscience-workshop/Megatron-DeepSpeed
يتعين عليك اتباع تعليمات الإعداد الخاصة بأي من المستودعين لإنشاء بيئتك (تم تفصيل الإعداد الخاص بـ LUMI في training/megdssetup.md ).
يحتوي كل مجلد نموذج على برنامج نصي متقطع تم استخدامه لتدريب النموذج. يمكنك استخدامها كمرجع لتدريب نماذجك الخاصة على التكيف مع متغيرات البيئة الضرورية. تشير البرامج النصية المجمعة إلى بعض الملفات الإضافية:
*txt التي تحدد مسارات البيانات. يمكنك العثور عليها على utils/datapaths/* ، ومع ذلك، ستحتاج على الأرجح إلى تعديل المسار للإشارة إلى مجموعة البيانات الخاصة بك.model_params.sh الموجود في utils/model_params.sh ويحتوي على إعدادات مسبقة للهندسة المعمارية.launch.sh الذي يمكنك العثور عليه في training/launch.sh . فهو يحتوي على أوامر خاصة بالإعداد لدينا، والتي قد ترغب في إزالتها. بعد التدريب، يمكنك تحويل النموذج الخاص بك إلى محولات باستخدام، على سبيل المثال، python Megatron-DeepSpeed/tools/convert_checkpoint/deepspeed_to_transformers.py --input_folder global_step52452 --output_folder transformers --target_tp 1 --target_pp 1 .
بالنسبة للنماذج المتكررة، نقوم أيضًا بتحميل لوحات الشد الخاصة بها بعد التدريب باستخدام، على سبيل المثال tensorboard dev upload --logdir tensorboard_8b7178b88boscar --name "tensorboard_8b7178b88boscar" ، مما يجعلها سهلة الاستخدام للتصور في الورقة.
بالنسبة لاستئصال muP الموجود في الملحق، نستخدم البرنامج النصي الموجود على training_scripts/mup.py . أنه يحتوي على تعليمات الإعداد.
يمكنك استخدام صيغتنا لحساب الخسارة المتوقعة في ضوء المعلمات والبيانات والرموز الفريدة على النحو التالي:
import numpy as np
func = r"$L(N,D,R_N,R_D)=E + frac{A}{(U_N + U_N * R_N^* * (1 - e^{(-1*R_N/(R_N^*))}))^alpha} + frac{B}{(U_D + U_D * R_D^* * (1 - e^{(-1*R_D/(R_D^*))}))^beta}$"
a , b , e , alpha , beta , rd_star , rn_star = [ 6.255414 , 7.3049974 , 0.6254804 , 0.3526596 , 0.3526596 , 15.387756 , 5.309743 ]
A = np . exp ( a )
B = np . exp ( b )
E = np . exp ( e )
G = (( alpha * A ) / ( beta * B )) ** ( 1 / ( alpha + beta ))
def D_to_N ( D ):
return ( D * G ) ** ( beta / alpha ) * G
def scaling_law ( N , D , U ):
"""
N: number of parameters
D: number of total training tokens
U: number of unique training tokens
"""
assert U <= D , "Cannot have more unique tokens than total tokens"
RD = np . maximum (( D / U ) - 1 , 0 )
UN = np . minimum ( N , D_to_N ( U ))
RN = np . maximum (( N / UN ) - 1 , 0 )
L = E + A / ( UN + UN * rn_star * ( 1 - np . exp ( - 1 * RN / rn_star ))) ** alpha + B / ( U + U * rd_star * ( 1 - np . exp ( - 1 * RD / ( rd_star )))) ** beta
return L
# Models in Figure 1 (right):
print ( scaling_law ( 6.34e9 , 242e9 , 25e9 )) # 2.2256440889984477 # <- This one is better
print ( scaling_law ( 8.67e9 , 178e9 , 25e9 )) # 2.2269634075087867لاحظ أنه من غير المرجح أن تكون قيمة الخسارة الفعلية مفيدة، بل اتجاه الخسارة، على سبيل المثال، زيادة عدد المعلمات أو لمقارنة نموذجين كما في المثال أعلاه. لحساب التخصيص الأمثل، يمكنك استخدام بحث شبكة بسيط:
def chinchilla_optimal_N ( C ):
a = ( beta ) / ( alpha + beta )
N_opt = G * ( C / 6 ) ** a
return N_opt
def chinchilla_optimal_D ( C ):
b = ( alpha ) / ( alpha + beta )
D_opt = ( 1 / G ) * ( C / 6 ) ** b
return D_opt
def optimal_allocation ( C , U_BASE ):
"""Compute optimal number of parameters and tokens to train for given a compute & unique data budget"""
N_BASE = chinchilla_optimal_N ( C )
D_BASE = chinchilla_optimal_D ( C )
min_l = float ( "inf" )
for i in np . linspace ( 1.0001 , 3 , 500 ):
D = D_BASE * i
U = min ( U_BASE , D )
N = N_BASE / i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
D = D_BASE / i
U = min ( U_BASE , D )
N = N_BASE * i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
return min_l , min_t , min_s
_ , min_t , min_s = optimal_allocation ( 10 ** 22 , 25e9 )
print ( f"Optimal configuration: { min_t } tokens, { min_t / 25e9 } epochs, { min_s } parameters" )
# -> 237336955477.55075 tokens, 9.49347821910203 epochs, 7022364735.879969 parameters
# We went more extreme in Figure 1 to really put our prediction of "many epochs, fewer params" to the test إذا قمت باشتقاق تعبير مغلق للتخصيص الأمثل بدلاً من بحث الشبكة أعلاه، فيرجى إخبارنا :) نحن نلائم قوانين القياس المقيدة بالبيانات ومعاملات القياس C4 باستخدام الكود الموجود في utils/parametric_fit.ipynb المكافئ لهذا colab .
Training > Regular models لإعداد بيئة التدريب.pip install git+https://github.com/EleutherAI/lm-evaluation-harness.git . لقد استخدمنا الإصدار 0.2.0، ولكن الإصدارات الأحدث يجب أن تعمل أيضًا.sbatch utils/eval_rank.sh لتعديل المتغيرات الضرورية في البرنامج النصي أولاًpython Megatron-DeepSpeed/tasks/eval_harness/report-to-csv.py outfile.jsonaddtasks من أداة التقييم: git clone -b addtasks https://github.com/Muennighoff/lm-evaluation-harness.gitcd lm-evaluation-harness; pip install -e ".[dev]"; pip uninstall -y promptsource; pip install git+https://github.com/Muennighoff/promptsource.git@tr13 أي جميع المتطلبات باستثناء Promptsource، الذي يتم تثبيته من شوكة مع المطالبات الصحيحةsbatch utils/eval_generative.sh لتعديل المتغيرات الضرورية في البرنامج النصي أولاًpython utils/merge_generative.py ثم نقوم بتحويلها إلى csv باستخدام python utils/csv_generative.py merged.jsonbabi من أداة التقييم: git clone -b babi https://github.com/Muennighoff/lm-evaluation-harness.git (لاحظ أن هذا الفرع غير متوافق مع فرع addtasks للمهام التوليدية لأنه ينبع من EleutherAI/lm-evaluation-harness ، بينما تعتمد addtasks على bigscience/lm-evaluation-harness )cd lm-evaluation-harness; pip install -e ".[dev]"sbatch utils/eval_babi.sh لتعديل المتغيرات الضرورية في البرنامج النصي أولاً plotstables/return_alloc.pdf ، plotstables/return_alloc.ipynb ،colabplotstables/dataset_setup.pdf و plotstables/dataset_setup.ipynb وcolabplotstables/contours.pdf و plotstables/contours.ipynb وcolabplotstables/isoflops_training.pdf ، plotstables/isoflops_training.ipynb ،colabplotstables/return.pdf ، plotstables/return.ipynb ،colabplotstables/strategies.pdf ، plotstables/strategies.drawioplotstables/beyond.pdf ، plotstables/beyond.ipynb ،colabplotstables/cartoon.pdf ، plotstables/cartoon.pptxplotstables/isoloss_400m1b5.pdf ونفس الكولاب الموجود في الشكل 3plotstables/mup.pdf ، plotstables/dd.pdf ، plotstables/dedup.pdf ، plotstables/mup_dd_dd.ipynb ،colabplotstables/isoloss_alphabeta_100m.pdf ونفس الكولاب الموجود في الشكل 3plotstables/galactica.pdf و plotstables/galactica.ipynb وcolabtraining_c4.pdf و validation_c4oscar.pdf و training_oscar.pdf و validation_epochs_c4oscar.pdf ونفس colab كما في الشكل 4plotstables/perplexity_histogram.pdf ، plotstables/perplexity_histogram.ipynbplotstabls/validation_c4py.pdf و plotstables/training_validation_filter.pdf و plotstables/beyond_losses.ipynb وcolabutils/parametric_fit.ipynb المكافئة لهذا الكولاب.plotstables/repetition.ipynb & colabplotstables/python.ipynb & colabplotstables/filtering.ipynb & colabجميع النماذج والأكواد مرخصة بموجب Apache 2.0. يتم إصدار مجموعات البيانات التي تمت تصفيتها بنفس ترخيص مجموعات البيانات التي تنبع منها.
@article { muennighoff2023scaling ,
title = { Scaling Data-Constrained Language Models } ,
author = { Muennighoff, Niklas and Rush, Alexander M and Barak, Boaz and Scao, Teven Le and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin } ,
journal = { arXiv preprint arXiv:2305.16264 } ,
year = { 2023 }
}

