paperchat
1.0.0
مرحبًا بك في arXivchat!
arXivchat هو برنامج قائم على LLM ويتيح لك التحدث عن أوراق arXiv المنشورة بطريقة محادثة. وهي تعمل كأداة cli وموفر واجهة برمجة التطبيقات (API) ومكون إضافي ChatGPT.
مصنوعة من قبل مشغلي الأمام. نحن نعمل مع بعض من أذكى الأشخاص في المشاريع ذات الصلة بـ LLM وتعلم الآلة.
أنت أكثر من موضع ترحيب للمساهمة!
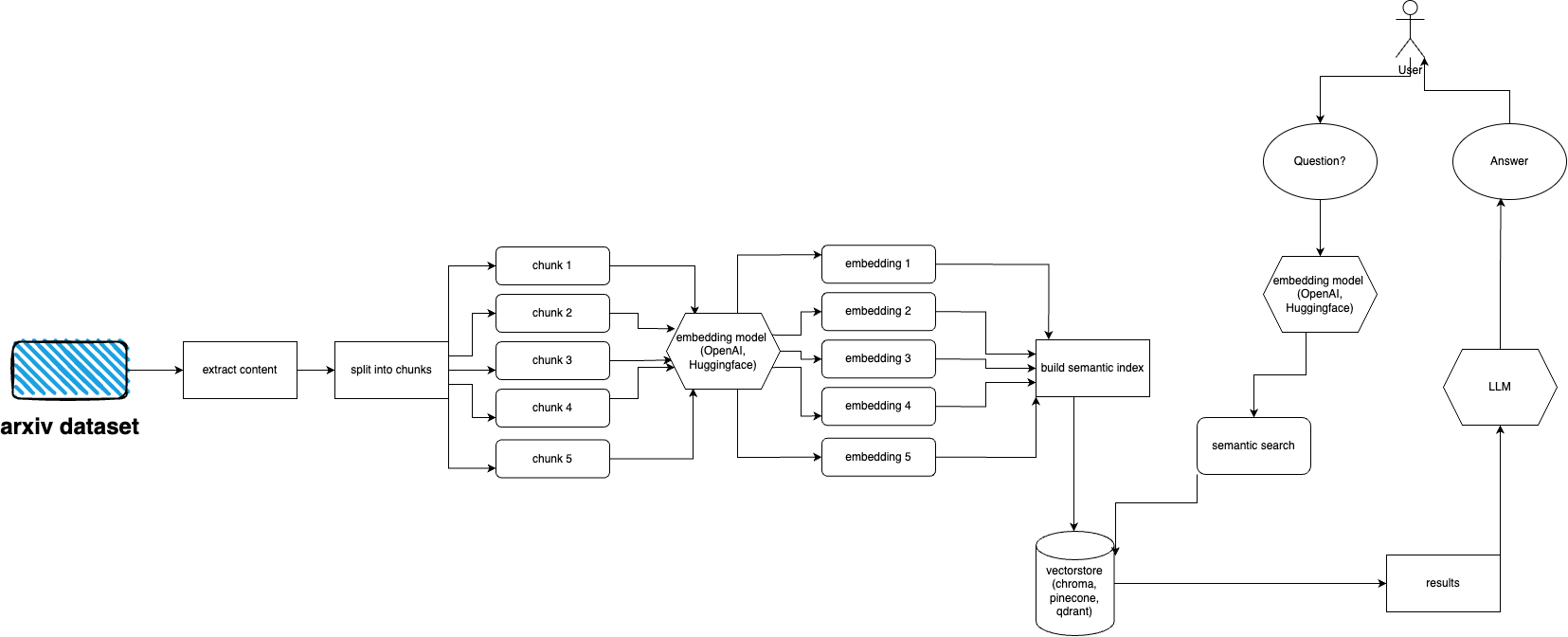
اتبع هذه الخطوات لإعداد وتشغيل المكون الإضافي arXiv بسرعة:
قم بتثبيت Python 3.10، إذا لم يكن مثبتًا بالفعل.
استنساخ المستودع: git clone https://github.com/Forward-Operators/arxivchat.git
انتقل إلى دليل المستودع المستنسخ: cd /path/to/arxivchat
تثبيت الشعر: pip install poetry
قم بإنشاء بيئة افتراضية جديدة باستخدام Python 3.10: poetry env use python3.10
تفعيل البيئة الافتراضية : poetry shell
تثبيت تبعيات التطبيق: poetry install
قم بتعيين متغيرات البيئة المطلوبة:
export DATABASE= < your_datastore >
export OPENAI_API_KEY= < your_openai_api_key >
# Add the environment variables for your chosen vector DB.
# Pinecone
export PINECONE_API_KEY= < your_pinecone_api_key >
export PINECONE_ENVIRONMENT= < your_pinecone_environment >
export PINECONE_INDEX= < your_pinecone_index >
# Qdrant
export QDRANT_URL= < your_qdrant_url >
export QDRANT_PORT= < your_qdrant_port >
export QDRANT_GRPC_PORT= < your_qdrant_grpc_port >
export QDRANT_API_KEY= < your_qdrant_api_key >
export QDRANT_COLLECTION= < your_qdrant_collection >
# Chroma
export CHROMA_HOST= < your_chroma_host >
export CHROMA_PORT= < your_chroma_port >
export CHROMA_COLLECTION= < your_chroma_collection >
# Embeddings
export EMBEDDINGS= < openai or huggingface >
export CUDA_ENABLED= < True or False > - needed for huggingface
قم بتشغيل واجهة برمجة التطبيقات محليًا: cd app/; gunicorn --worker-class uvicorn.workers.UvicornWorker --config ./gunicorn_conf.py main:app
قم بالوصول إلى وثائق API على http://0.0.0.0:8000/docs واختبر نقاط نهاية API.
يحتوي arXiv على مجموعة بيانات تضم ما يقرب من 2 مليون منشور. يعد جلب الكثير من البيانات من موقع الويب الخاص بهم أمرًا مخالفًا لشروط خدمة arXiv (حيث يؤدي ذلك إلى إنشاء تحميل). ولحسن الحظ، يقوم الأشخاص الجيدون من kaggle بالتعاون مع جامعة كورنيل بإنشاء مجموعة بيانات متاحة للعامة يمكنك استخدامها. مجموعة البيانات متاحة مجانًا عبر مجموعات Google Cloud Storage ويتم تحديثها أسبوعيًا.
المشكلة الرئيسية الآن هي - كيفية الحصول على مجموعة فرعية فقط من مجموعة البيانات بأكملها إذا كنا لا نريد استيعاب أكثر من 5 تيرابايت من ملفات pdf؟ تنقسم مجموعة البيانات إلى أدلة شهريًا وسنويًا، لذلك إذا كنت ترغب في الحصول على جميع المنشورات اعتبارًا من سبتمبر 2021، فيمكنك فقط تشغيل: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/2109/ ./local_directory
إذا كنت ترغب في الحصول على مجموعة بيانات كاملة: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/ ./a_local_directory/
ولكن إذا كنت تريد الحصول على مجموعة فرعية فقط (لفئة وتواريخ معينة) فقم بإلقاء نظرة على ملف download.py .
افتراضيًا، يتوقع برنامج الإدخال أن تكون هذه الملفات في /mnt/dataset/arxiv/pdf مع وجود جميع ملفات pdf هناك.
قم بفحص وتشغيل python scripy.py لاستيعاب البيانات. يمكنك أيضًا تمكين تصحيح الأخطاء هناك إذا لم ينجح شيء ما.
TODO: ربما قم بتغيير هذا إلى أداة تحميل الدليل TODO: تنفيذ نشر الكرفس واستخدام العامل للابتلاع
python cli.py 
اطرح سؤالاً حول الموضوع الذي قمت بتغذية قاعدة البيانات به من قبل. إرجاع معلومات حول المصادر أيضًا، ويعمل بشكل مستمر. هناك خيار آخر وهو استخدام REST API (تشغيل uvicorn main:app --reload --host 0.0.0.0 --port 8000 من دليل app ) أو استخدامه كمكون إضافي لـ ChatGPT (بعد النشر)
توجد ملفات terraform في دليل deployment . استخدام واحد الذي يناسبك. يوجد ملف README في كل منها مع التعليمات. يمكنك أيضًا إنشاء صورة Docker وتشغيلها أينما تريد. على الرغم من أن ملف الصورة كبير جدًا.
في الوقت الحالي، يمكن نشره كـ Cloud Run باستخدام صورة عامل الإرساء، لذا فهو نشر لواجهة برمجة التطبيقات (API) فقط. يجب تشغيل عملية استيعاب البيانات على جهاز آخر (أوصي بمحركات حسابية تدعم وحدة معالجة الرسومات، خاصة إذا كنت ترغب في استخدام عمليات تضمين Hugging Face ولأنه يمكنك تحميل قاعدة البيانات من Google Storage مباشرةً باستخدام gcsfuse ) الحل المحتمل لاستخدام مجموعة GCS مع السحابة يجري
في الوقت الحالي، يمكن نشره كتطبيقات حاوية (نشر واجهة برمجة التطبيقات (API) فقط، تحتاج إلى نشر آخر لإدخاله)
AWS غير مدعوم حتى الآن. قريباً.
يستخدم arxivchat text-embedding-ada-002 لـ OpenAI بشكل افتراضي، ويمكنك تغيير ذلك في app/tools/factory.py
يمكنك الآن استخدام أي نموذج يعمل sentence_transformers . يمكنك تغيير النموذج في app/tools/factory.py
إذا كانت لديك أية مشكلات، فيرجى استخدام مشكلات GitHub للإبلاغ عنها.
نحن نحب مساعدتك في جعل arXivchat أفضل! للمساهمة، يرجى اتباع الخطوات التالية:
تم إصدار arXivchat بموجب ترخيص MIT.


