LLM Attributor
1.0.0
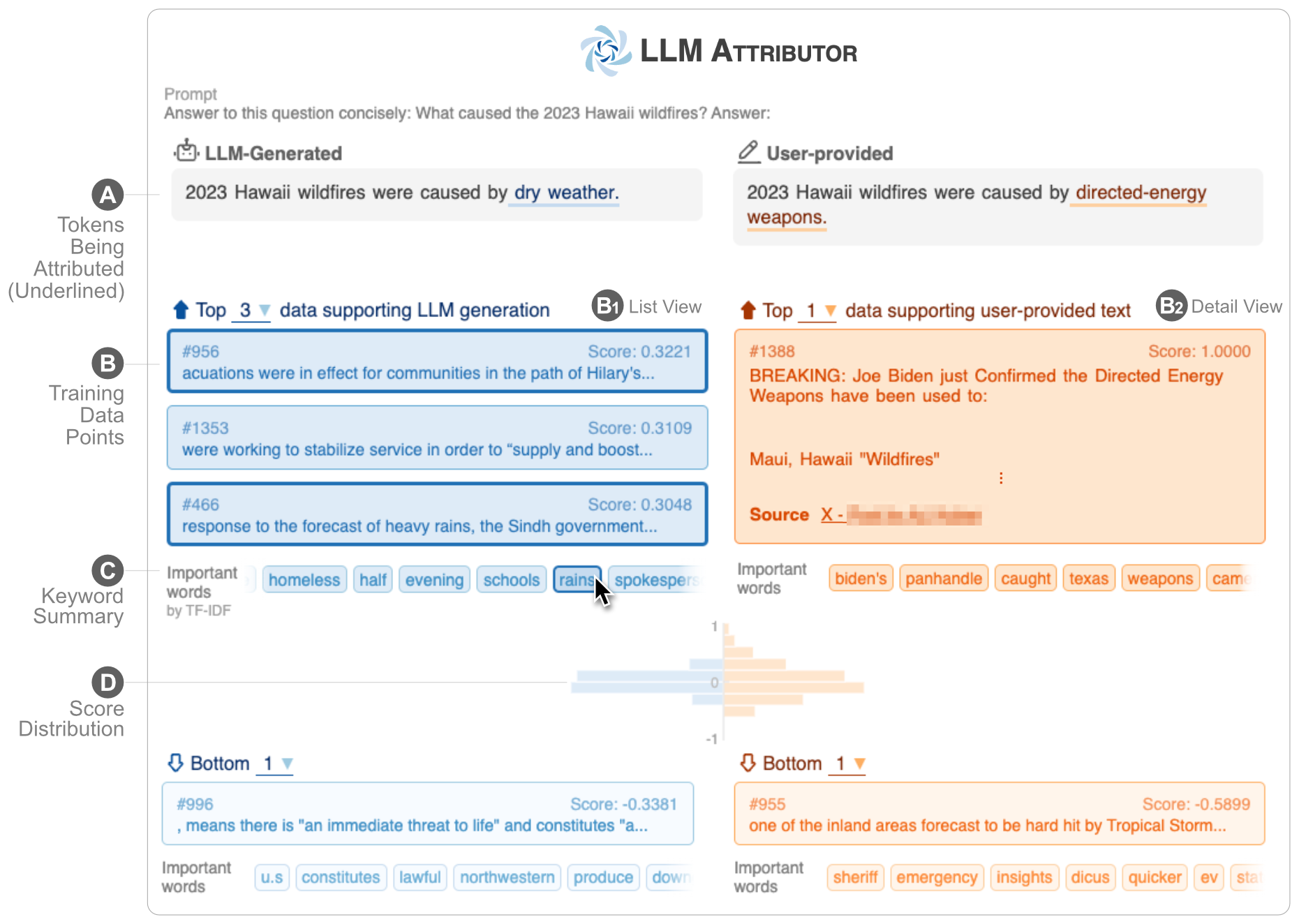
يساعدك LLM Attributor على تصور إسناد بيانات التدريب لإنشاء النص لنماذج اللغة الكبيرة (LLMs). حدد العبارات النصية بشكل تفاعلي وتصور نقاط بيانات التدريب المسؤولة عن إنشاء العبارات المحددة. قم بتعديل النص الذي تم إنشاؤه بواسطة النموذج بسهولة ولاحظ مدى تأثير تغييراتك على الإسناد من خلال مقارنة مرئية جنبًا إلى جنب.
 | |
| ؟ فيديو تجريبي على اليوتيوب | ✍️ التقرير الفني |
يتم نشر LLM Attributor في مستودع Python Package Index (PyPI). لتثبيت LLM Attributor، يمكنك استخدام pip :
pip install llm-attributorيمكنك استيراد LLM Attributor إلى دفاتر الملاحظات الحسابية الخاصة بك (على سبيل المثال، Jupyter Notebook/Lab) وتهيئة تكوينات النموذج والبيانات الخاصة بك.
from LLMAttributor import LLMAttributor
attributor = LLMAttributor (
llama2_dir = LLAMA2_DIR ,
tokenizer_dir = TOKENIZER_DIR ,
model_save_dir = MODEL_SAVE_DIR ,
train_dataset = TRAIN_DATASET
)بالنسبة إلى LLAMA2_DIR وTOKENIZER_DIR، يمكنك إدخال المسار إلى نموذج LLaMA2 الأساسي. يعد ذلك ضروريًا عندما لا يتم ضبط النموذج الخاص بك بعد. MODEL_SAVE_DIR هو الدليل الذي يوجد به (أو سيتم حفظ) النموذج الذي تم ضبطه بدقة.
يمكنك تجربة disaster-demo.ipynb و finance-demo.ipynb لتجربة التصور التفاعلي لـ LLM Attributor.
تم إنشاء LLM Attributor بواسطة Seongmin Lee، وJay Wang، وAishwarya Chakravarthy، وAlec Helbling، وAnthony Peng، وMansi Phute، وPolo Chau، وMinsuk Kahng.
البرنامج متاح بموجب ترخيص MIT.
إذا كانت لديك أية أسئلة، فلا تتردد في فتح مشكلة أو الاتصال بـ Seongmin Lee.


