BinaryVectorDB
1.0.0
يحتوي هذا المستودع على قاعدة بيانات متجهة ثنائية للبحث الفعال في مجموعات البيانات الكبيرة، والتي تهدف إلى الأغراض التعليمية.
تمثل معظم نماذج التضمين متجهاتها كـ float32: وهي تستهلك قدرًا كبيرًا من الذاكرة والبحث عنها بطيء جدًا. في Cohere، قدمنا نموذج التضمين الأول مع int8 الأصلي والدعم الثنائي، مما يمنحك جودة بحث ممتازة مقابل جزء بسيط من التكلفة:
| نموذج | جودة البحث MIRACL | حان الوقت للبحث في مليون مستند | الذاكرة مطلوبة 250 مليون تضمين ويكيبيديا | السعر على AWS (مثيل x2 جيجابايت) |
|---|---|---|---|---|
| OpenAI تضمين النص-3-صغير | 44.9 | 680 مللي ثانية | 1431 جيجابايت | 65,231 دولارًا في السنة |
| OpenAI تضمين النص-3-كبير | 54.9 | 1240 مللي ثانية | 2861 جيجابايت | 130,463 دولارًا سنويًا |
| Cohere Embed v3 (متعدد اللغات) | ||||
| تضمين v3 - float32 | 66.3 | 460 مللي ثانية | 954 جيجابايت | 43,488 دولارًا سنويًا |
| تضمين الإصدار 3 - ثنائي | 62.8 | 24 مللي ثانية | 30 جيجابايت | 1,359 دولارًا في السنة |
| تضمين v3 - استعادة ثنائي + int8 | 66.3 | 28 مللي ثانية | ذاكرة 30 جيجابايت + قرص 240 جيجابايت | 1,589 دولارًا في السنة |
أنشأنا عرضًا توضيحيًا يسمح لك بالبحث في 100 مليون تضمينات ويكيبيديا عن جهاز افتراضي يكلف 15 دولارًا شهريًا فقط: العرض التوضيحي - ابحث في 100 مليون تضمينات ويكيبيديا مقابل 15 دولارًا شهريًا فقط
يمكنك بسهولة استخدام BinaryVectorDB على البيانات الخاصة بك.
الإعداد سهل:
pip install BinaryVectorDB
لاستخدام بعض الأمثلة أدناه، تحتاج إلى مفتاح Cohere API (مجاني أو مدفوع) من cohere.com. يجب عليك تعيين مفتاح API هذا كمتغير بيئة: export COHERE_API_KEY=your_api_key
سنوضح لاحقًا كيفية إنشاء قاعدة بيانات متجهة على بياناتك الخاصة. في البداية، دعونا نستخدم قاعدة بيانات المتجهات الثنائية المعدة مسبقًا . نحن نستضيف العديد من قواعد البيانات سابقة الإنشاء على https://huggingface.co/datasets/Cohere/BinaryVectorDB. يمكنك تنزيلها واستخدامها محليًا.
دعونا نبدأ بالنسخة الإنجليزية البسيطة من ويكيبيديا:
wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/wikipedia-2023-11-simple.zip
ثم قم بفك ضغط هذا الملف:
unzip wikipedia-2023-11-simple.zip
يمكنك تحميل قاعدة البيانات بسهولة عن طريق توجيهها إلى المجلد الذي تم فك ضغطه من الخطوة السابقة:
from BinaryVectorDB import BinaryVectorDB
# Point it to the unzipped folder from the previous step
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db = BinaryVectorDB ( "wikipedia-2023-11-simple/" )
query = "Who is the founder of Facebook"
print ( "Query:" , query )
hits = db . search ( query )
for hit in hits [ 0 : 3 ]:
print ( hit )تحتوي قاعدة البيانات على 646,424 تضمينًا ويبلغ حجمها الإجمالي 962 ميجابايت. ومع ذلك، يتم تحميل 80 ميغابايت فقط للتضمينات الثنائية في الذاكرة. يتم الاحتفاظ بالمستندات وتضميناتها int8 على القرص ويتم تحميلها فقط عند الحاجة.
يتيح لنا هذا التقسيم للتضمينات الثنائية في الذاكرة والتضمينات والمستندات int8 الموجودة على القرص إمكانية توسيع نطاق مجموعات البيانات الكبيرة جدًا دون الحاجة إلى الكثير من الذاكرة.
من السهل جدًا إنشاء قاعدة بيانات المتجهات الثنائية الخاصة بك.
from BinaryVectorDB import BinaryVectorDB
import os
import gzip
import json
simplewiki_file = "simple-wikipedia-example.jsonl.gz"
#If file not exist, download
if not os . path . exists ( simplewiki_file ):
cmd = f"wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/simple-wikipedia-example.jsonl.gz"
os . system ( cmd )
# Create the vector DB with an empty folder
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db_folder = "path_to_an_empty_folder/"
db = BinaryVectorDB ( db_folder )
if len ( db ) > 0 :
exit ( f"The database { db_folder } is not empty. Please provide an empty folder to create a new database." )
# Read all docs from the jsonl.gz file
docs = []
with gzip . open ( simplewiki_file ) as fIn :
for line in fIn :
docs . append ( json . loads ( line ))
#Limit it to 10k docs to make the next step a bit faster
docs = docs [ 0 : 10_000 ]
# Add all documents to the DB
# docs2text defines a function that maps our documents to a string
# This string is then embedded with the state-of-the-art Cohere embedding model
db . add_documents ( doc_ids = list ( range ( len ( docs ))), docs = docs , docs2text = lambda doc : doc [ 'title' ] + " " + doc [ 'text' ]) يمكن أن يكون المستند أي كائن قابل للتسلسل في لغة Python. تحتاج إلى توفير وظيفة لـ docs2text التي تعين المستند الخاص بك إلى سلسلة. في المثال أعلاه، قمنا بربط العنوان وحقل النص. يتم إرسال هذه السلسلة إلى نموذج التضمين لإنتاج عمليات تضمين النص المطلوبة.
من السهل إضافة / حذف / تحديث المستندات. راجع الأمثلة/add_update_delete.py للحصول على مثال لبرنامج نصي حول كيفية إضافة/تحديث/حذف المستندات في قاعدة البيانات.
لقد أعلنا عن عمليات تضمين Cohere int8 وBinary Embeddings، التي توفر تقليلًا بمقدار 4x و32x في الذاكرة المطلوبة. علاوة على ذلك، فهو يوفر سرعة تصل إلى 40x في البحث عن المتجهات.
يتم دمج كلا التقنيتين في BinaryVectorDB. على سبيل المثال، لنفترض أن ويكيبيديا الإنجليزية بها 42 مليون تضمين. ستحتاج عمليات تضمين float32 العادية إلى 42*10^6*1024*4 = 160 GB من الذاكرة لاستضافة عمليات التضمين فقط. نظرًا لأن البحث على float32 بطيء نوعًا ما (حوالي 45 ثانية على 42 ميجا بايت)، نحتاج إلى إضافة فهرس مثل HNSW، الذي يضيف 20 جيجابايت أخرى من الذاكرة، لذلك تحتاج إلى إجمالي 180 جيجابايت.
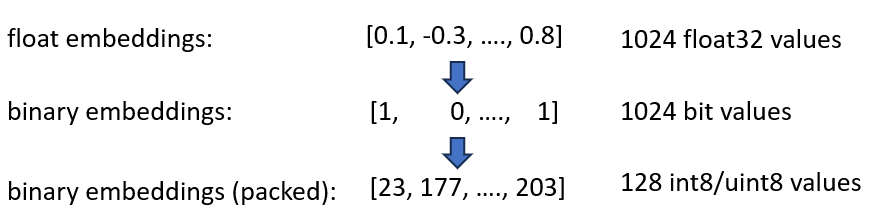
تمثل التضمينات الثنائية كل بُعد بمقدار 1 بت. وهذا يقلل الحاجة إلى الذاكرة إلى 160 GB / 32 = 5GB . كما أن البحث في الفضاء الثنائي أسرع بمقدار 40 مرة، فلن تحتاج إلى فهرس HNSW في كثير من الحالات. لقد قمت بتقليل حاجتك للذاكرة من 180 جيجابايت إلى 5 جيجابايت، مما يوفر 36 ضعفًا.
عندما نقوم بالاستعلام عن هذا الفهرس، نقوم بتشفير الاستعلام أيضًا بشكل ثنائي ونستخدم مسافة هامينغ. تقيس مسافة Hamming الاختلافات بمقدار 1 بت بين متجهين. هذه عملية سريعة للغاية: لمقارنة ناقلين ثنائيين، تحتاج فقط إلى دورتين من وحدات المعالجة المركزية: popcount(xor(vector1, vector2)) . XOR هي العملية الأساسية على وحدات المعالجة المركزية (CPU)، وبالتالي فهي تعمل بسرعة كبيرة. يحسب popcount الرقم 1 في السجل، والذي يحتاج أيضًا إلى دورة واحدة فقط من وحدة المعالجة المركزية.
بشكل عام، يوفر لنا هذا حلاً يحافظ على حوالي 90% من جودة البحث.
يمكننا زيادة جودة البحث عن الخطوة السابقة من 90% إلى 95% عن طريق إعادة تسجيل النتائج <float, binary> .
نحن نأخذ على سبيل المثال أفضل 100 نتيجة من الخطوة 1، ونحسب dot_product(query_float_embedding, 2*binary_doc_embedding-1) .
افترض أن تضمين الاستعلام لدينا هو [0.1, -0.3, 0.4] وأن تضمين المستند الثنائي هو [1, 0, 1] . ثم تحسب هذه الخطوة:
(0.1)*(1) + (-0.3)*(-1) + 0.4*(1) = 0.1 + 0.3 + 0.4 = 0.8

نحن نستخدم هذه النتائج ونعيد تسجيل نتائجنا. وهذا يرفع جودة البحث من 90% إلى 95%. يمكن إجراء هذه العملية بسرعة كبيرة: نحصل على التضمين العائم للاستعلام من نموذج التضمين، والتضمينات الثنائية موجودة في الذاكرة، لذلك نحتاج فقط إلى إجراء 100 عملية جمع.
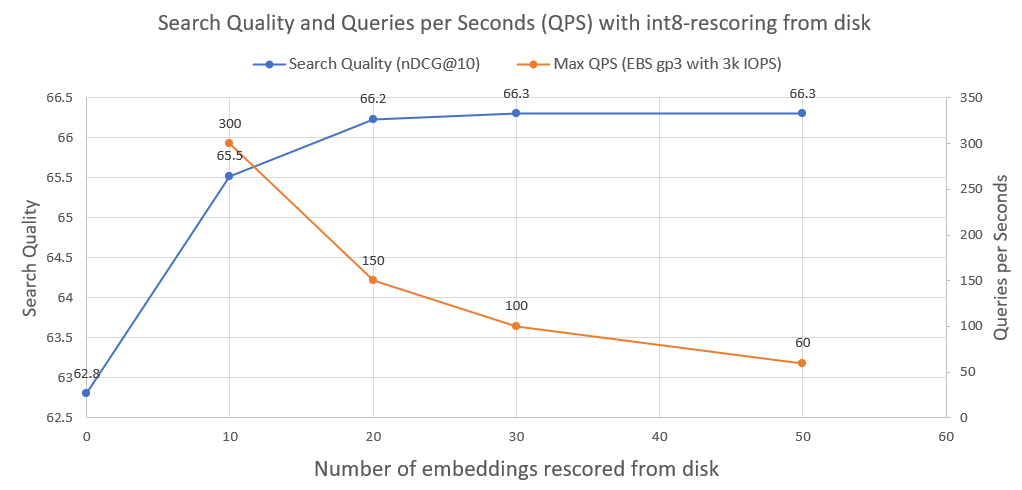
لتحسين جودة البحث بشكل أكبر، من 95% إلى 99.99%، نستخدم تقنية int8 rescoring من القرص.
نقوم بحفظ كافة تضمينات مستند int8 على القرص. نحن نأخذ بعد ذلك أعلى 30 من الخطوة أعلاه، ونقوم بتحميل int8-embeddings من القرص، ونحسب cossim(query_float_embedding, int8_doc_embedding_from_disk)
في الصورة التالية يمكنك معرفة مقدار int8-rescoring وتحسين أداء البحث:
لقد قمنا أيضًا برسم الاستعلامات في الثانية التي يمكن لمثل هذا النظام تحقيقها عند تشغيله على محرك أقراص شبكة AWS EBS عادي مع 3000 IOPS. كما نرى، كلما زاد عدد عمليات تضمين int8 التي نحتاج إلى تحميلها من القرص، قل عدد QPS.
لإجراء البحث الثنائي، نستخدم مؤشر IndexBinaryFlat من faiss. فهو يقوم فقط بتخزين التضمينات الثنائية، ويسمح بفهرسة فائقة السرعة وبحث فائق السرعة.
لتخزين المستندات وتضمينات int8، نستخدم RocksDict، وهو مخزن قيمة مفتاح على القرص لـ Python يعتمد على RocksDB.
راجع BinaryVectorDB للتنفيذ الكامل للفئة.
ليس حقيقيًا. يهدف المستودع في الغالب إلى الأغراض التعليمية لإظهار تقنيات كيفية التوسع في مجموعات البيانات الكبيرة. كان التركيز أكثر على سهولة الاستخدام وكانت بعض الجوانب الهامة مفقودة في التنفيذ، مثل سلامة العمليات المتعددة والتراجع وما إلى ذلك.
إذا كنت تريد بالفعل البدء في الإنتاج، فاستخدم قاعدة بيانات متجهة مناسبة مثل Vespa.ai، والتي تتيح لك تحقيق نتائج مماثلة.
في Cohere، ساعدنا العملاء على تشغيل البحث الدلالي على عشرات المليارات من عمليات التضمين، بجزء بسيط من التكلفة. لا تتردد في التواصل مع Nils Reimers إذا كنت بحاجة إلى حل يتسع نطاقه.


