VideoX
1.0.0
هذه مجموعة من أعمالنا في فهم الفيديو
SeqTrack (
@CVPR'23): SeqTrack: التسلسل إلى التعلم التسلسلي لتتبع الكائنات المرئية
X-CLIP (
@ECCV'22 Oral): توسيع نماذج اللغة والصور المدربة مسبقًا للتعرف العام على الفيديو
MS-2D-TAN (
@TPAMI'21): شبكات متجاورة مؤقتة ثنائية الأبعاد متعددة النطاق لتوطين اللحظة باستخدام اللغة الطبيعية
2D-TAN (
@AAAI'20): تعلم الشبكات المتجاورة المؤقتة ثنائية الأبعاد للتوطين اللحظي باستخدام اللغة الطبيعية
توظيف متدربين باحثين يتمتعون بمهارات برمجة قوية: [email protected] | [email protected]
أبريل 2023: تم الآن إصدار كود SeqTrack .
فبراير 2023: تم قبول SeqTrack في CVPR'23
سبتمبر 2022: تم الآن دمج X-CLIP في
أغسطس 2022: تم الآن إصدار كود X-CLIP .
يوليو 2022: تم قبول X-CLIP في ECCV'22 باعتباره شفهيًا
أكتوبر 2021: تم الآن إصدار كود MS-2D-TAN .
سبتمبر 2021: تم قبول MS-2D-TAN في TPAMI'21
ديسمبر 2019: تم الآن إصدار كود 2D-TAN .
نوفمبر 2019: تم قبول 2D-TAN في AAAI'20
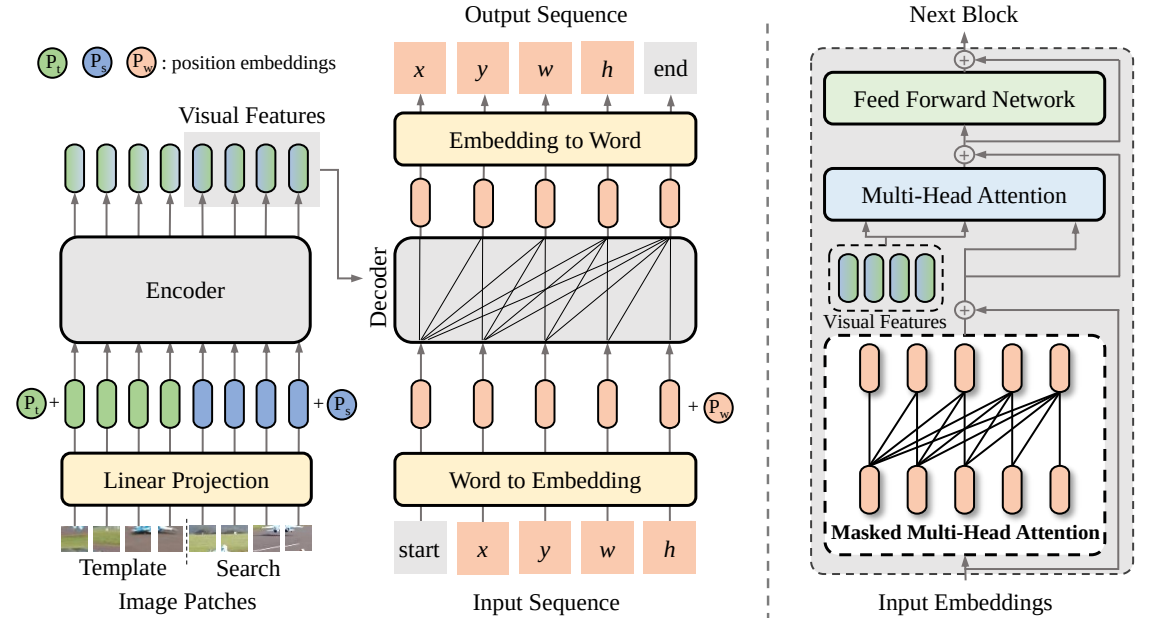
في هذه الورقة، نقترح إطارًا جديدًا للتعلم من تسلسل إلى تسلسل للتتبع البصري، يطلق عليه اسم SeqTrack. إنها تصور التتبع البصري باعتباره مشكلة توليد تسلسل، والتي تتنبأ بالمربعات المحيطة بالكائن بطريقة انحدارية. يعتمد SeqTrack فقط على بنية محول التشفير وفك التشفير البسيطة. يقوم جهاز التشفير باستخراج الميزات المرئية باستخدام محول ثنائي الاتجاه، بينما يقوم جهاز فك التشفير بإنشاء سلسلة من قيم المربع المحيط بشكل انحداري باستخدام وحدة فك تشفير سببية. دالة الخسارة هي إنتروبيا عادية. لا يعمل نموذج التعلم المتسلسل هذا على تبسيط إطار التتبع فحسب، بل يحقق أيضًا أداءً تنافسيًا في العديد من المعايير.
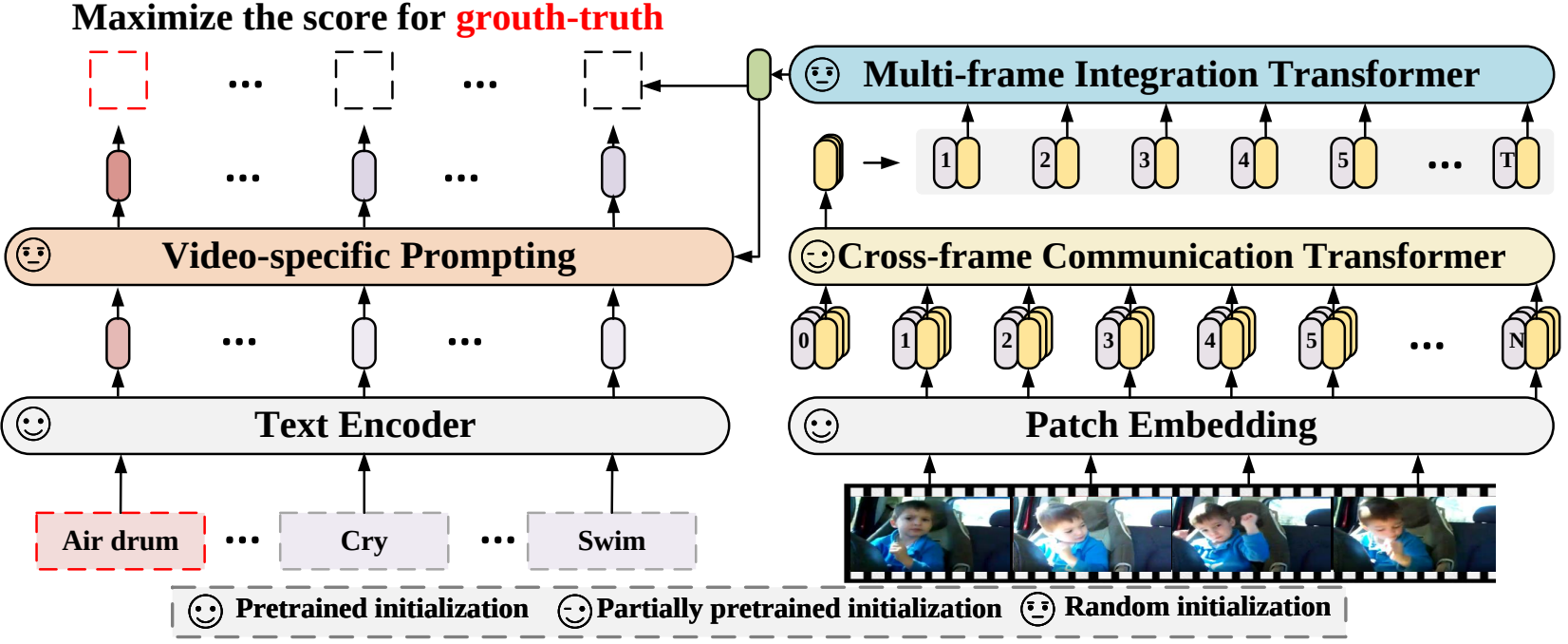
في هذه الورقة، نقترح إطارًا جديدًا للتعرف على الفيديو والذي يكيف نماذج اللغة والصور المدربة مسبقًا للتعرف على الفيديو. على وجه التحديد، لالتقاط المعلومات الزمنية، نقترح آلية الاهتمام عبر الإطارات التي تتبادل المعلومات بشكل صريح عبر الإطارات. للاستفادة من المعلومات النصية في فئات الفيديو، قمنا بتصميم تقنية مطالبة خاصة بالفيديو والتي يمكن أن تؤدي إلى تمثيل نصي تمييزي على مستوى المثيل. تثبت التجارب الموسعة أن النهج الذي نتبعه فعال ويمكن تعميمه على سيناريوهات التعرف على الفيديو المختلفة، بما في ذلك سيناريوهات التعرف على الفيديو الخاضعة للإشراف الكامل، واللقطات القليلة، واللقطة الصفرية.
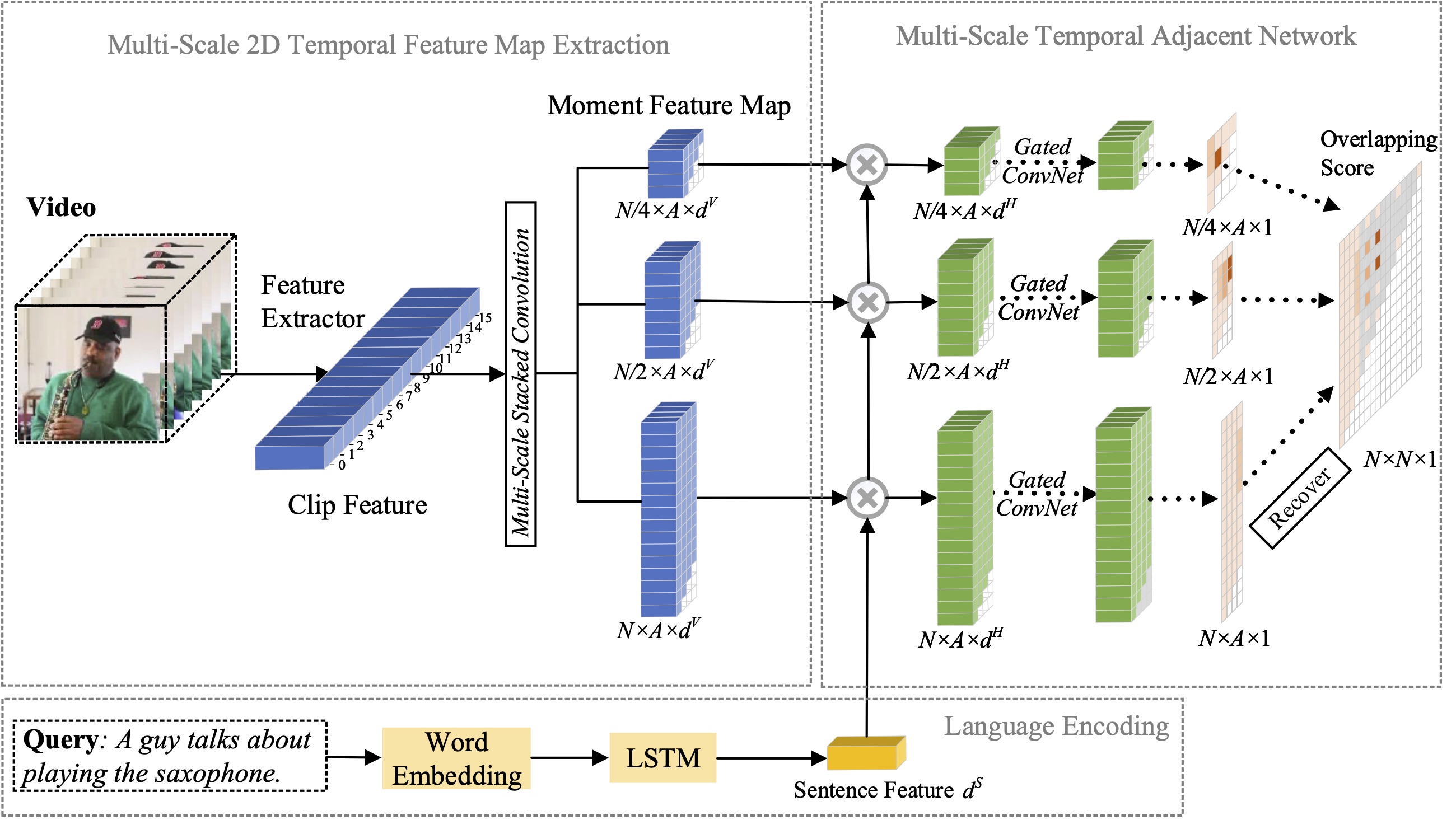
في هذا البحث، ندرس مشكلة توطين اللحظة باللغة الطبيعية، ونقترح توسيع طريقة 2D-TAN المقترحة السابقة إلى إصدار متعدد المقاييس. الفكرة الأساسية هي استرجاع لحظة من الخرائط الزمنية ثنائية الأبعاد بمقاييس زمنية مختلفة، والتي تعتبر مرشحات اللحظة المجاورة هي السياق الزمني. النسخة الموسعة قادرة على تشفير العلاقة الزمنية المجاورة بمقاييس مختلفة، مع تعلم الميزات التمييزية لمطابقة لحظات الفيديو مع التعبيرات المرجعية. نموذجنا بسيط في التصميم ويحقق أداءً تنافسيًا مقارنةً بأحدث الأساليب في ثلاث مجموعات بيانات مرجعية.
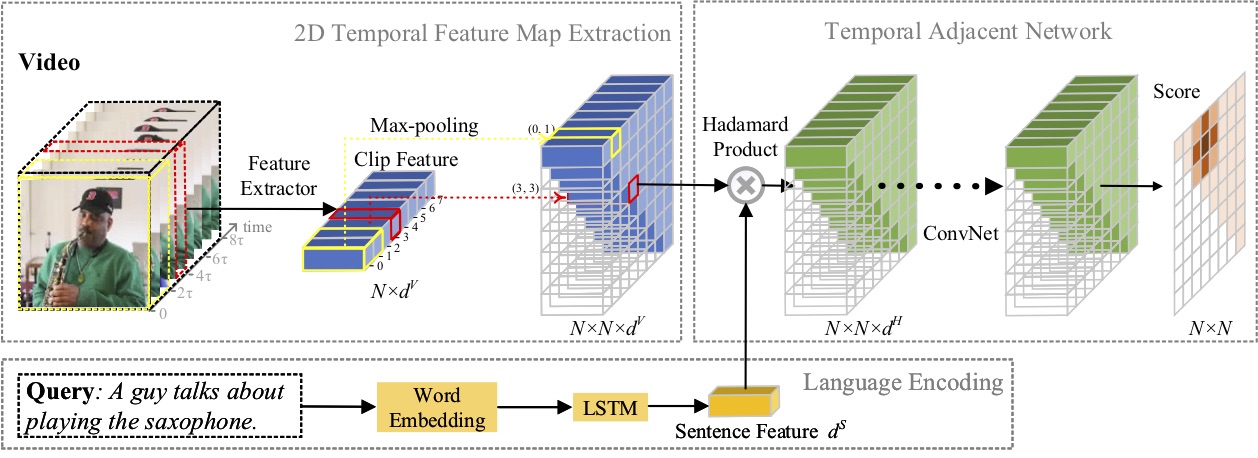
في هذا البحث، قمنا بدراسة مشكلة توطين اللحظة باللغة الطبيعية، واقتراح طريقة جديدة للشبكات المتجاورة المؤقتة ثنائية الأبعاد (2D-TAN). الفكرة الأساسية هي استرجاع لحظة ما على خريطة زمنية ثنائية الأبعاد، والتي تعتبر اللحظة المجاورة المرشحة كسياق زمني. 2D-TAN قادر على تشفير العلاقة الزمنية المجاورة، مع تعلم الميزة التمييزية لمطابقة لحظات الفيديو مع التعبيرات المرجعية. نموذجنا بسيط في التصميم ويحقق أداءً تنافسيًا مقارنةً بأحدث الأساليب في ثلاث مجموعات بيانات مرجعية.
@InProceedings{SeqTrack، العنوان={SeqTrack: التسلسل إلى التعلم التسلسلي لتتبع الكائنات المرئية}، المؤلف={Chen, Xin and Peng, Houwen and Wang, Dong and Lu, Huchuan and Hu, Han}, عنوان الكتاب={CVPR}, year={2023}}@InProceedings{XCLIP, title={توسيع نماذج اللغة والصور المدربة مسبقًا for General Video Recognition}، المؤلف={Ni, Bolin and Peng, Houwen and Chen, Minghao and Zhang, Songyang and Meng, Gaofeng and Fu, Jianlong and Xiang, Shiming and Ling, Haibin}، عنوان الكتاب= {المؤتمر الأوروبي حول رؤية الكمبيوتر (ECCV)}, year={2022}}@InProceedings{Zhang2021MS2DTAN,
المؤلف = {Zhang، Songyang and Peng، Houwen and Fu، Jianlong and Lu، Yijuan and Luo، Jiebo}،
title = {الشبكات المتجاورة المؤقتة ثنائية الأبعاد متعددة النطاق للتوطين اللحظي باستخدام اللغة الطبيعية}،
عنوان الكتاب = {TPAMI}،
العام = {2021}}@InProceedings{2DTAN_2020_AAAI،
المؤلف = {تشانغ، سونغ يانغ وبنغ، هوين وفو، جيان لونغ ولوه، جيبو}،
العنوان = {تعلم الشبكات المتجاورة المؤقتة ثنائية الأبعاد لتوطين اللحظة باستخدام اللغة الطبيعية}،
عنوان الكتاب = {AAAI}،
العام = {2020}}الترخيص بموجب ترخيص MIT.


