horovod
v0.28.1: Build fixes (ROCm, GCC 12)
Horovod هو إطار تدريبي موزع للتعلم العميق لـ TensorFlow وKeras وPyTorch وApache MXNet. الهدف من Horovod هو جعل التعلم العميق الموزع سريعًا وسهل الاستخدام.
تتم استضافة Horovod من قبل مؤسسة LF AI & Data (LF AI & Data). إذا كنت شركة ملتزمة بشدة باستخدام تقنيات مفتوحة المصدر في الذكاء الاصطناعي والآلات والتعلم العميق، وترغب في دعم مجتمعات المشاريع مفتوحة المصدر في هذه المجالات، ففكر في الانضمام إلى LF AI & Data Foundation. للحصول على تفاصيل حول المشاركين وكيف يلعب Horovod دورًا، اقرأ إعلان مؤسسة Linux.
محتويات
الدافع الأساسي لهذا المشروع هو تسهيل أخذ برنامج تدريبي لوحدة معالجة رسومات واحدة وتوسيع نطاقه بنجاح للتدريب عبر العديد من وحدات معالجة الرسومات بالتوازي. وهذا له جانبان:
داخليًا في Uber، وجدنا أن نموذج MPI أكثر وضوحًا ويتطلب تغييرات أقل بكثير في التعليمات البرمجية مقارنة بالحلول السابقة مثل Distributed TensorFlow مع خوادم المعلمات. بمجرد كتابة نص تدريبي للتوسع باستخدام Horovod، يمكن تشغيله على وحدة معالجة رسومات واحدة، أو وحدات معالجة رسومات متعددة، أو حتى مضيفين متعددين دون أي تغييرات إضافية في التعليمات البرمجية. راجع قسم الاستخدام لمزيد من التفاصيل.
بالإضافة إلى كونه سهل الاستخدام، فإن Horovod سريع. يوجد أدناه مخطط يمثل المعيار الذي تم إجراؤه على 128 خادمًا مع 4 وحدات معالجة رسومات Pascal، كل منها متصل بشبكة 25 جيجابت/ثانية قادرة على استخدام RoCE:
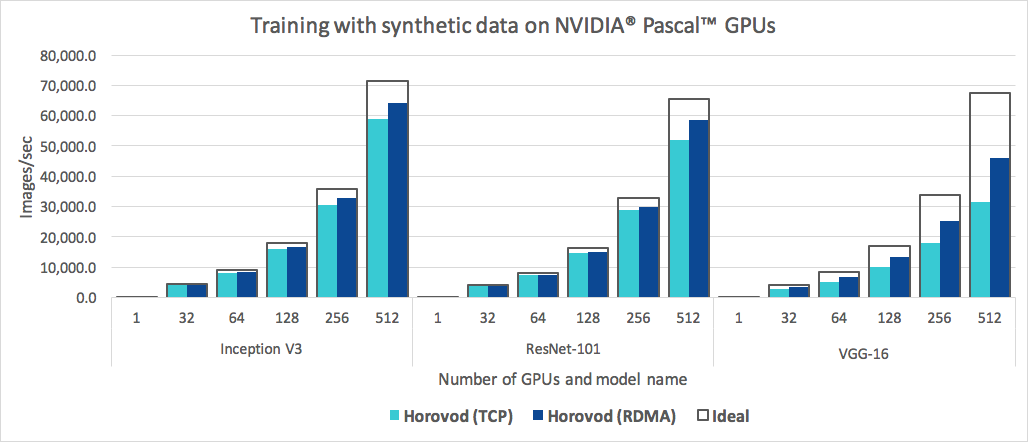
حققت Horovod كفاءة توسيع بنسبة 90% لكل من Inception V3 وResNet-101، وكفاءة توسيع بنسبة 68% لـ VGG-16. راجع المعايير لمعرفة كيفية إعادة إنتاج هذه الأرقام.
في حين أن تثبيت MPI وNCCL في حد ذاته قد يبدو وكأنه متاعب إضافية، إلا أنه لا يلزم القيام به إلا مرة واحدة بواسطة الفريق الذي يتعامل مع البنية التحتية، بينما يمكن لأي شخص آخر في الشركة يقوم ببناء النماذج الاستمتاع ببساطة تدريبهم على نطاق واسع.
لتثبيت Horovod على Linux أو macOS:
إذا قمت بتثبيت TensorFlow من PyPI، فتأكد من تثبيت g++-5 أو أعلى. بدءًا من TensorFlow 2.10، ستكون هناك حاجة إلى مترجم متوافق مع C++ 17 مثل g++8 أو أعلى.
إذا قمت بتثبيت PyTorch من PyPI، فتأكد من تثبيت g++-5 أو أعلى.
إذا قمت بتثبيت أي من الحزمتين من Conda، فتأكد من تثبيت حزمة gxx_linux-64 Conda.
قم بتثبيت حزمة horovod Pip.
للتشغيل على وحدات المعالجة المركزية (CPU):
$ pip install horovodللتشغيل على وحدات معالجة الرسومات باستخدام NCCL:
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovodلمزيد من التفاصيل حول تثبيت Horovod بدعم GPU، اقرأ Horovod على GPU.
للحصول على القائمة الكاملة لخيارات تثبيت Horovod، اقرأ دليل التثبيت.
إذا كنت تريد استخدام MPI، فاقرأ Horovod with MPI.
إذا كنت تريد استخدام Conda، فاقرأ إنشاء بيئة Conda مع دعم GPU لـ Horovod.
إذا كنت تريد استخدام Docker، فاقرأ Horovod في Docker.
لتجميع Horovod من المصدر، اتبع التعليمات الموجودة في دليل المساهمين.
تعتمد مبادئ Horovod الأساسية على مفاهيم MPI مثل الحجم ، والرتبة ، والرتبة المحلية ، وAllreduce ، وAllgather ، وBroadcast ، و Alltoall . انظر هذه الصفحة لمزيد من التفاصيل.
راجع هذه الصفحات للحصول على أمثلة Horovod وأفضل الممارسات:
لاستخدام Horovod، قم بإجراء الإضافات التالية لبرنامجك:
hvd.init() لتهيئة Horovod.قم بتثبيت كل وحدة معالجة رسومات (GPU) بعملية واحدة لتجنب التنافس على الموارد.
مع الإعداد النموذجي لوحدة معالجة رسومات واحدة لكل عملية، قم بتعيين هذا على التصنيف المحلي . سيتم تخصيص وحدة معالجة الرسومات الأولى للعملية الأولى على الخادم، وسيتم تخصيص وحدة معالجة الرسومات الثانية للعملية الثانية، وهكذا.
قياس معدل التعلم حسب عدد العمال.
يتم قياس حجم الدفعة الفعالة في التدريب الموزع المتزامن حسب عدد العمال. الزيادة في معدل التعلم تعوض عن زيادة حجم الدفعة.
لف المحسن في hvd.DistributedOptimizer .
يقوم المحسن الموزع بتفويض حساب التدرج إلى المحسن الأصلي، ومتوسط التدرجات باستخدام allreduce أو allgather ، ثم يطبق متوسط التدرجات.
بث حالات المتغير الأولية من الرتبة 0 إلى جميع العمليات الأخرى.
يعد ذلك ضروريًا لضمان التهيئة المتسقة لجميع العاملين عند بدء التدريب بأوزان عشوائية أو استعادته من نقطة التفتيش.
مثال باستخدام TensorFlow v1 (راجع دليل الأمثلة للحصول على أمثلة تدريبية كاملة):
import tensorflow as tf
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf . ConfigProto ()
config . gpu_options . visible_device_list = str ( hvd . local_rank ())
# Build model...
loss = ...
opt = tf . train . AdagradOptimizer ( 0.01 * hvd . size ())
# Add Horovod Distributed Optimizer
opt = hvd . DistributedOptimizer ( opt )
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
# Make training operation
train_op = opt . minimize ( loss )
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd . rank () == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf . train . MonitoredTrainingSession ( checkpoint_dir = checkpoint_dir ,
config = config ,
hooks = hooks ) as mon_sess :
while not mon_sess . should_stop ():
# Perform synchronous training.
mon_sess . run ( train_op )توضح أمثلة الأوامر أدناه كيفية تشغيل التدريب الموزع. راجع Run Horovod لمزيد من التفاصيل، بما في ذلك تعديلات RoCE/InfiniBand ونصائح للتعامل مع حالات التوقف.
للتشغيل على جهاز مزود بـ 4 وحدات معالجة رسومات:
$ horovodrun -np 4 -H localhost:4 python train.pyللتشغيل على 4 أجهزة تحتوي كل منها على 4 وحدات معالجة رسومات:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py للتشغيل باستخدام Open MPI بدون غلاف horovodrun ، راجع تشغيل Horovod مع Open MPI.
للتشغيل في Docker، راجع Horovod في Docker.
للتشغيل على Kubernetes، راجع Helm Chart وKubeflow MPI Operator وFfDL وPolyaxon.
للتشغيل على Spark، راجع Horovod on Spark.
للتشغيل على راي، راجع Horovod على راي.
للتشغيل في التفرد، راجع التفرد.
للتشغيل في مجموعة LSF HPC (مثل القمة)، راجع LSF.
للتشغيل على Hadoop Yarn، راجع TonY.
Gloo هي مكتبة اتصالات جماعية مفتوحة المصدر تم تطويرها بواسطة Facebook.
يأتي Gloo متضمنًا مع Horovod، ويسمح للمستخدمين بتشغيل Horovod دون الحاجة إلى تثبيت MPI.
بالنسبة للبيئات التي تدعم كلاً من MPI وGloo، يمكنك اختيار استخدام Gloo في وقت التشغيل عن طريق تمرير الوسيطة --gloo إلى horovodrun :
$ horovodrun --gloo -np 2 python train.pyيدعم Horovod خلط ومطابقة مجموعات Horovod مع مكتبات MPI الأخرى، مثل mpi4py، بشرط أن يتم إنشاء MPI بدعم متعدد الخيوط.
يمكنك التحقق من دعم مؤشرات الترابط المتعددة لـ MPI عن طريق الاستعلام عن وظيفة hvd.mpi_threads_supported() .
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Verify that MPI multi-threading is supported.
assert hvd . mpi_threads_supported ()
from mpi4py import MPI
assert hvd . size () == MPI . COMM_WORLD . Get_size ()يمكنك أيضًا تهيئة Horovod باستخدام جهاز اتصال فرعي mpi4py، وفي هذه الحالة سيقوم كل جهاز اتصال فرعي بإجراء تدريب Horovod مستقل.
from mpi4py import MPI
import horovod . tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI . COMM_WORLD . Split ( color = MPI . COMM_WORLD . rank % 2 ,
key = MPI . COMM_WORLD . rank )
# Initialize Horovod
hvd . init ( comm = subcomm )
print ( 'COMM_WORLD rank: %d, Horovod rank: %d' % ( MPI . COMM_WORLD . rank , hvd . rank ()))تعرف على كيفية تحسين نموذجك للاستدلال وإزالة عمليات Horovod من الرسم البياني هنا.
أحد الأشياء الفريدة في Horovod هو قدرته على تشذير الاتصالات والحساب إلى جانب القدرة على تجميع العمليات الصغيرة بشكل جماعي، مما يؤدي إلى تحسين الأداء. نحن نسمي ميزة التجميع هذه Tensor Fusion.
انظر هنا للحصول على التفاصيل الكاملة وتعليمات التغيير والتبديل.
تتمتع هوروفود بالقدرة على تسجيل الجدول الزمني لنشاطها، والذي يسمى هوروفود الجدول الزمني.
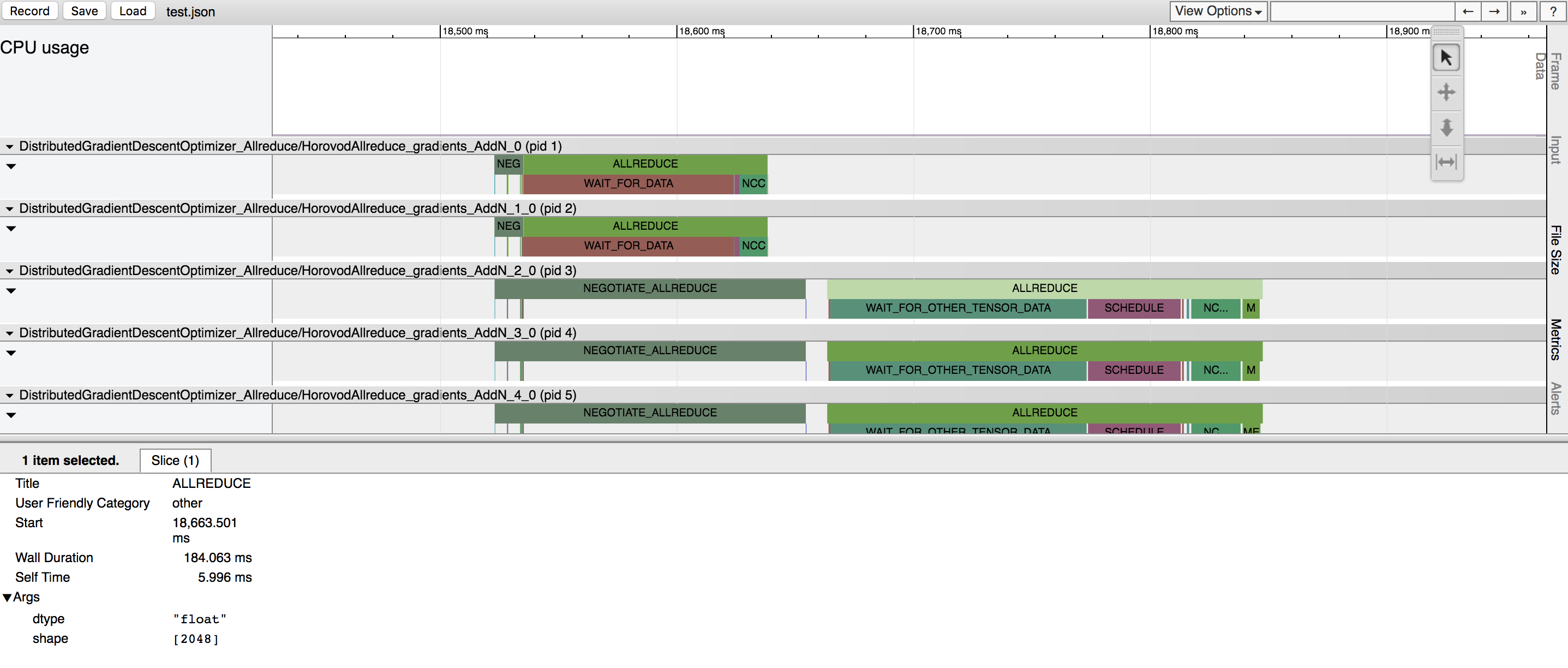
استخدم الجدول الزمني لـHorovod لتحليل أداء Horovod. انظر هنا للحصول على التفاصيل الكاملة وتعليمات الاستخدام.
يمكن أن يتضمن تحديد القيم الصحيحة للاستفادة بكفاءة من Tensor Fusion وميزات Horovod المتقدمة الأخرى قدرًا كبيرًا من التجربة والخطأ. نحن نقدم نظامًا لأتمتة عملية تحسين الأداء يسمى الضبط التلقائي ، والذي يمكنك تمكينه باستخدام وسيطة سطر أوامر واحدة لـ horovodrun .
انظر هنا للحصول على التفاصيل الكاملة وتعليمات الاستخدام.
يتيح لك Horovod إمكانية تشغيل عمليات جماعية متميزة بشكل متزامن في مجموعات مختلفة من العمليات التي تشارك في تدريب واحد موزع. قم بإعداد كائنات hvd.process_set للاستفادة من هذه الإمكانية.
راجع مجموعات العمليات للحصول على تعليمات مفصلة.
أرسل لنا روابط لأي أدلة مستخدم تريد نشرها على هذا الموقع
راجع استكشاف الأخطاء وإصلاحها وإرسال تذكرة إذا لم تتمكن من العثور على إجابة.
يرجى ذكر Horovod في منشوراتك إذا كان ذلك يساعد في بحثك:
@المادة{sergeev2018horovod،
المؤلف = {ألكسندر سيرجيف ومايك ديل بالسو}،
المجلة = {arXiv preprint arXiv:1802.05799}،
العنوان = {Horovod: تعلم عميق موزع سريع وسهل في {TensorFlow}}،
السنة = {2018}
}
1. Sergeev, A., Del Balso, M. (2017) تعرف على Horovod: إطار التعلم العميق الموزع مفتوح المصدر من Uber لـ TensorFlow . تم الاسترجاع من https://eng.uber.com/horovod/
2. سيرجيف، أ. (2017) هوروفود - أصبح TensorFlow الموزع سهلاً . تم الاسترجاع من https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy
3. Sergeev, A., Del Balso, M. (2018) Horovod: التعلم العميق الموزع بسرعة وسهولة في TensorFlow . تم الاسترجاع من أرخايف:1802.05799
استند كود مصدر Horovod إلى مستودع Baidu Tensorflow-allreduce الذي كتبه أندرو جيبانسكي وجويل هيستنيس. تم وصف عملهم الأصلي في المقالة جلب تقنيات HPC إلى التعلم العميق.


