ffhq dataset
1.0.0

Flickr-Faces-HQ (FFHQ) عبارة عن مجموعة بيانات صور عالية الجودة للوجوه البشرية، تم إنشاؤها في الأصل كمعيار لشبكات الخصومة التوليدية (GAN):
بنية المولدات القائمة على الأسلوب لشبكات الخصومة التوليدية
تيرو كاراس (NVIDIA)، سامولي لين (NVIDIA)، تيمو أيلا (NVIDIA)
https://arxiv.org/abs/1812.04948
تتكون مجموعة البيانات من 70.000 صورة PNG عالية الجودة بدقة 1024×1024 وتحتوي على تباين كبير من حيث العمر والعرق وخلفية الصورة. كما أن لديها تغطية جيدة للملحقات مثل النظارات والنظارات الشمسية والقبعات وما إلى ذلك. تم الزحف إلى الصور من Flickr، وبالتالي وراثة جميع التحيزات لهذا الموقع، وتمت محاذاتها واقتصاصها تلقائيًا باستخدام dlib. تم جمع الصور بموجب تراخيص متساهلة فقط. تم استخدام مرشحات تلقائية مختلفة لتهذيب المجموعة، وأخيرًا تم استخدام Amazon Mechanical Turk لإزالة التماثيل أو اللوحات أو الصور الفوتوغرافية العرضية.
يرجى ملاحظة أن مجموعة البيانات هذه ليست مخصصة، ولا ينبغي استخدامها، لتطوير أو تحسين تقنيات التعرف على الوجه. للاستفسارات التجارية، يرجى زيارة موقعنا على الإنترنت وإرسال النموذج: NVIDIA Research Licensing
تم نشر الصور الفردية في Flickr بواسطة مؤلفيها بموجب Creative Commons BY 2.0 أو Creative Commons BY-NC 2.0 أو Public Domain Mark 1.0 أو Public Domain CC0 1.0 أو ترخيص الأشغال الحكومية الأمريكية. تسمح جميع هذه التراخيص بالاستخدام المجاني وإعادة التوزيع والتكيف لأغراض غير تجارية . ومع ذلك، يتطلب بعضها منح الفضل المناسب للمؤلف الأصلي، بالإضافة إلى الإشارة إلى أي تغييرات تم إجراؤها على الصور. تتم الإشارة إلى الترخيص والمؤلف الأصلي لكل صورة في البيانات الوصفية.
مجموعة البيانات نفسها (بما في ذلك بيانات تعريف JSON والبرنامج النصي للتنزيل والوثائق) متاحة بموجب ترخيص Creative Commons BY-NC-SA 4.0 من شركة NVIDIA Corporation. يمكنك استخدامه وإعادة توزيعه وتكييفه لأغراض غير تجارية ، طالما أنك (أ) تمنح الفضل المناسب من خلال الاستشهاد ببحثنا ، (ب) تشير إلى أي تغييرات قمت بها، و (ج) توزع أي أعمال مشتقة تحت نفس الترخيص .
تتم استضافة جميع البيانات على Google Drive:
| طريق | مقاس | ملفات | شكل | وصف |
|---|---|---|---|---|
| ffhq-dataset | 2.56 تيرابايت | 210,014 | المجلد الرئيسي | |
| ├ ffhq-dataset-v2.json | 255 ميجا بايت | 1 | JSON | البيانات الوصفية بما في ذلك معلومات حقوق الطبع والنشر وعناوين URL وما إلى ذلك. |
| ├ الصور 1024 × 1024 | 89.1 جيجابايت | 70.000 | PNG | الصور المحاذاة والمقتصة بدقة 1024 × 1024 |
| ├ الصور المصغرة 128 × 128 | 1.95 جيجابايت | 70.000 | PNG | الصور المصغرة بحجم 128×128 |
| ├ الصور البرية | 955 جيجابايت | 70.000 | PNG | الصور الأصلية من فليكر |
| ├ التسجيلات | 273 جيجابايت | 9 | com.tfrecords | بيانات متعددة الدقة لـ StyleGAN وStyleGAN2 |
| └ الكود البريدية | 1.28 تيرابايت | 4 | أَزِيز | محتويات كل مجلد كأرشيف ZIP. |
إحصائيات عالية المستوى:
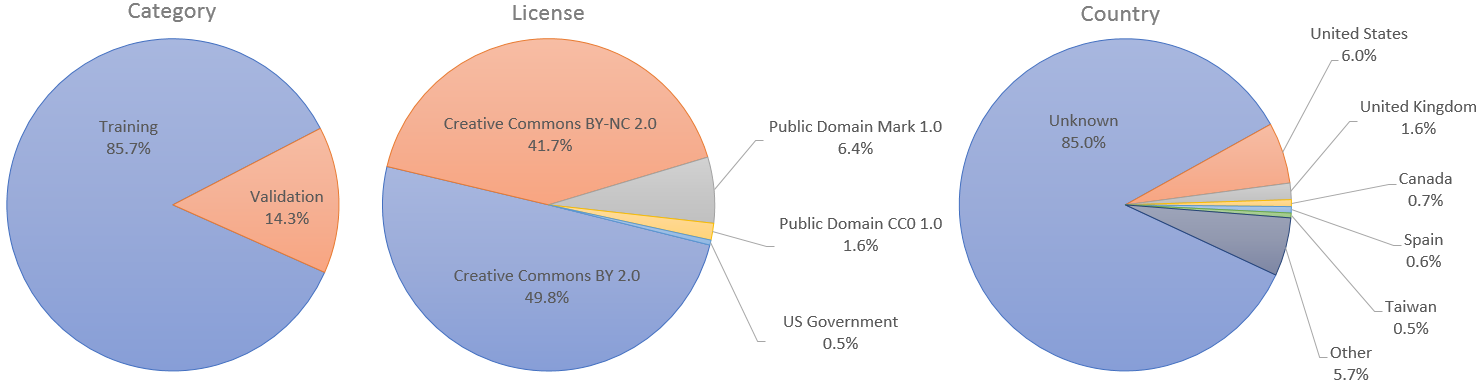
بالنسبة لحالات الاستخدام التي تتطلب مجموعات تدريب وتحقق منفصلة، قمنا بتعيين أول 60000 صورة لاستخدامها في التدريب و10000 صورة المتبقية للتحقق من الصحة. ومع ذلك، في ورقة StyleGAN، استخدمنا جميع الصور البالغ عددها 70.000 صورة للتدريب.
لقد تأكدنا صراحةً من عدم وجود صور مكررة في مجموعة البيانات نفسها. ومع ذلك، يرجى ملاحظة أن المجلد in-the-wild قد يحتوي على نسخ متعددة من نفس الصورة في الحالات التي استخرجنا فيها عدة وجوه مختلفة من نفس الصورة.
يمكنك إما الحصول على البيانات مباشرة من Google Drive أو استخدام البرنامج النصي للتنزيل المقدم. يجعل البرنامج النصي الأمور أسهل إلى حد كبير عن طريق تنزيل جميع الملفات المطلوبة تلقائيًا، والتحقق من المجموع الاختباري الخاص بها، وإعادة محاولة كل ملف عدة مرات عند حدوث خطأ، واستخدام اتصالات متزامنة متعددة لزيادة عرض النطاق الترددي إلى أقصى حد.
> python download_ffhq.py -h
usage: download_ffhq.py [-h] [-j] [-s] [-i] [-t] [-w] [-r] [-a]
[--num_threads NUM] [--status_delay SEC]
[--timing_window LEN] [--chunk_size KB]
[--num_attempts NUM]
Download Flickr-Face-HQ (FFHQ) dataset to current working directory.
optional arguments:
-h, --help show this help message and exit
-j, --json download metadata as JSON (254 MB)
-s, --stats print statistics about the dataset
-i, --images download 1024x1024 images as PNG (89.1 GB)
-t, --thumbs download 128x128 thumbnails as PNG (1.95 GB)
-w, --wilds download in-the-wild images as PNG (955 GB)
-r, --tfrecords download multi-resolution TFRecords (273 GB)
-a, --align recreate 1024x1024 images from in-the-wild images
--num_threads NUM number of concurrent download threads (default: 32)
--status_delay SEC time between download status prints (default: 0.2)
--timing_window LEN samples for estimating download eta (default: 50)
--chunk_size KB chunk size for each download thread (default: 128)
--num_attempts NUM number of download attempts per file (default: 10)
--random-shift SHIFT standard deviation of random crop rectangle jitter
--retry-crops retry random shift if crop rectangle falls outside image (up to 1000
times)
--no-rotation keep the original orientation of images
--no-padding do not apply blur-padding outside and near the image borders
--source-dir DIR where to find already downloaded FFHQ source data
> python ..download_ffhq.py --json --images
Downloading JSON metadata...
100.00% done 2/2 files 0.25/0.25 GB 43.21 MB/s ETA: done
Parsing JSON metadata...
Downloading 70000 files...
| 100.00% done 70001/70001 files 89.19 GB/89.19 GB 59.87 MB/s ETA: done
يعمل البرنامج النصي أيضًا بمثابة تطبيق مرجعي للمخطط الآلي الذي استخدمناه لمحاذاة الصور واقتصاصها. بمجرد تنزيل الصور الداخلية باستخدام python download_ffhq.py --wilds ، يمكنك تشغيل python download_ffhq.py --align لإعادة إنتاج نسخ طبق الأصل من الصور المحاذاة مقاس 1024 × 1024 باستخدام مواقع معالم الوجه المضمنة في البيانات التعريفية .
لإعادة إنتاج مجموعة بيانات "FFHQ غير المحاذية" كما هي مستخدمة في ورقة شبكات الخصومة التوليدية الخالية من الأسماء المستعارة، استخدم الخيارات التالية:
python download_ffhq.py
--source-dir <path/to/downloaded/ffhq>
--align --no-rotation --random-shift 0.2 --no-padding --retry-crops
يحتوي الملف ffhq-dataset-v2.json على المعلومات التالية لكل صورة بتنسيق يمكن قراءته آليًا:
{
"0": { # Image index
"category": "training", # Training or validation
"metadata": { # Info about the original Flickr photo:
"photo_url": "https://www.flickr.com/photos/...", # - Flickr URL
"photo_title": "DSCF0899.JPG", # - File name
"author": "Jeremy Frumkin", # - Author
"country": "", # - Country where the photo was taken
"license": "Attribution-NonCommercial License", # - License name
"license_url": "https://creativecommons.org/...", # - License detail URL
"date_uploaded": "2007-08-16", # - Date when the photo was uploaded to Flickr
"date_crawled": "2018-10-10" # - Date when the photo was crawled from Flickr
},
"image": { # Info about the aligned 1024x1024 image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "images1024x1024/00000/00000.png", # - Google Drive path
"file_size": 1488194, # - Size of the PNG file in bytes
"file_md5": "ddeaeea6ce59569643715759d537fd1b", # - MD5 checksum of the PNG file
"pixel_size": [1024, 1024], # - Image dimensions
"pixel_md5": "47238b44dfb87644460cbdcc4607e289", # - MD5 checksum of the raw pixel data
"face_landmarks": [...] # - 68 face landmarks reported by dlib
},
"thumbnail": { # Info about the 128x128 thumbnail:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "thumbnails128x128/00000/00000.png", # - Google Drive path
"file_size": 29050, # - Size of the PNG file in bytes
"file_md5": "bd3e40b2ba20f76b55dc282907b89cd1", # - MD5 checksum of the PNG file
"pixel_size": [128, 128], # - Image dimensions
"pixel_md5": "38d7e93eb9a796d0e65f8c64de8ba161" # - MD5 checksum of the raw pixel data
},
"in_the_wild": { # Info about the in-the-wild image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "in-the-wild-images/00000/00000.png", # - Google Drive path
"file_size": 3991569, # - Size of the PNG file in bytes
"file_md5": "1dc0287e73e485efb0516a80ce9d42b4", # - MD5 checksum of the PNG file
"pixel_size": [2016, 1512], # - Image dimensions
"pixel_md5": "86b3470c42e33235d76b979161fb2327", # - MD5 checksum of the raw pixel data
"face_rect": [667, 410, 1438, 1181], # - Axis-aligned rectangle of the face region
"face_landmarks": [...], # - 68 face landmarks reported by dlib
"face_quad": [...] # - Aligned quad of the face region
}
},
...
}
نشكر جاكو ليهتينن، وديفيد لوبكي، وتوماس كينكانيمي على المناقشات المتعمقة والتعليقات المفيدة؛ Janne Hellsten وTero Kuosmanen وPekka Jänis للبنية التحتية للحوسبة والمساعدة في إصدار التعليمات البرمجية.
نشكر أيضًا وحيد كاظمي وجوزفين سوليفان على عملهما في الكشف التلقائي عن الوجه ومواءمته مما مكننا من جمع البيانات في المقام الأول:
محاذاة الوجه بمقدار ميلي ثانية واحدة مع مجموعة من أشجار الانحدار
وحيد كاظمي، جوزفين سوليفان
بروك. سي في بي آر 2014
https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Kazemi_One_Milli Second_Face_2014_CVPR_paper.pdf
عند جمع البيانات، حرصنا على تضمين الصور التي - على حد علمنا - كانت مخصصة للاستخدام المجاني وإعادة التوزيع من قبل مؤلفيها. ومع ذلك، نحن ملتزمون بحماية خصوصية الأفراد الذين لا يرغبون في تضمين صورهم.
لمعرفة ما إذا كانت صورتك مضمنة في مجموعة بيانات Flickr-Faces-HQ، يرجى النقر فوق هذا الرابط للبحث في مجموعة البيانات باستخدام اسم مستخدم Flickr الخاص بك.
لإزالة صورتك من مجموعة بيانات Flickr-Faces-HQ:
no_cv على الصورة للإشارة إلى أنك لا ترغب في استخدامها لأبحاث رؤية الكمبيوتر.None (جميع الحقوق محفوظة) أو أي ترخيص Creative Commons مع NoDerivs للإشارة إلى أنك لا تريد إعادة توزيعها.

