SWE bench
1.0.0

| 日本語 | الإنجليزية | 中文简体 | 中文繁體 |
التعليمات البرمجية والبيانات الخاصة بورقة SWE-bench الخاصة بـ ICLR 2024: هل يمكن لنماذج اللغة حل مشكلات GitHub في العالم الحقيقي؟
يرجى الرجوع إلى موقعنا الإلكتروني للحصول على لوحة المتصدرين العامة وسجل التغيير للحصول على معلومات حول آخر التحديثات لمعيار SWE-bench.
يعد SWE-bench معيارًا لتقييم نماذج اللغات الكبيرة بشأن مشكلات البرامج الواقعية التي تم جمعها من GitHub. نظرًا لقاعدة التعليمات البرمجية والمشكلة ، يتم تكليف نموذج اللغة بإنشاء تصحيح يعمل على حل المشكلة الموضحة.
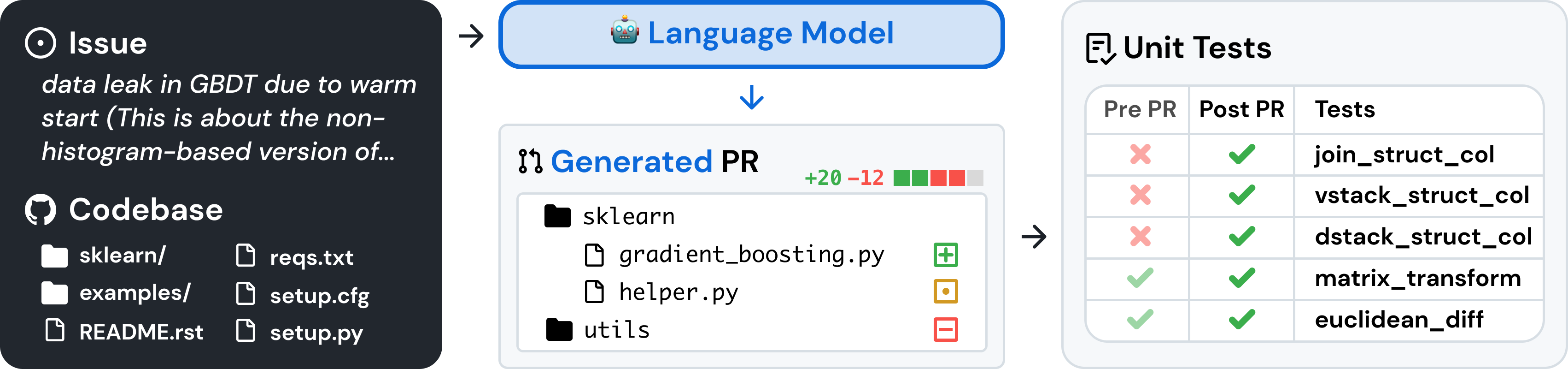
للوصول إلى SWE-bench، انسخ الكود التالي وقم بتشغيله:
from datasets import load_dataset
swebench = load_dataset ( 'princeton-nlp/SWE-bench' , split = 'test' )يستخدم SWE-bench Docker لإجراء تقييمات قابلة للتكرار. اتبع الإرشادات الموجودة في دليل إعداد Docker لتثبيت Docker على جهازك. إذا كنت تقوم بالإعداد على Linux، فنوصيك بالاطلاع على خطوات ما بعد التثبيت أيضًا.
وأخيرًا، لإنشاء SWE-bench من المصدر، اتبع الخطوات التالية:
git clone [email protected]:princeton-nlp/SWE-bench.git
cd SWE-bench
pip install -e .اختبر التثبيت الخاص بك عن طريق تشغيل:
python -m swebench.harness.run_evaluation
--predictions_path gold
--max_workers 1
--instance_ids sympy__sympy-20590
--run_id validate-goldتحذير
يمكن أن يتطلب إجراء تقييمات سريعة على SWE-bench استخدامًا كثيفًا للموارد. نوصي بتشغيل أداة التقييم على جهاز x86_64 مزودًا بمساحة تخزين مجانية تبلغ 120 جيجابايت على الأقل، وذاكرة وصول عشوائي (RAM) تبلغ 16 جيجابايت، و8 مراكز لوحدة المعالجة المركزية (CPU). قد تحتاج إلى تجربة الوسيطة --max_workers للعثور على العدد الأمثل من العمال لجهازك، لكننا نوصي باستخدام أقل من min(0.75 * os.cpu_count(), 24) .
في حالة التشغيل باستخدام سطح مكتب عامل الإرساء، تأكد من زيادة مساحة القرص الظاهري لديك لتوفير ما يقرب من 120 جيجابايت مجانًا، وقم بتعيين الحد الأقصى للعمال ليكون متسقًا مع ما ورد أعلاه لوحدات المعالجة المركزية المتاحة لعامل الإرساء.
يعد دعم أجهزة arm64 تجريبيًا.
قم بتقييم تنبؤات النموذج على SWE-bench Lite باستخدام أداة التقييم باستخدام الأمر التالي:
python -m swebench.harness.run_evaluation
--dataset_name princeton-nlp/SWE-bench_Lite
--predictions_path < path_to_predictions >
--max_workers < num_workers >
--run_id < run_id >
# use --predictions_path 'gold' to verify the gold patches
# use --run_id to name the evaluation run سيقوم هذا الأمر بإنشاء سجلات إنشاء عامل الإرساء ( logs/build_images ) وسجلات التقييم ( logs/run_evaluation ) في الدليل الحالي.
سيتم تخزين نتائج التقييم النهائية في دليل evaluation_results .
لرؤية القائمة الكاملة للوسائط الخاصة بأداة التقييم، قم بتشغيل:
python -m swebench.harness.run_evaluation --helpبالإضافة إلى ذلك، يمكن أن يساعدك مستودع SWE-Bench على:
| مجموعات البيانات | نماذج |
|---|---|
| ؟ مقعد SWE | ؟ سوي-لاما 13 ب |
| ؟ استرجاع "أوراكل". | ؟ سوي-لاما 13 ب (PEFT) |
| ؟ استرجاع BM25 13 كيلو | ؟ سوي-لاما 7 ب |
| ؟ استرجاع BM25 27 كيلو | ؟ سوي-لاما 7 ب (PEFT) |
| ؟ استرجاع BM25 40 ألف | |
| ؟ استرجاع BM25 50 ألف (رموز اللاما) |
لقد كتبنا أيضًا منشورات المدونة التالية حول كيفية استخدام أجزاء مختلفة من SWE-bench. إذا كنت ترغب في رؤية مشاركة حول موضوع معين، يرجى إعلامنا بذلك عبر مشكلة.
نود أن نسمع من مجتمعات أبحاث البرمجة اللغوية العصبية والتعلم الآلي وهندسة البرمجيات الأوسع، ونرحب بأي مساهمات أو طلبات سحب أو مشكلات! للقيام بذلك، يرجى تقديم طلب سحب أو إصدار جديد وملء النماذج المقابلة وفقًا لذلك. سنتأكد من المتابعة قريبًا!
جهة الاتصال: كارلوس إي. خيمينيز وجون يانغ (البريد الإلكتروني: [email protected]، [email protected]).
إذا وجدت أن عملنا مفيد، يرجى استخدام الاستشهادات التالية.
@inproceedings{
jimenez2024swebench,
title={{SWE}-bench: Can Language Models Resolve Real-world Github Issues?},
author={Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=VTF8yNQM66}
}
معهد ماساتشوستس للتكنولوجيا. تحقق من LICENSE.md .


