LLM4Decompile
1.0.0
![]()
النتائج | ؟ نماذج | بداية سريعة | HumanEval-فك | ؟ اقتباس | ورق | كولاب |
الهندسة العكسية: فك الشفرة الثنائية باستخدام نماذج لغوية كبيرة
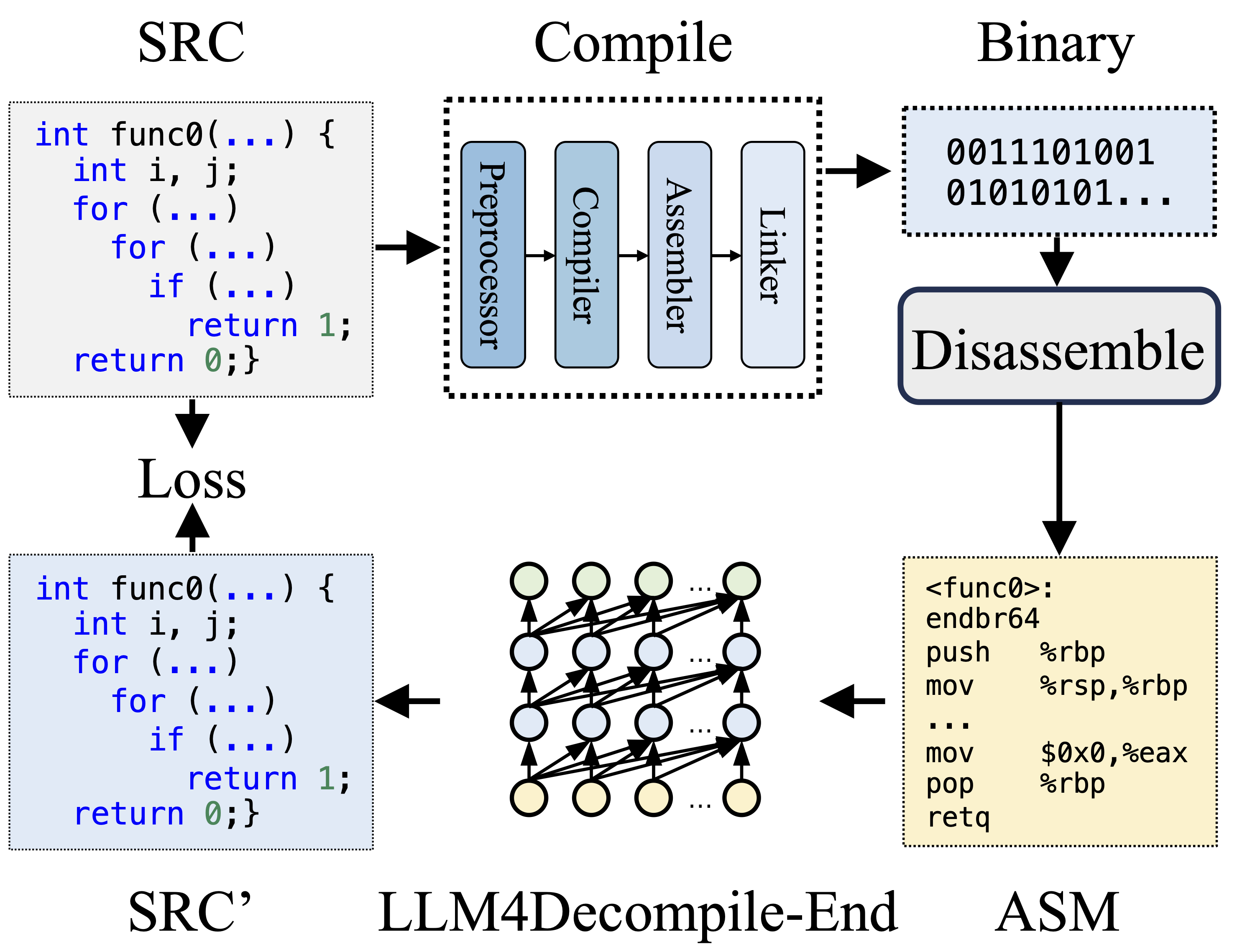
أثناء التجميع، يقوم المعالج المسبق بمعالجة كود المصدر (SRC) لإزالة التعليقات وتوسيع وحدات الماكرو أو التضمين. يتم بعد ذلك إعادة توجيه التعليمات البرمجية التي تم تنظيفها إلى المترجم، الذي يحولها إلى رمز التجميع (ASM). يتم تحويل ASM هذا إلى رمز ثنائي (0 و 1) بواسطة المجمع. يقوم الرابط بإنهاء العملية عن طريق ربط استدعاءات الوظائف لإنشاء ملف قابل للتنفيذ. ومن ناحية أخرى، يتضمن فك الترجمة تحويل التعليمات البرمجية الثنائية مرة أخرى إلى ملف مصدر. يفتقر طلاب ماجستير القانون، الذين يتم تدريبهم على النص، إلى القدرة على معالجة البيانات الثنائية مباشرة. ولذلك، يجب تفكيك الثنائيات بواسطة Objdump إلى لغة التجميع (ASM) أولاً. وتجدر الإشارة إلى أن ASM الثنائي والمفكك متكافئان، ويمكن تحويلهما معًا، وبالتالي نشير إليهما بالتبادل. وأخيرًا، يتم حساب الخسارة بين التعليمات البرمجية التي تم فك ترجمتها والتعليمات البرمجية المصدرية لتوجيه التدريب. لتقييم جودة التعليمات البرمجية التي تم فك ترجمتها (SRC)، يتم اختبار وظائفها من خلال تأكيدات الاختبار (قابلية إعادة التنفيذ).
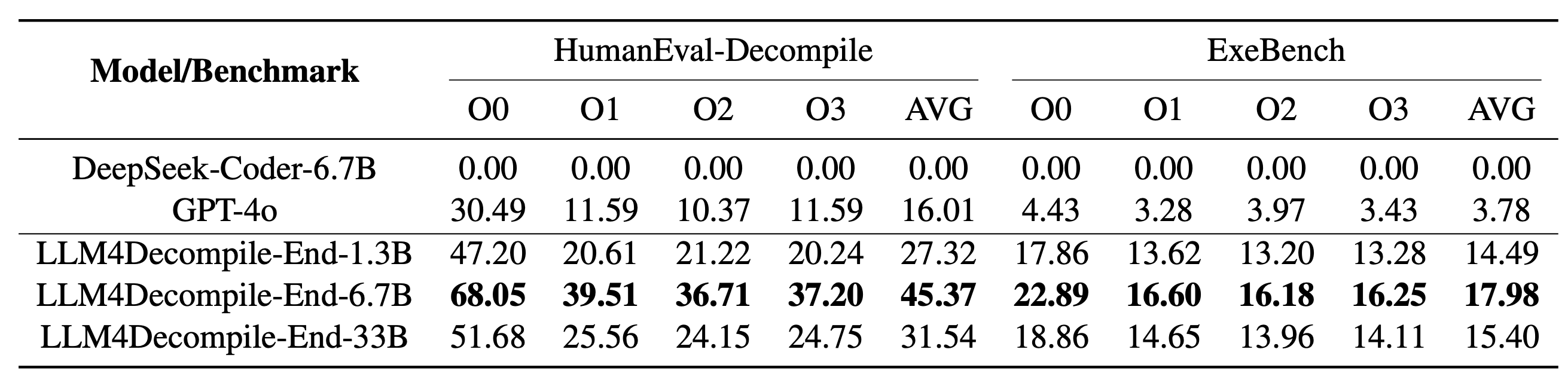
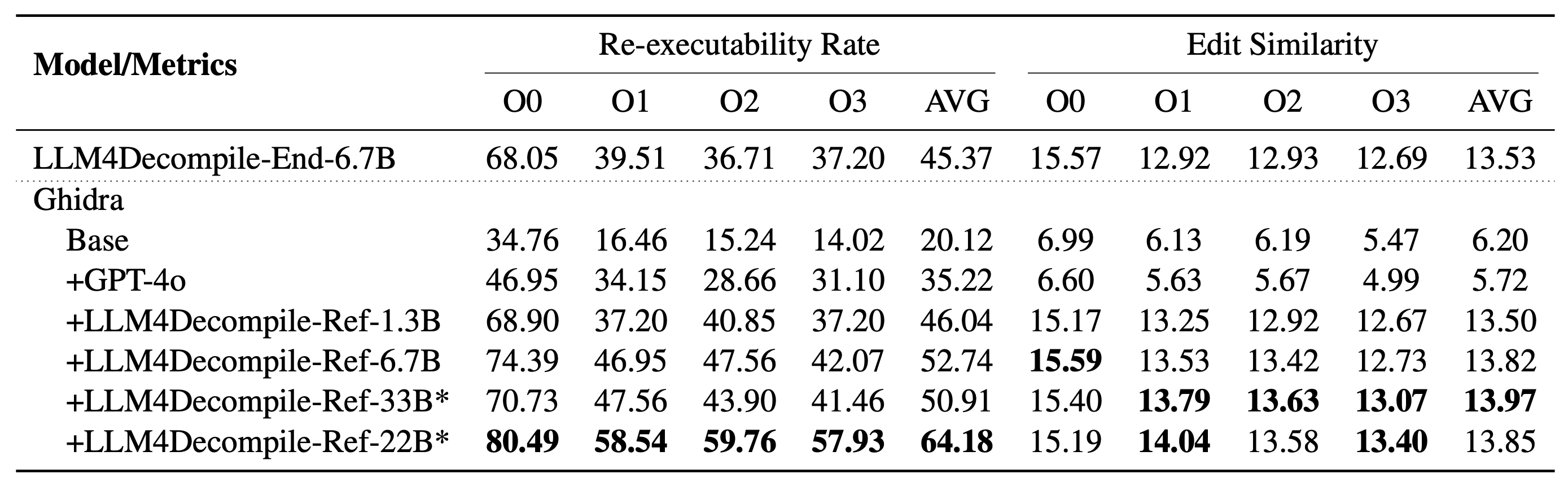
يتضمن LLM4Decompile الخاص بنا نماذج بأحجام تتراوح بين 1.3 مليار و33 مليار معلمة، وقد جعلنا هذه النماذج متاحة على Hugging Face.
| نموذج | نقطة تفتيش | مقاس | إعادة التنفيذ | ملحوظة |
|---|---|---|---|---|
| llm4decompile-1.3b-v1.5 | ؟ رابط اتش اف | 1.3 ب | 27.3% | ملاحظة 3 |
| llm4decompile-6.7b-v1.5 | ؟ رابط اتش اف | 6.7 ب | 45.4% | ملاحظة 3 |
| llm4decompile-1.3b-v2 | ؟ رابط اتش اف | 1.3 ب | 46.0% | الملاحظة 4 |
| llm4decompile-6.7b-v2 | ؟ رابط اتش اف | 6.7 ب | 52.7% | الملاحظة 4 |
| llm4decompile-9b-v2 | ؟ رابط اتش اف | 9 ب | 64.9% | الملاحظة 4 |
| llm4decompile-22b-v2 | ؟ رابط اتش اف | 22 ب | 63.6% | الملاحظة 4 |
الملاحظة 3: تم تدريب سلسلة V1.5 باستخدام مجموعة بيانات أكبر (15 مليار رمز) وحجم رمزي أقصى يبلغ 4,096، مع أداء رائع (تحسن بنسبة تزيد عن 100%) مقارنة بالنموذج السابق.
ملاحظة 4: سلسلة V2 مبنية على غيدرا وتم تدريبها على 2 مليار رمز لتحسين الكود الزائف الذي تم فك ترجمته من غيدرا. تحقق من مجلد غيدرا للحصول على التفاصيل.
الإعداد: الرجاء استخدام البرنامج النصي أدناه لتثبيت البيئة اللازمة.
git clone https://github.com/albertan017/LLM4Decompile.git
cd LLM4Decompile
conda create -n 'llm4decompile' python=3.9 -y
conda activate llm4decompile
pip install -r requirements.txt
فيما يلي مثال لكيفية استخدام نموذجنا (المعدل للإصدار 1.5. بالنسبة للنماذج السابقة، يرجى مراجعة صفحة النموذج المقابل على HF). ملاحظة: استبدل "func0" باسم الوظيفة التي تريد فك ترجمتها .
المعالجة المسبقة: تجميع كود C إلى ثنائي، وتفكيك الثنائي إلى تعليمات التجميع.
import subprocess
import os
func_name = 'func0'
OPT = [ "O0" , "O1" , "O2" , "O3" ]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT :
output_file = fileName + '_' + opt_state
input_file = fileName + '.c'
compile_command = f'gcc -o { output_file } .o { input_file } - { opt_state } -lm' #compile the code with GCC on Linux
subprocess . run ( compile_command , shell = True , check = True )
compile_command = f'objdump -d { output_file } .o > { output_file } .s' #disassemble the binary file into assembly instructions
subprocess . run ( compile_command , shell = True , check = True )
input_asm = ''
with open ( output_file + '.s' ) as f : #asm file
asm = f . read ()
if '<' + func_name + '>:' not in asm : #IMPORTANT replace func0 with the function name
raise ValueError ( "compile fails" )
asm = '<' + func_name + '>:' + asm . split ( '<' + func_name + '>:' )[ - 1 ]. split ( ' n n ' )[ 0 ] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm . split ( " n " )
for tmp in asm_sp :
if len ( tmp . split ( " t " )) < 3 and '00' in tmp :
continue
idx = min (
len ( tmp . split ( " t " )) - 1 , 2
)
tmp_asm = " t " . join ( tmp . split ( " t " )[ idx :]) # remove the binary code
tmp_asm = tmp_asm . split ( "#" )[ 0 ]. strip () # remove the comments
asm_clean += tmp_asm + " n "
input_asm = asm_clean . strip ()
before = f"# This is the assembly code: n " #prompt
after = " n # What is the source code? n " #prompt
input_asm_prompt = before + input_asm . strip () + after
with open ( fileName + '_' + opt_state + '.asm' , 'w' , encoding = 'utf-8' ) as f :
f . write ( input_asm_prompt )يجب أن تكون تعليمات التجميع بالتنسيق:
<FUNCTION_NAME>:nOPERATIONSnOPERATIONSn
قد تبدو تعليمات التجميع النموذجية كما يلي:
<func0>:
endbr64
lea (%rdi,%rsi,1),%eax
retq
فك التجميع: استخدم LLM4Decompile لترجمة تعليمات التجميع إلى لغة C:
from transformers import AutoTokenizer , AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-6.7b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer . from_pretrained ( model_path )
model = AutoModelForCausalLM . from_pretrained ( model_path , torch_dtype = torch . bfloat16 ). cuda ()
with open ( fileName + '_' + OPT [ 0 ] + '.asm' , 'r' ) as f : #optimization level O0
asm_func = f . read ()
inputs = tokenizer ( asm_func , return_tensors = "pt" ). to ( model . device )
with torch . no_grad ():
outputs = model . generate ( ** inputs , max_new_tokens = 2048 ) ### max length to 4096, max new tokens should be below the range
c_func_decompile = tokenizer . decode ( outputs [ 0 ][ len ( inputs [ 0 ]): - 1 ])
with open ( fileName + '.c' , 'r' ) as f : #original file
func = f . read ()
print ( f'original function: n { func } ' ) # Note we only decompile one function, where the original file may contain multiple functions
print ( f'decompiled function: n { c_func_decompile } ' ) يتم تخزين البيانات في llm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.json ، باستخدام تنسيق قائمة JSON. هناك 164*4 عينة (O0، O1، O2، O3)، كل منها بخمسة مفاتيح:
task_id : يشير إلى معرف المشكلة.type : مرحلة التحسين، وهي إحدى [O0, O1, O2, O3].c_func : حل C لمشكلة HumanEval.c_test : تأكيدات اختبار C.input_asm_prompt : تعليمات التجميع مع المطالبات، يمكن استخلاصها كما في مثال المعالجة المسبقة لدينا.يرجى التحقق من البرامج النصية التقييم.
تم ترخيص مستودع التعليمات البرمجية هذا بموجب ترخيص MIT وDeepSeek.
@misc{tan2024llm4decompile,
title={LLM4Decompile: Decompiling Binary Code with Large Language Models},
author={Hanzhuo Tan and Qi Luo and Jing Li and Yuqun Zhang},
year={2024},
eprint={2403.05286},
archivePrefix={arXiv},
primaryClass={cs.PL}
}


