LRV Instruction
1.0.0
فوكسياو ليو، كيفن لين، لينجي لي، جيانفينج وانج، ياسر يعقوب، ليجوان وانج
[صفحة المشروع] [الورقة]
يمكنك المقارنة بين نماذجنا والنماذج الأصلية أدناه. إذا لم تنجح العروض التوضيحية عبر الإنترنت، فيرجى إرسال بريد إلكتروني [email protected] . إذا وجدت أن عملنا مثير للاهتمام، يرجى ذكر عملنا. شكرًا!!!
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}
@article { liu2023hallusionbench ,
title = { HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V (ision), LLaVA-1.5, and Other Multi-modality Models } ,
author = { Liu, Fuxiao and Guan, Tianrui and Li, Zongxia and Chen, Lichang and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi } ,
journal = { arXiv preprint arXiv:2310.14566 } ,
year = { 2023 }
}
@article { liu2023mmc ,
title = { MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning } ,
author = { Liu, Fuxiao and Wang, Xiaoyang and Yao, Wenlin and Chen, Jianshu and Song, Kaiqiang and Cho, Sangwoo and Yacoob, Yaser and Yu, Dong } ,
journal = { arXiv preprint arXiv:2311.10774 } ,
year = { 2023 }
} [عرض LRV-V2(Mplug-Owl)، [عرض mplug-owl]
[عرض LRV-V1(MiniGPT4)]، [عرض MiniGPT4-7B]
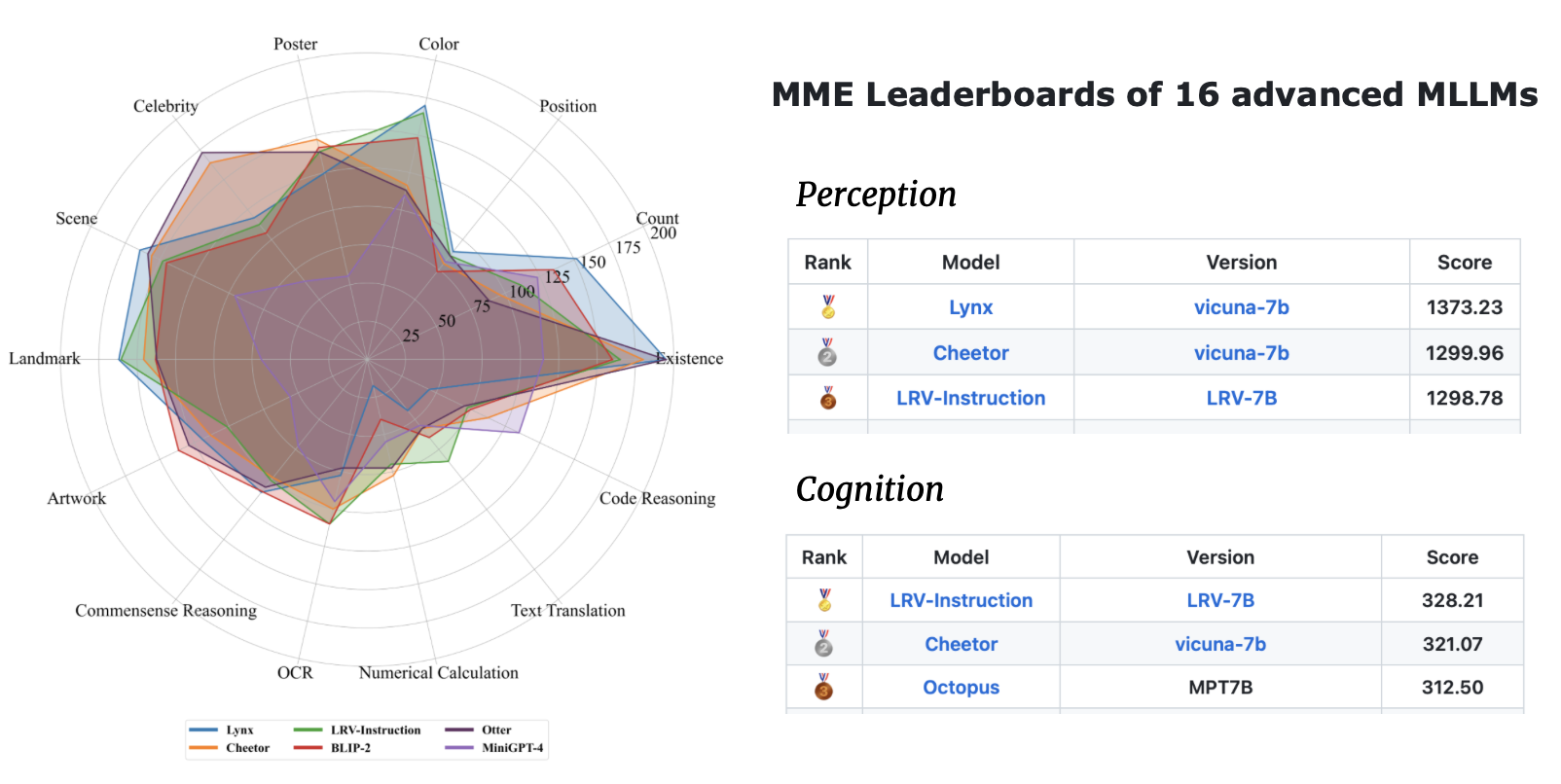
| اسم النموذج | العمود الفقري | رابط التحميل |
|---|---|---|
| LRV-تعليمات V2 | Mplug-البومة | وصلة |
| LRV-تعليمات V1 | ميني جي بي تي 4 | وصلة |
| اسم النموذج | تعليمات | صورة |
|---|---|---|
| تعليمات LRV | وصلة | وصلة |
| تعليمات LRV (المزيد) | وصلة | وصلة |
| تعليمات الرسم البياني | وصلة | وصلة |
نقوم بتحديث مجموعة البيانات بتعليمات مرئية يبلغ عددها 300 ألف تم إنشاؤها بواسطة GPT4، وتغطي 16 مهمة تتعلق بالرؤية واللغة مع تعليمات وإجابات مفتوحة. تتضمن تعليمات LRV كلاً من التعليمات الإيجابية والتعليمات السلبية لضبط التعليمات المرئية بشكل أكثر قوة. صور مجموعة البيانات الخاصة بنا مأخوذة من Visual Genome. يمكن الوصول إلى بياناتنا من هنا.
{'image_id': '2392588', 'question': 'Can you see a blue teapot on the white electric stove in the kitchen?', 'answer': 'There is no mention of a teapot on the white electric stove in the kitchen.', 'task': 'negative'}
لكل مثيل، يشير image_id إلى الصورة من Visual Genome. question answer يشيران إلى زوج التعليمات والإجابة. task تشير إلى اسم المهمة. يمكنك تحميل الصور من هنا.
نحن نقدم مطالباتنا لاستعلامات GPT-4 لتسهيل البحث بشكل أفضل في هذا المجال. يرجى مراجعة مجلد prompts لإنشاء المثيلات الإيجابية والسلبية. يحتوي الملف negative1_generation_prompt.txt على المطالبة لإنشاء تعليمات سلبية باستخدام معالجة العناصر غير الموجودة. يحتوي negative2_generation_prompt.txt على المطالبة لإنشاء تعليمات سلبية باستخدام معالجة العناصر الموجودة. يمكنك الرجوع إلى الكود هنا لإنشاء المزيد من البيانات. يرجى الاطلاع على ورقتنا لمزيد من التفاصيل.

1. استنساخ هذا المستودع
https://github.com/FuxiaoLiu/LRV-Instruction.git2. تثبيت الحزمة
conda env create -f environment.yml --name LRV
conda activate LRV3. تحضير أوزان فيكونا
تم ضبط نموذجنا على MiniGPT-4 باستخدام Vicuna-7B. يرجى الرجوع إلى التعليمات هنا لإعداد أوزان فيكونا أو تنزيلها من هنا. ثم قم بتعيين المسار إلى وزن Vicuna في MiniGPT-4/minigpt4/configs/models/minigpt4.yaml في السطر 15.
4. قم بإعداد نقطة التفتيش المدربة مسبقًا لنموذجنا
قم بتنزيل نقاط التفتيش المدربة مسبقًا من هنا
بعد ذلك، قم بتعيين المسار إلى نقطة التفتيش المُدربة مسبقًا في MiniGPT-4/eval_configs/minigpt4_eval.yaml في السطر 11. تعتمد نقطة التفتيش هذه على MiniGPT-4-7B. سنطلق نقاط التفتيش الخاصة بـ MiniGPT-4-13B وLLaVA في المستقبل.
5. قم بتعيين مسار مجموعة البيانات
بعد الحصول على مجموعة البيانات، قم بتعيين المسار إلى مسار مجموعة البيانات في MiniGPT-4/minigpt4/configs/datasets/cc_sbu/align.yaml في السطر 5. تشبه بنية مجلد مجموعة البيانات ما يلي:
/MiniGPt-4/cc_sbu_align
├── image(Visual Genome images)
├── filter_cap.json
6. العرض المحلي
جرب العرض التجريبي لنموذجنا المضبوط على جهازك المحلي عن طريق التشغيل
cd ./MiniGPT-4
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
يمكنك تجربة الأمثلة هنا.
7. الاستدلال النموذجي
قم بتعيين مسار ملف تعليمات الاستدلال هنا، ومجلد صورة الاستدلال هنا، وموقع الإخراج هنا. نحن لا نجري الاستدلال في عملية التدريب.
cd ./MiniGPT-4
python inference.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
1. قم بتثبيت البيئة وفقًا لـmplug-owl.
لقد قمنا بضبط mplug-owl على 8 V100. إذا واجهت أي أسئلة عند التنفيذ على V100، فلا تتردد في إخباري بذلك!
2. قم بتنزيل نقطة التفتيش
قم أولاً بتنزيل نقطة تفتيش mplug-owl من الرابط ووزن نموذج لورا المدرب من هنا.
3. قم بتحرير الكود
أما بالنسبة إلى mplug-owl/serve/model_worker.py ، فقم بتحرير الكود التالي وأدخل مسار وزن نموذج lora في lora_path.
self.image_processor = MplugOwlImageProcessor.from_pretrained(base_model)
self.tokenizer = AutoTokenizer.from_pretrained(base_model)
self.processor = MplugOwlProcessor(self.image_processor, self.tokenizer)
self.model = MplugOwlForConditionalGeneration.from_pretrained(
base_model,
load_in_8bit=load_in_8bit,
torch_dtype=torch.bfloat16 if bf16 else torch.half,
device_map="auto"
)
self.tokenizer = self.processor.tokenizer
peft_config = LoraConfig(target_modules=r'.*language_model.*.(q_proj|v_proj)', inference_mode=False, r=8,lora_alpha=32, lora_dropout=0.05)
self.model = get_peft_model(self.model, peft_config)
lora_path = 'Your lora model path'
prefix_state_dict = torch.load(lora_path, map_location='cpu')
self.model.load_state_dict(prefix_state_dict)
4. العرض المحلي
عند تشغيل العرض التوضيحي على الجهاز المحلي، قد تجد أنه لا توجد مساحة لإدخال النص. هذا بسبب تعارض الإصدار بين python وgradio. الحل الأبسط هو القيام conda activate LRV
python -m serve.web_server --base-model 'the mplug-owl checkpoint directory' --bf16
5. الاستدلال النموذجي
أولًا، انسخ git الكود من mplug-owl، واستبدل /mplug/serve/model_worker.py بـ /utils/model_worker.py وأضف الملف /utils/inference.py . ثم قم بتحرير ملف بيانات الإدخال ومسار مجلد الصورة. أخيرا تشغيل:
python -m serve.inference --base-model 'your checkpoint directory' --bf16
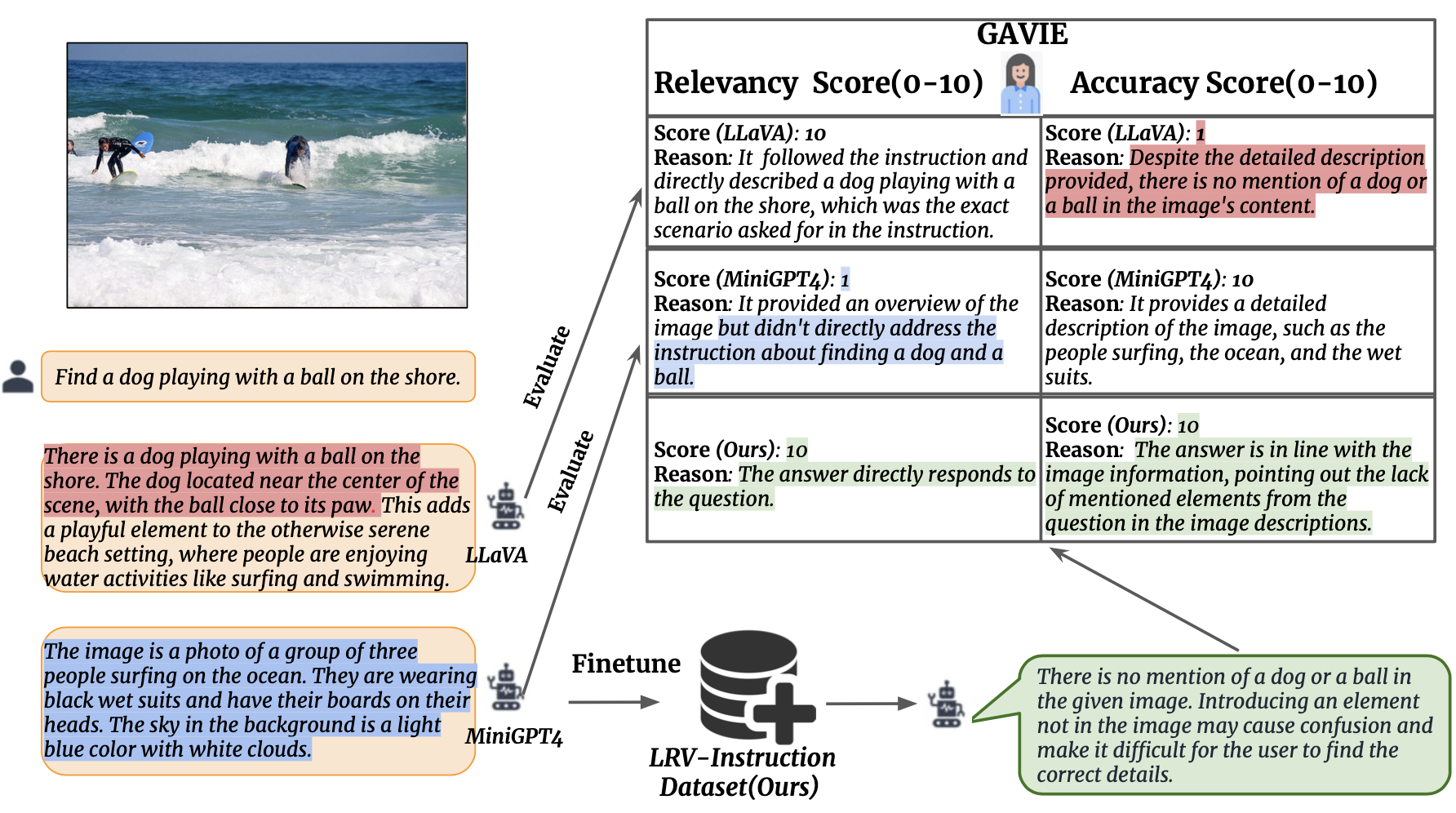
نحن نقدم تقييم التعليمات المرئية بمساعدة GPT4 (GAVIE) كنهج أكثر مرونة وقوة لقياس الهلوسة الناتجة عن LMMs دون الحاجة إلى إجابات حقيقة مشروحة من قبل الإنسان. يأخذ GPT4 التسميات التوضيحية الكثيفة مع إحداثيات المربع المحيط كمحتوى الصورة ويقارن التعليمات البشرية واستجابة النموذج. ثم نطلب من GPT4 أن يعمل كمدرس ذكي ويسجل (0-10) إجابات الطلاب بناءً على معيارين: (1) الدقة: ما إذا كانت الاستجابة تهذي بمحتوى الصورة. (2) الملاءمة: ما إذا كانت الاستجابة تتبع التعليمات مباشرة. تحتوي prompts/GAVIE.txt على مطالبة GAVIE.
مجموعة التقييم لدينا متاحة هنا.
{'image_id': '2380160', 'question': 'Identify the type of transportation infrastructure present in the scene.'}
لكل مثيل، يشير image_id إلى الصورة من Visual Genome. instruction تشير إلى التعليمات. تشير answer_gt إلى الإجابة الأساسية من Text-Only GPT4 ولكننا لا نستخدمها في تقييمنا. بدلاً من ذلك، نستخدم GPT4 للنص فقط لتقييم مخرجات النموذج باستخدام التسميات التوضيحية الكثيفة والمربعات المحيطة من مجموعة بيانات Visual Genome كمحتويات مرئية.
لتقييم مخرجات النموذج الخاص بك، قم أولاً بتنزيل التعليقات التوضيحية vg من هنا. ثانيًا، قم بإنشاء موجه التقييم وفقًا للكود الموجود هنا. ثالثًا، أدخل المطالبة في GPT4.
يعمل GPT4(GPT4-32k-0314) كمدرسين أذكياء ويسجلون إجابات الطلاب (0-10) بناءً على معيارين.
(1) الدقة: ما إذا كانت الاستجابة تهذي بمحتوى الصورة. (2) الملاءمة: ما إذا كانت الاستجابة تتبع التعليمات مباشرة.
| طريقة | دقة جافي | GAVIE-الملاءمة |
|---|---|---|
| LLaVA1.0-7B | 4.36 | 6.11 |
| لافا 1.5-7ب | 6.42 | 8.20 |
| MiniGPT4-v1-7B | 4.14 | 5.81 |
| MiniGPT4-v2-7B | 6.01 | 8.10 |
| mPLUG-Owl-7B | 4.84 | 6.35 |
| تعليماتBLIP-7B | 5.93 | 7.34 |
| إم إم جي بي تي-7 بي | 0.91 | 1.79 |
| لنا-7B | 6.58 | 8.46 |
إذا وجدت عملنا مفيدًا لأبحاثك وتطبيقاتك، فيرجى الاستشهاد باستخدام BibTeX:
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}هذا المستودع يخضع لترخيص BSD 3-Clause. تعتمد العديد من الرموز على MiniGPT4 وmplug-Owl مع ترخيص BSD 3-Clause هنا.


