PointLLM
1.0.0
 PointLLM: تمكين نماذج اللغات الكبيرة لفهم Point Clouds
PointLLM: تمكين نماذج اللغات الكبيرة لفهم Point Clouds رونسن شو شياو لونغ وانغ تاي وانغ ييلون تشين جيانغمياو بانغ * داهوا لين
الجامعة الصينية في هونغ كونغ شنغهاي مختبر الذكاء الاصطناعي جامعة تشجيانغ

PointLLM غير متصل! جربه على http://101.230.144.196 أو على OpenXLab/PointLLM.
يمكنك الدردشة مع PointLLM حول نماذج مجموعة بيانات Objaverse أو حول السحب النقطية الخاصة بك!
من فضلك لا تتردد في إخبارنا إذا كان لديك أي ملاحظات! ؟
| الحوار 1 | الحوار 2 | الحوار 3 | الحوار 4 |
|---|---|---|---|
 |  |  |  |
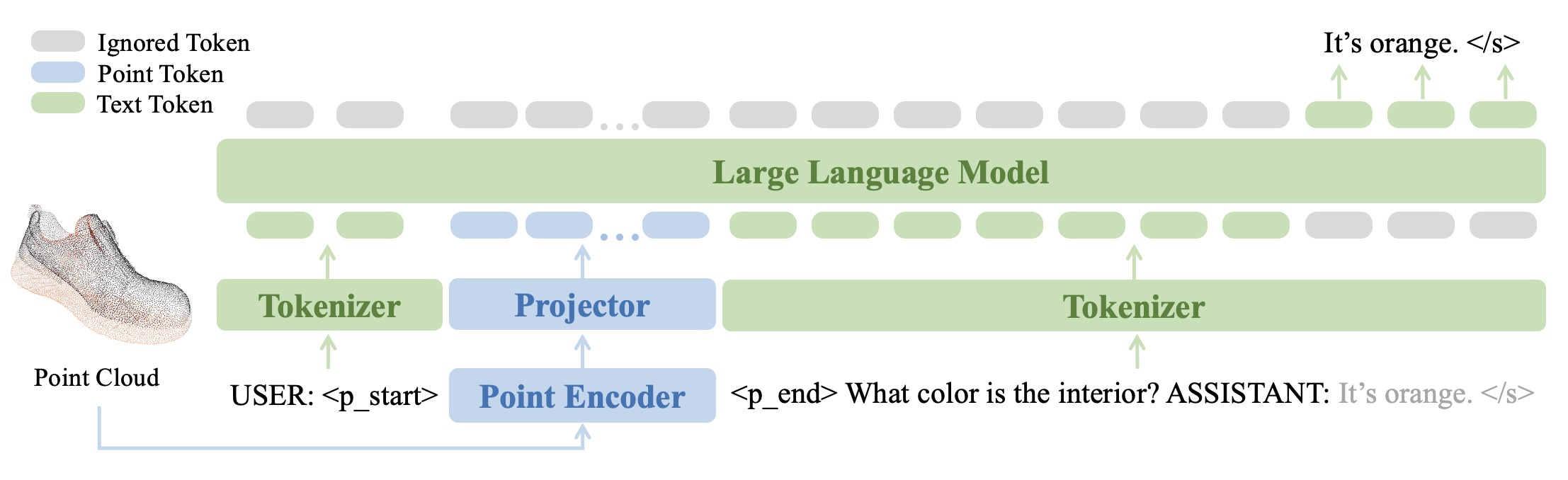
يرجى الرجوع إلى ورقتنا لمزيد من النتائج.
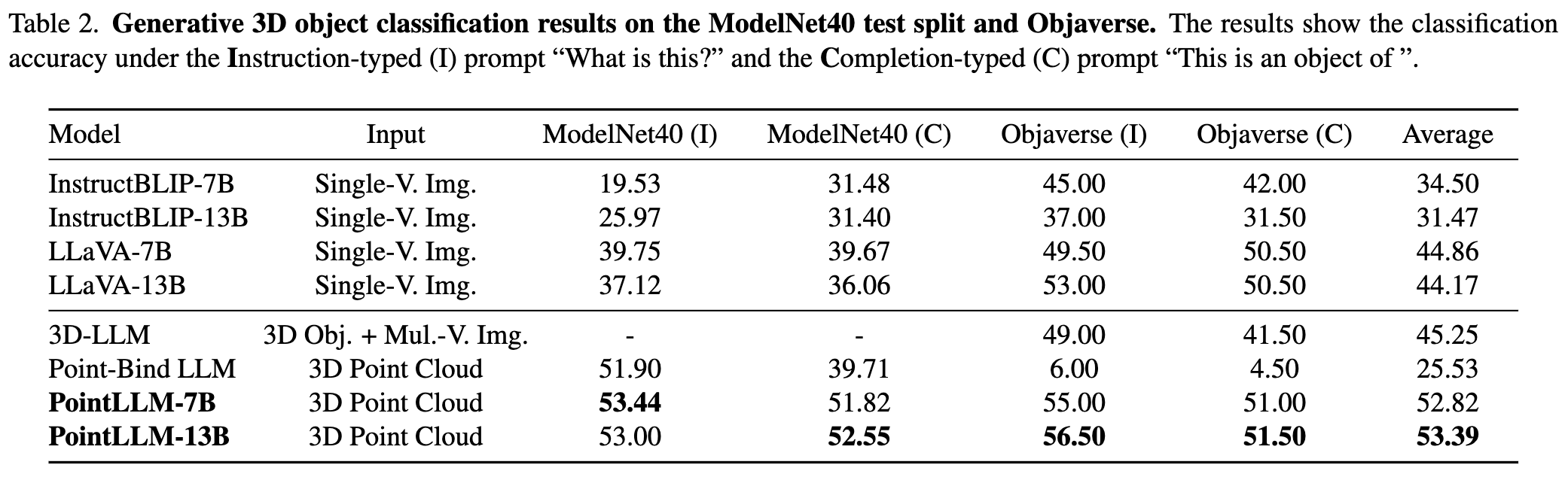
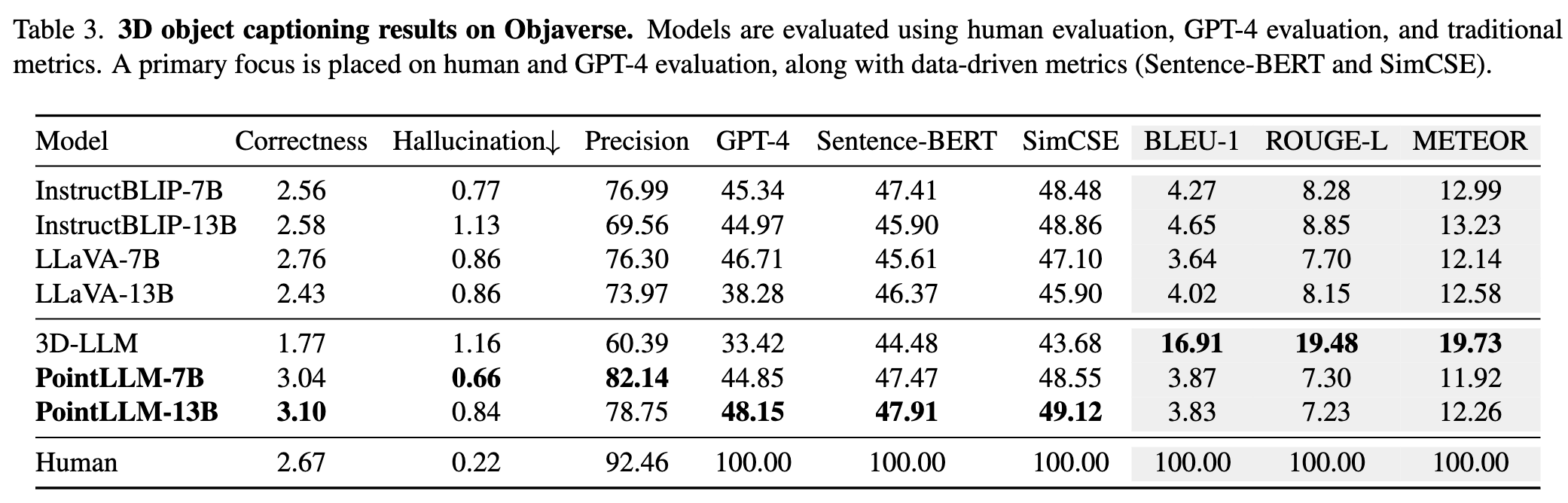
يرجى الرجوع إلى ورقتنا لمزيد من النتائج.

نقوم باختبار أكوادنا في البيئة التالية:
للبدء:
git clone [email protected]:OpenRobotLab/PointLLM.git
cd PointLLMconda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn8192_npy يحتوي على 660 ألف نقطة من الملفات السحابية المسماة {Objaverse_ID}_8192.npy . كل ملف عبارة عن مصفوفة numpy بأبعاد (8192، 6)، حيث تكون الأبعاد الثلاثة الأولى هي xyz والأبعاد الثلاثة الأخيرة هي rgb في النطاق [0، 1]. cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gzPointLLM ، قم بإنشاء data المجلد وإنشاء رابط بسيط للملف غير المضغوط في الدليل. cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_dataPointLLM/data ، قم بإنشاء دليل باسم anno_data .anno_data . يجب أن يبدو الدليل كما يلي: PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.jsonPointLLM_brief_description_660K_filtered.json من PointLLM_brief_description_660K.json عن طريق إزالة 3000 كائن قمنا بحجزها كمجموعة التحقق من الصحة. إذا كنت تريد إعادة إنتاج النتائج في بحثنا، فيجب عليك استخدام PointLLM_brief_description_660K_filtered.json للتدريب. يحتوي PointLLM_complex_instruction_70K.json على كائنات من مجموعة التدريب.pointllm/data/data_generation/system_prompt_gpt4_0613.txt . PointLLM_brief_description_val_200_GT.json المرجعي الذي نستخدمه للمعايير في مجموعة بيانات Objaverse هنا، ثم ضعه في PointLLM/data/anno_data . نحن نقدم أيضًا معرفات الكائنات البالغ عددها 3000 والتي نقوم بتصفيتها أثناء التدريب هنا والمرجع المقابل لها هنا، والتي يمكن استخدامها لتقييم جميع الكائنات البالغ عددها 3000 كائن.modelnet40_data في PointLLM/data . قم بتنزيل تقسيم الاختبار للسحب النقطية ModelNet40 modelnet40_test_8192pts_fps.dat هنا ووضعه في PointLLM/data/modelnet40_data .PointLLM ، قم بإنشاء دليل باسم checkpoints .checkpoints . cd PointLLM
scripts/PointLLM_train_stage1.shscripts/PointLLM_train_stage2.shعادة، لا يتعين عليك الاهتمام بالمحتويات التالية. إنها مخصصة فقط لإعادة إنتاج النتائج في ورقتنا v1 (PointLLM-v1.1). إذا كنت تريد المقارنة مع نماذجنا أو استخدام نماذجنا للمهام النهائية، فيرجى استخدام PointLLM-v1.2 (راجع ورقتنا v2)، التي تتمتع بأداء أفضل.
يستخدم الإصداران 1.1 و1.2 من PointLLM أجهزة تشفير وأجهزة عرض نقطية مختلفة قليلًا ومدربة مسبقًا. إذا كنت تريد إعادة إنتاج PointLLM v1.1، فقم بتحرير ملف config.json في دليل LLM الأولي وأوزان أداة تشفير النقاط، على سبيل المثال، vim checkpoints/PointLLM_7B_v1.1_init/config.json .
قم بتغيير المفتاح "point_backbone_config_name" لتحديد تكوين آخر لجهاز تشفير النقاط:
# change from
" point_backbone_config_name " : " PointTransformer_8192point_2layer " # v1.2
# to
" point_backbone_config_name " : " PointTransformer_base_8192point " , # v1.1 قم بتحرير مسار نقطة التفتيش الخاصة بجهاز تشفير النقطة في scripts/train_stage1.sh :
# change from
point_backbone_ckpt= $model_name_or_path /point_bert_v1.2.pt # v1.2
# to
point_backbone_ckpt= $model_name_or_path /point_bert_v1.1.pt # v1.1torch.float32 للدردشة حول النماذج ثلاثية الأبعاد لـ Objaverse. سيتم تنزيل نقاط التفتيش النموذجية تلقائيًا. يمكنك أيضًا تنزيل نقاط التحقق النموذجية يدويًا وتحديد مساراتها. هنا مثال: cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32 يمكنك أيضًا تعديل الرموز بسهولة لاستخدام السحب النقطية بخلاف تلك الموجودة في Objaverse، طالما أن السحب النقطية المُدخلة إلى النموذج لها أبعاد (N، 6)، حيث تكون الأبعاد الثلاثة الأولى هي xyz والأبعاد الثلاثة الأخيرة هي rgb ( في النطاق [0، 1]). يمكنك أخذ عينات من السحب النقطية للحصول على 8192 نقطة، حيث تم تدريب نموذجنا على مثل هذه السحب النقطية.
يوضح الجدول التالي متطلبات وحدة معالجة الرسومات للنماذج وأنواع البيانات المختلفة. نوصي باستخدام torch.bfloat16 إن أمكن، والذي يستخدم في التجارب في ورقتنا.
| نموذج | نوع البيانات | ذاكرة وحدة معالجة الرسومات |
|---|---|---|
| بوينتLLM-7B | torch.float16 | 14 جيجابايت |
| بوينتLLM-7B | torch.float32 | 28 جيجابايت |
| بوينتLLM-13B | torch.float16 | 26 جيجابايت |
| بوينتLLM-13B | torch.float32 | 52 جيجابايت |
cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data cd PointLLM
export PYTHONPATH= $PWD
# Open Vocabulary Classification on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # or --prompt_index 1
# Object captioning on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # or --prompt_index 1{model_name}/evaluation كإملاء بالتنسيق التالي: {
" prompt " : " " ,
" results " : [
{
" object_id " : " " ,
" ground_truth " : " " ,
" model_output " : " " ,
" label_name " : " " # only for classification on modelnet40
}
]
} cd PointLLM
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
# Open Vocabulary Classification on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Object captioning on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15Ctrl+C . سيؤدي هذا إلى حفظ النتائج المؤقتة. في حالة حدوث خطأ أثناء التقييم، سيقوم البرنامج النصي أيضًا بحفظ الحالة الحالية. يمكنك استئناف التقييم من حيث توقف عن طريق تشغيل نفس الأمر مرة أخرى.{model_name}/evaluation كإملاء آخر. يتم شرح بعض المقاييس على النحو التالي: " average_score " : The GPT-evaluated captioning score we report in our paper.
" accuracy " : The classification accuracy we report in our paper, including random choices made by ChatGPT when model outputs are vague or ambiguous and ChatGPT outputs " INVALID " .
" clean_accuracy " : The classification accuracy after removing those " INVALID " outputs.
" total_predictions " : The number of predictions.
" correct_predictions " : The number of correct predictions.
" invalid_responses " : The number of " INVALID " outputs by ChatGPT.
# Some other statistics for calling OpenAI API
" prompt_tokens " : The total number of tokens of the prompts for ChatGPT/GPT-4.
" completion_tokens " : The total number of tokens of the completion results from ChatGPT/GPT-4.
" GPT_cost " : The API cost of the whole evaluation process, in US Dollars ?.--start_eval وتحديد --gpt_type . على سبيل المثال: python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_outputمساهمات المجتمع موضع ترحيب!؟ إذا كنت بحاجة إلى أي دعم، فلا تتردد في فتح مشكلة أو الاتصال بنا.
إذا وجدت عملنا وقاعدة التعليمات البرمجية هذه مفيدة، فيرجى التفكير في تمييز هذا الريبو بنجمة؟ واستشهد:
@inproceedings { xu2024pointllm ,
title = { PointLLM: Empowering Large Language Models to Understand Point Clouds } ,
author = { Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua } ,
booktitle = { ECCV } ,
year = { 2024 }
}
هذا العمل خاضع للرخصة الدولية Creative Commons Attribution-NonCommercial-ShareAlike 4.0.
معًا، دعونا نجعل LLM للتقنية ثلاثية الأبعاد أمرًا رائعًا!


