thumb
1.0.0
مكتبة اختبار سريعة بسيطة لLLMs.
pip install thumb
import os
import thumb
# Set your API key: https://platform.openai.com/account/api-keys
os . environ [ "OPENAI_API_KEY" ] = "YOUR_API_KEY_HERE"
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])يتم تشغيل كل مطالبة 10 مرات بشكل غير متزامن بشكل افتراضي، وهو أسرع بحوالي 9 مرات من تشغيلها بشكل تسلسلي. في Jupyter Notebooks، يتم عرض واجهة مستخدم بسيطة لاستجابات التصنيف الأعمى (لا ترى المطالبة التي أدت إلى الاستجابة).
بمجرد تقييم جميع الإجابات، يتم حساب إحصائيات الأداء التالية مقسمة حسب قالب المطالبة:
avg_score مقدار التعليقات الإيجابية كنسبة مئوية من جميع عمليات التشغيلavg_tokens : عدد الرموز المميزة التي تم استخدامها عبر الموجه والاستجابةavg_cost : تقدير لمقدار تكلفة التشغيل في المتوسط يتم عرض تقرير بسيط في دفتر الملاحظات، ويتم حفظ البيانات الكاملة في ملف CSV thumb/ThumbTest-{TestID}.csv .

حالات الاختبار هي عندما تريد اختبار قالب مطالبة بمتغيرات إدخال مختلفة. على سبيل المثال، إذا كنت تريد اختبار قالب مطالبة يتضمن متغيرًا لاسم ممثل كوميدي، فيمكنك إعداد حالات اختبار لممثلين كوميديين مختلفين.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke in the style of {comedian}"
prompt_b = "tell me a family friendly joke in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "comedian" : "chris rock" },
{ "comedian" : "ricky gervais" },
{ "comedian" : "robin williams" }
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )سيتم تشغيل كل حالة اختبار مقابل كل قالب موجه، لذا في هذا المثال، ستحصل على 6 مجموعات (3 حالات اختبار × 2 قالب مطالبة)، والتي سيتم تشغيل كل منها 10 مرات (60 إجمالي استدعاءات لـ OpenAI). يجب أن تتضمن كل حالة اختبار قيمة لكل متغير في قالب المطالبة.
قد تحتوي الموجهات على متغيرات متعددة في كل حالة اختبار. على سبيل المثال، إذا كنت تريد اختبار قالب مطالبة يتضمن متغيرًا لاسم ممثل كوميدي وموضوع نكتة، فيمكنك إعداد حالات اختبار لممثلين كوميديين وموضوعات مختلفة.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke about {subject} in the style of {comedian}"
prompt_b = "tell me a family friendly joke about {subject} in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "joe biden" , "comedian" : "ricky gervais" },
{ "subject" : "donald trump" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "ricky gervais" },
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )يتم اختبار كل حالة مقابل كل موجه، من أجل الحصول على مقارنة عادلة لأداء كل موجه بالنظر إلى نفس بيانات الإدخال. مع 4 حالات اختبار ومطالبتين، ستحصل على 8 مجموعات (4 حالات اختبار × 2 قوالب مطالبات)، والتي سيتم تشغيل كل منها 10 مرات (80 إجمالي استدعاءات لـ OpenAI).
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], models = [ "gpt-4" , "gpt-3.5-turbo" ])سيؤدي هذا إلى تشغيل كل موجه مقابل كل نموذج، من أجل الحصول على مقارنة عادلة لأداء كل موجه بالنظر إلى نفس بيانات الإدخال. مع موجهين ونموذجين، ستحصل على 4 مجموعات (مطالبتان × نموذجان)، والتي سيتم تشغيل كل منها 10 مرات (إجمالي 40 استدعاء لـ OpenAI).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , "tell me a funny joke about {subject}" ]
prompt_b = [ system_message , "tell me a hillarious joke {subject}" ]
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases ) يمكن أن تكون المطالبات عبارة عن سلسلة أو مجموعة من السلاسل. إذا كان الموجه عبارة عن مصفوفة، فسيتم استخدام السلسلة الأولى كرسالة نظام، وتتناوب بقية المطالبات بين الرسائل البشرية والمساعد ( [system, human, ai, human, ai, ...] ). يعد هذا مفيدًا لاختبار المطالبات التي تتضمن رسالة نظام، أو التي تستخدم التسخين المسبق (إدراج رسائل سابقة في الدردشة لتوجيه الذكاء الاصطناعي نحو السلوك المطلوب).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , # system
"tell me a funny joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
prompt_b = [ system_message , # system
"tell me a hillarious joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
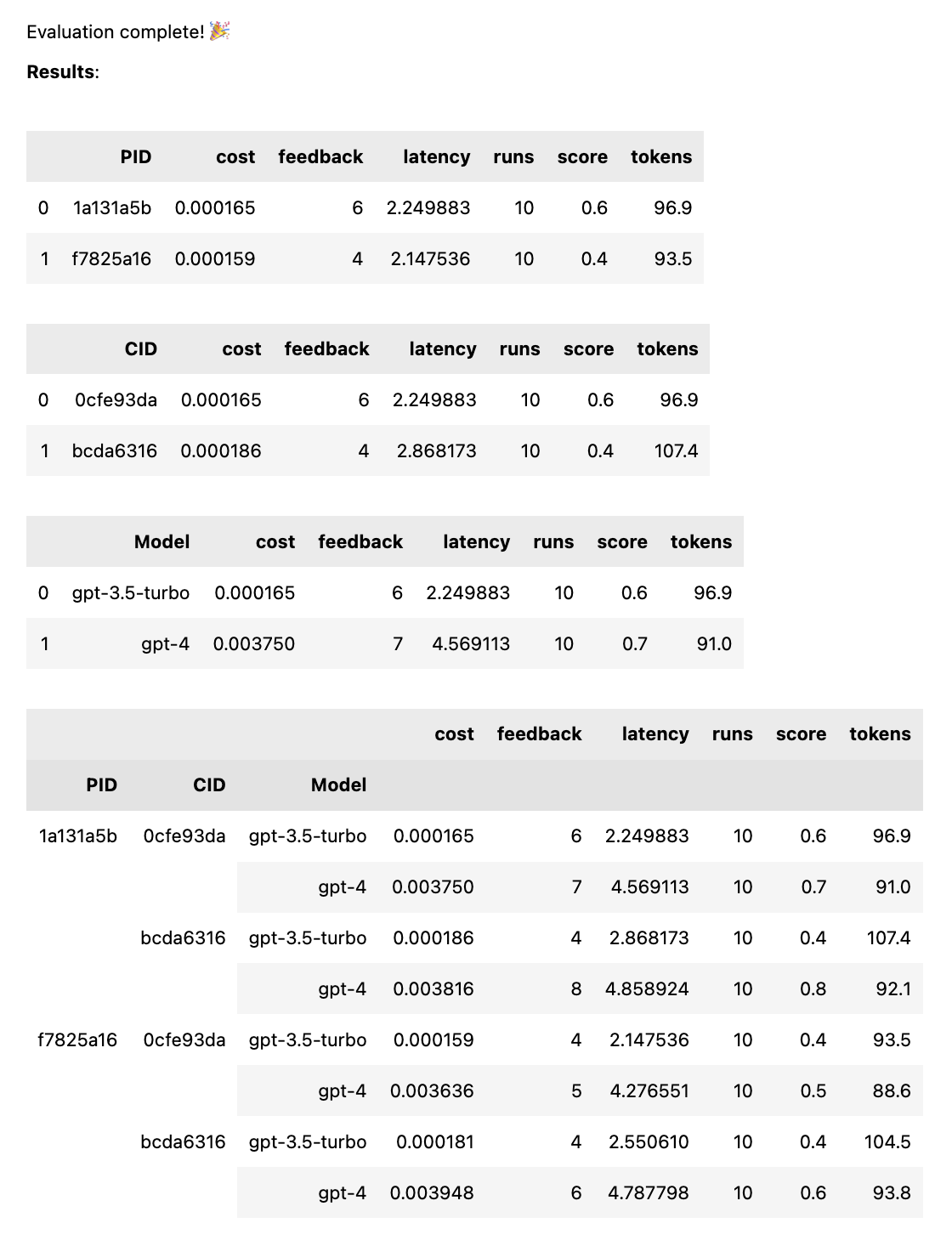
test = thumb . test ([ prompt_a , prompt_b ], cases )عند اكتمال الاختبار، تحصل على تقرير تقييم كامل، مقسمًا حسب PID وCID والنموذج، بالإضافة إلى تقرير شامل مقسم حسب جميع المجموعات. إذا قمت باختبار نموذج واحد أو حالة واحدة فقط، فسيتم إسقاط هذه الأعطال. يعرض التقرير مفتاحًا في الأسفل لمعرفة المعرف الذي يتوافق مع أي مطالبة أو حالة.
تأخذ وظيفة thumb.test المعلمات التالية:
None )10 )gpt-3.5-turbo ])True ) إذا كان لديك 10 عمليات تشغيل اختبار مع نموذجين للمطالبة و3 حالات اختبار، فهذا يعني 10 x 2 x 3 = 60 استدعاءًا لـ OpenAI. كن حذرًا: خاصة مع GPT-4، يمكن أن تتراكم التكاليف بسرعة!
يتم تمكين تتبع Langchain إلى LangSmith تلقائيًا إذا تم تعيين LANGCHAIN_API_KEY كمتغير بيئة (اختياري).
تقوم الدالة .test() بإرجاع كائن ThumbTest . يمكنك إضافة المزيد من المطالبات أو الحالات إلى الاختبار، أو تشغيله مرات إضافية. يمكنك أيضًا إنشاء بيانات الاختبار وتقييمها وتصديرها في أي وقت.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])
# add more prompts
test . add_prompts ([ "tell me a knock knock joke" , "tell me a knock knock joke about {subject}" ])
# add more cases
test . add_cases ([{ "subject" : "joe biden" }, { "subject" : "donald trump" }])
# run each prompt and case 5 more times
test . add_runs ( 5 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () يحصل كل قالب موجه على نفس بيانات الإدخال من كل حالة اختبار، ولكن لا يحتاج الموجه إلى استخدام كافة المتغيرات في حالة الاختبار. كما في المثال أعلاه، لا تستخدم المطالبة tell me a knock knock joke متغير subject ، ولكن لا يزال يتم إنشاؤها مرة واحدة (بدون متغيرات) لكل حالة اختبار.
يتم تخزين بيانات الاختبار مؤقتًا في ملف JSON محلي thumb/.cache/{TestID}.json بعد إنشاء كل مجموعة من عمليات التشغيل لمجموعة الموجهات والحالة. إذا تمت مقاطعة الاختبار الخاص بك، أو كنت تريد الإضافة إليه، فيمكنك استخدام وظيفة thumb.load لتحميل بيانات الاختبار من ذاكرة التخزين المؤقت.
# load a previous test
test_id = "abcd1234" # replace with your test id
test = thumb . load ( f"thumb/.cache/ { test_id } .json" )
# run each prompt and case 2 more times
test . add_runs ( 2 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () يتم تخزين كل تشغيل لكل مجموعة من الموجهات وحالة الأحرف في الكائن (والذاكرة المؤقتة)، وبالتالي فإن استدعاء test.generate() مرة أخرى لن يؤدي إلى إنشاء أي استجابات جديدة إذا لم تتم إضافة المزيد من المطالبات أو الحالات أو عمليات التشغيل. وبالمثل، فإن استدعاء test.evaluate() مرة أخرى لن يؤدي إلى إعادة تقييم الإجابات التي قمت بتقييمها بالفعل، وسيعيد عرض النتائج ببساطة إذا انتهى الاختبار.
الفرق بين الأشخاص الذين يستخدمون ChatGPT والذين يستخدمون الذكاء الاصطناعي في الإنتاج هو التقييم. يستجيب طلاب LLM بطريقة غير حتمية، ولذلك من المهم اختبار الشكل الذي تبدو عليه النتائج عند توسيع نطاقها عبر مجموعة واسعة من السيناريوهات. بدون إطار عمل للتقييم، ستظل تخمن بشكل أعمى ما الذي ينجح في مطالباتك (أو لا).
يقوم المهندسون الفوريون الجادون باختبار وتعلم المدخلات التي تؤدي إلى مخرجات مفيدة أو مرغوبة، بشكل موثوق وعلى نطاق واسع. تسمى هذه العملية بالتحسين الفوري، وهي تبدو كما يلي:
يسد اختبار الإبهام الفجوة بين آليات التقييم المهنية واسعة النطاق، والتحفيز الأعمى من خلال التجربة والخطأ. إذا كنت تقوم بنقل موجه إلى بيئة إنتاج، فإن استخدام thumb لاختبار موجهك يمكن أن يساعدك في التعرف على الحالات المتطورة والحصول على تعليقات مبكرة من المستخدم أو الفريق حول النتائج.
يقوم هؤلاء الأشخاص ببناء thumb من أجل المتعة في أوقات فراغهم. ؟
مطرقة جبل |


