Q Bench
1.0.0
كيف تعمل LLMs متعددة الوسائط على رؤية الكمبيوتر منخفضة المستوى؟
هاونينغ وو 1 * ، تسيتشنغ تشانغ 2 * ، إيرلي تشانغ 1 * ، تشاوفينغ تشين 1 ، ليانغ لياو 1 ،
أنان وانغ 1 ، تشوني لي 2 ، وينكسيو صن 3 ، تشيونغ يان 3 ، غوانغتاو تشاي 2 ، ويسي لين 1 #
1 جامعة نانيانغ التكنولوجية، 2 جامعة شنغهاي جياوتونغ، 3 أبحاث سينستايم
* المساهمة المتساوية. # الكاتب المقابل.
أضواء كاشفة ICLR2024
ورق | صفحة المشروع | جيثب | البيانات (LLVisionQA) | البيانات (LLDescribe) |质衡 (الصينية-Q-Bench)


يتضمن Q-Bench المقترح ثلاثة مجالات للرؤية ذات المستوى المنخفض: الإدراك (A1)، والوصف (A2)، والتقييم (A3).
بالنسبة للإدراك (A1) /الوصف (A2)، نقوم بجمع مجموعتي بيانات مرجعيتين LLVisionQA/LLDescribe.
نحن منفتحون على التقييم القائم على التقديم للمهمتين. تفاصيل التقديم هي كما يلي.
بالنسبة للتقييم (A3)، نظرًا لأننا نستخدم مجموعات البيانات العامة ، فإننا نقدم رمز تقييم تجريدي لـ MLLMs التعسفي ليختبره أي شخص.
datasets بالنسبة لـ Q-Bench-A1 (مع أسئلة الاختيار من متعدد)، قمنا بتحويلها إلى مجموعات بيانات بتنسيق HF يمكن تنزيلها واستخدامها تلقائيًا مع واجهة برمجة datasets . يرجى الرجوع إلى التعليمات التالية:
مجموعات بيانات تثبيت النقطة
من مجموعات البيانات import Load_datasetds =load_dataset("q-future/Q-Bench-HF")print(ds["dev"][0])### {'id': 0,### 'image': <PIL .JpegImagePlugin.JpegImageFile image mode=RGB size=4160x3120>,### 'question': 'كيف هي إضاءة هذا بناء؟",### 'option0': 'High',### 'option1': 'Low',### 'option2': 'Medium',### 'option3': 'N/A', ### 'question_type': 2,### 'question_concern': 3,### 'correct_choice': 'B'} من مجموعات البيانات import Load_datasetds =load_dataset("q-future/Q-Bench2-HF")print(ds["dev"][0])### {'id': 0,### 'image1': <PIL .Image.Image image mode=RGB size=4032x3024>,### 'image2': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=864x1152>,### 'question': 'مقارنة بالصورة الأولى، ما مدى وضوح الصورة الثانية؟',### 'option0': 'المزيد من الضبابية',### 'option1 ': 'أوضح',### 'option2': 'حول نفس الشيء',### 'option3': 'N/A',### 'question_type': 2,### 'سؤال_مقلق': 0,### 'الاختيار_الصحيح': 'ب'}[2024/8/8] تم قبول جزء مهمة مقارنة الرؤية منخفضة المستوى من Q-bench+ (يشار إليه أيضًا باسم Q-Bench2) للتو من قبل TPAMI! تعال واختبر MLLM الخاص بك باستخدام Q-bench+_Dataset.
[2024/8/1] تم إصدار Q-Bench على VLMEvalKit، تعال واختبر LMM الخاص بك باستخدام أمر واحد مثل `python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose".
[2024/6/17] انضم الآن Q-Bench و Q-Bench2 (Q-bench+) و A-Bench إلى lmms-eval، مما يجعل اختبار LMM أسهل !!
[2024/6/3] Github repo لـ A-Bench متاح عبر الإنترنت. هل تريد معرفة ما إذا كان LMM الخاص بك خبيرًا في تقييم الصور التي تم إنشاؤها بواسطة الذكاء الاصطناعي؟ تعال واختبر على A-Bench !!
[3/1] نحن نصدر تعليمات مشتركة ، نحو مقارنة جودة بصرية مفتوحة هنا. مزيد من التفاصيل تأتي قريبا.
[2/27] تم قبول عملنا Q-Insturct من قبل CVPR 2024، حاول معرفة التفاصيل حول كيفية إرشاد MLLMs على الرؤية منخفضة المستوى!
[2/23] تم الآن إصدار جزء مهمة مقارنة الرؤية منخفضة المستوى من Q-bench+ على Q-bench+(Dataset)!
[2/10] نحن نقوم بإصدار Q-bench+ الممتد، والذي يتحدى MLLMs مع كل من الصور الفردية وأزواج الصور على الرؤية منخفضة المستوى. لوحة المتصدرين موجودة في الموقع، تحقق من قدرة الرؤية منخفضة المستوى لموظفي الامتيازات البحرية المفضلين لديك!! مزيد من التفاصيل قريبا.
[1/16] تم قبول عملنا "Q-Bench: معيار مرجعي لنماذج الأساس ذات الأغراض العامة في الرؤية منخفضة المستوى" من قبل ICLR2024 كعرض تقديمي مميز .

نحن نختبر ثلاثة نماذج لواجهة برمجة التطبيقات (API) قريبة المصدر، وهي GPT-4V-Turbo ( gpt-4-vision-preview ، لتحل محل نتائج الإصدار القديم التي لم تعد متوفرة GPT-4V)، وGemini Pro ( gemini-pro-vision ) وQwen -VL-Plus ( qwen-vl-plus ). تم تحسين GPT-4V قليلاً مقارنة بالإصدار الأقدم، ولا يزال يتصدر أداء جميع MLLMs وأداء الإنسان على مستوى المبتدئين تقريبًا. يأتي Gemini Pro وQwen-VL-Plus في الخلف، ولا يزالان أفضل من أفضل MLLMs مفتوحة المصدر (0.65 بشكل عام).
تم التحديث بتاريخ [2024/7/18]، يسعدنا إصدار أداء SOTA الجديد لـ BlueImage-GPT (مصدر قريب).
الإدراك، A1-مفرد
| اسم المشارك | نعم أو لا | ماذا | كيف | تشويه | آحرون | تشويه في السياق | الآخرين في السياق | إجمالي |
|---|---|---|---|---|---|---|---|---|
كوين-VL-بلس ( qwen-vl-plus ) | 0.7574 | 0.7325 | 0.5733 | 0.6488 | 0.7324 | 0.6867 | 0.7056 | 0.6893 |
BlueImage-GPT ( from VIVO New Champion ) | 0.8467 | 0.8351 | 0.7469 | 0.7819 | 0.8594 | 0.7995 | 0.8240 | 0.8107 |
الجوزاء برو ( gemini-pro-vision ) | 0.7221 | 0.7300 | 0.6645 | 0.6530 | 0.7291 | 0.7082 | 0.7665 | 0.7058 |
GPT-4V-Turbo ( gpt-4-vision-preview ) | 0.7722 | 0.7839 | 0.6645 | 0.7101 | 0.7107 | 0.7936 | 0.7891 | 0.7410 |
| GPT-4V ( الإصدار القديم ) | 0.7792 | 0.7918 | 0.6268 | 0.7058 | 0.7303 | 0.7466 | 0.7795 | 0.7336 |
| إنسان-1-ناشئ | 0.8248 | 0.7939 | 0.6029 | 0.7562 | 0.7208 | 0.7637 | 0.7300 | 0.7431 |
| إنسان-2-كبار | 0.8431 | 0.8894 | 0.7202 | 0.7965 | 0.7947 | 0.8390 | 0.8707 | 0.8174 |
الإدراك، A1-زوج
| اسم المشارك | نعم أو لا | ماذا | كيف | تشويه | آحرون | يقارن | مشترك | إجمالي |
|---|---|---|---|---|---|---|---|---|
كوين-VL-بلس ( qwen-vl-plus ) | 0.6685 | 0.5579 | 0.5991 | 0.6246 | 0.5877 | 0.6217 | 0.5920 | 0.6148 |
كوين-VL-ماكس ( qwen-vl-max ) | 0.6765 | 0.6756 | 0.6535 | 0.6909 | 0.6118 | 0.6865 | 0.6129 | 0.6699 |
BlueImage-GPT ( from VIVO New Champion ) | 0.8843 | 0.8033 | 0.7958 | 0.8464 | 0.8062 | 0.8462 | 0.7955 | 0.8348 |
الجوزاء برو ( gemini-pro-vision ) | 0.6578 | 0.5661 | 0.5674 | 0.6042 | 0.6055 | 0.6046 | 0.6044 | 0.6046 |
GPT-4V ( gpt-4-vision ) | 0.7975 | 0.6949 | 0.8442 | 0.7732 | 0.7993 | 0.8100 | 0.6800 | 0.7807 |
| الإنسان على مستوى المبتدئين | 0.7811 | 0.7704 | 0.8233 | 0.7817 | 0.7722 | 0.8026 | 0.7639 | 0.8012 |
| إنسان رفيع المستوى | 0.8300 | 0.8481 | 0.8985 | 0.8313 | 0.9078 | 0.8655 | 0.8225 | 0.8548 |
لقد قمنا أيضًا بتقييم العديد من النماذج الجديدة مفتوحة المصدر مؤخرًا، وسنصدر نتائجها قريبًا.
نوفر الآن طريقتين لتنزيل مجموعات البيانات (LLVisionQA&LLDescribe)
عبر إصدار GitHub: يرجى الاطلاع على إصدارنا للحصول على التفاصيل.
عبر Huggingface Datasets: يرجى الرجوع إلى ملاحظات إصدار البيانات لتنزيل الصور.
يوصى بشدة بتحويل النموذج الخاص بك إلى تنسيق Huggingface لاختبار هذه البيانات بسلاسة. راجع أمثلة البرامج النصية لـ IDEFICS-9B-Instruct الخاصة بـ Huggingface كمثال، وقم بتعديلها لنموذجك المخصص لاختبارها على النموذج الخاص بك.
يرجى إرسال بريد إلكتروني إلى [email protected] لإرسال النتيجة بتنسيق json.
يمكنك أيضًا إرسال النموذج الخاص بك (يمكن أن يكون Huggingface AutoModel أو ModelScope AutoModel) إلينا، إلى جانب نصوص التقييم المخصصة الخاصة بك. يمكن تعديل البرامج النصية المخصصة الخاصة بك من البرامج النصية للقالب التي تعمل مع LLaVA-v1.5 (لـ A1/A2)، وهنا (لتقييم جودة الصورة).
يرجى إرسال بريد إلكتروني إلى [email protected] لإرسال النموذج الخاص بك إذا كنت خارج البر الرئيسي للصين. يرجى إرسال بريد إلكتروني إلى [email protected] لإرسال النموذج الخاص بك إذا كنت داخل البر الرئيسي للصين.
فيما يلي لقطة لمجموعة البيانات المعيارية LLVisionQA لقدرة الإدراك ذات المستوى المنخفض MLLM. انظر المتصدرين هنا.
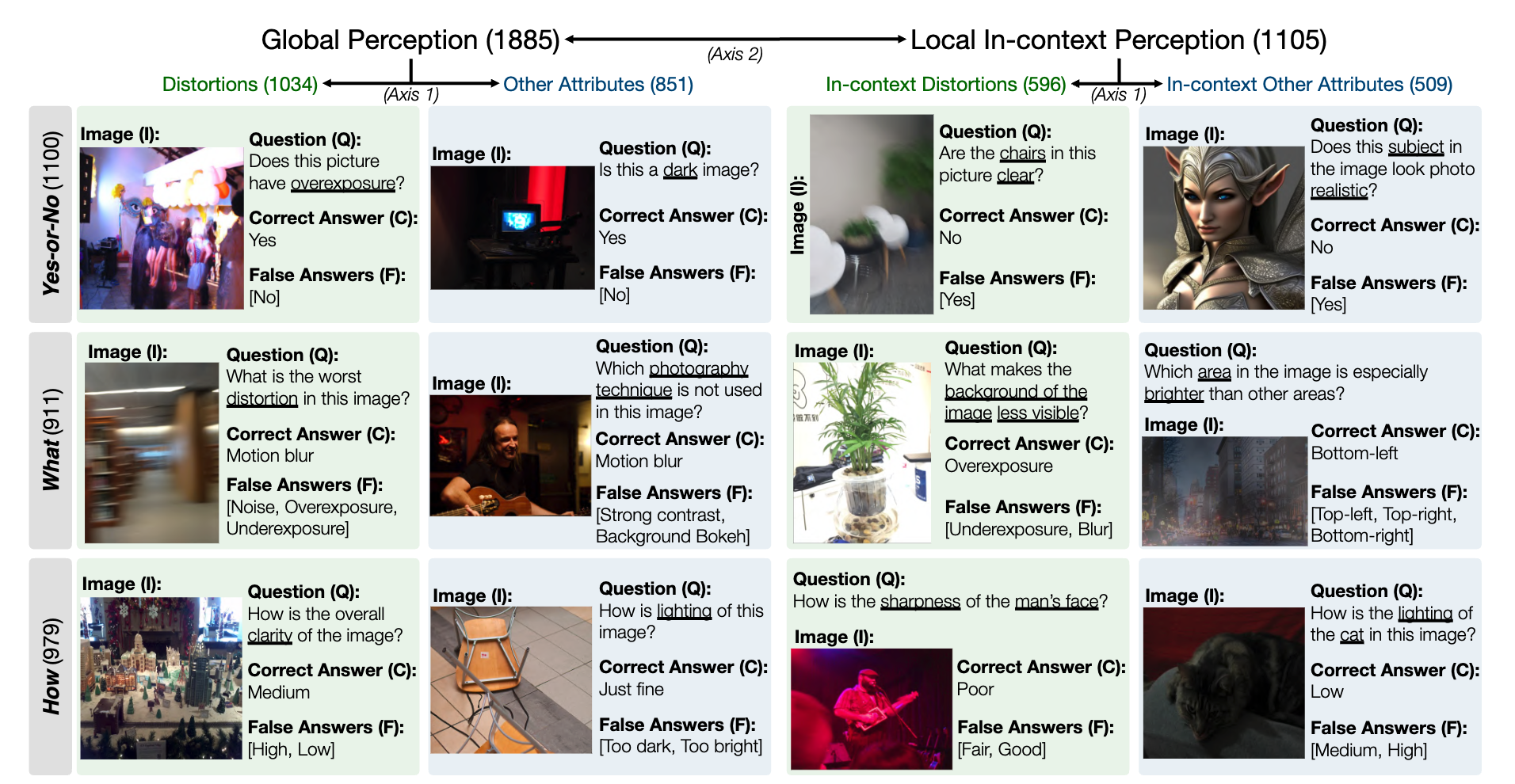
نحن نقيس دقة إجابة MLLMs (المزودة بالسؤال وجميع الاختيارات) كمقياس هنا.
لقطة لمجموعة البيانات المعيارية LLDescribe لقدرة الوصف ذات المستوى المنخفض MLLM هي كما يلي. انظر المتصدرين هنا.

نحن نقيس مدى اكتمال ودقة وملاءمة أوصاف MLLM كمقياس هنا.
قدرة مثيرة أن MLLMs قادرة على التنبؤ بالنتائج الكمية لـ IQA!
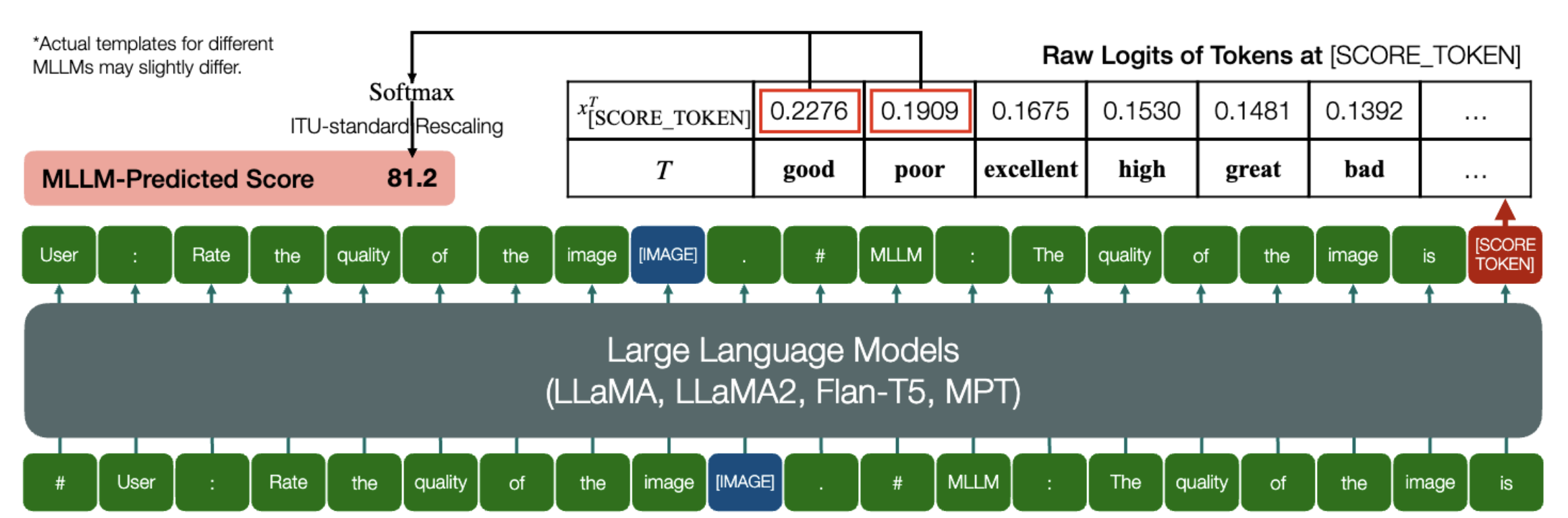
وبالمثل كما هو مذكور أعلاه، طالما أن النموذج (المعتمد على نماذج اللغة السببية) يحتوي على الطريقتين التاليتين: embed_image_and_text (للسماح بمدخلات متعددة الوسائط)، وإعادة forward (لسجلات الحوسبة)، وتقييم جودة الصورة (IQA) مع النموذج يمكن تحقيقها على النحو التالي:
من PIL import Imagefrom my_mllm_model import Model, Tokenizer, embed_image_and_textmodel, tokenizer = Model(), Tokenizer()prompt = "##المستخدم: تقييم جودة الصورة.n"
"##Assistant: جودة الصورة" ### يمكن تعديل هذا السطر بناءً على السلوك الافتراضي لـ MLLM. open("image_for_iqa.jpg")input_embeds = embed_image_and_text(image, موجه)output_logits = model(input_embeds=input_embeds).logits[0,-1]q_pred = (output_logits[[good_idx, Poor_idx]] / 100).softmax(0)[0]*لاحظ أنه يمكنك تعديل السطر الثاني بناءً على التنسيق الافتراضي للنموذج الخاص بك، على سبيل المثال بالنسبة لـ Shikra، يتم تعديل "##Assistant: جودة الصورة" إلى "##Assistant: الإجابة هي". لا بأس إذا كانت MLLM الخاصة بك ستجيب أولاً "حسنًا، أود المساعدة! جودة الصورة هي"، فقط استبدل هذا في السطر 2 من المطالبة.
نحن نقدم كذلك التنفيذ الكامل لـ IDEFICS على IQA. انظر المثال حول كيفية تشغيل IQA باستخدام MLLM. يمكن أيضًا تعديل MLLMs الأخرى بنفس الطريقة لاستخدامها في IQA.
لقد قمنا بإعداد درجات الرأي البشري بتنسيق JSON (MOS) لقواعد بيانات IQA السبعة كما تم تقييمها في معيارنا المعياري.
يرجى مراجعة IQA_databases للحصول على التفاصيل.
تم النقل إلى المتصدرين. الرجاء الضغط لرؤية التفاصيل.
يرجى الاتصال بأي من المؤلفين الأوائل لهذه الورقة للاستفسارات.
هاونينغ وو، [email protected] ، @teowu
زيتشنغ تشانغ، [email protected] ، @zzc-1998
إيرلي تشانغ، [email protected] ، @ZhangErliCarl
إذا وجدت أن عملنا مثير للاهتمام، فلا تتردد في الاستشهاد بمقالتنا:
@inproceedings{wu2024qbench,author = {Wu, Haoning and Zhang, Zicheng and Zhang, Erli and Chen, Chaofeng and Liao, Liang and Wang, Annan and Li, Chunyi and Sun, Wenxiu and Yan, Qiong and Zhai, Guangtao and Lin, Weisi},title = {Q-Bench: معيار لنماذج الأساس ذات الأغراض العامة على المستوى المنخفض الرؤية}، عنوان الكتاب = {ICLR}، السنة = {2024}} 

